-
-
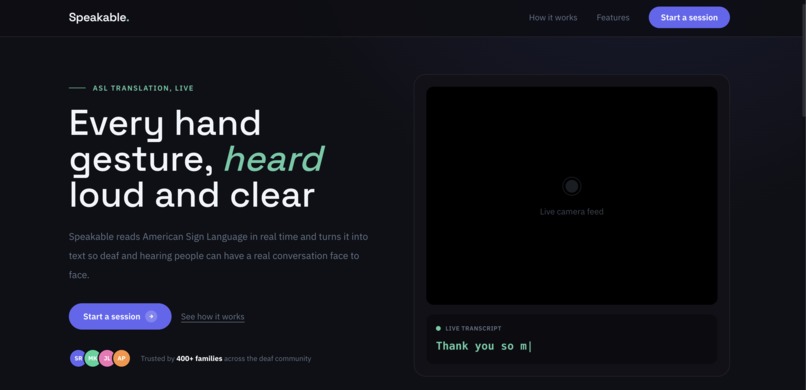
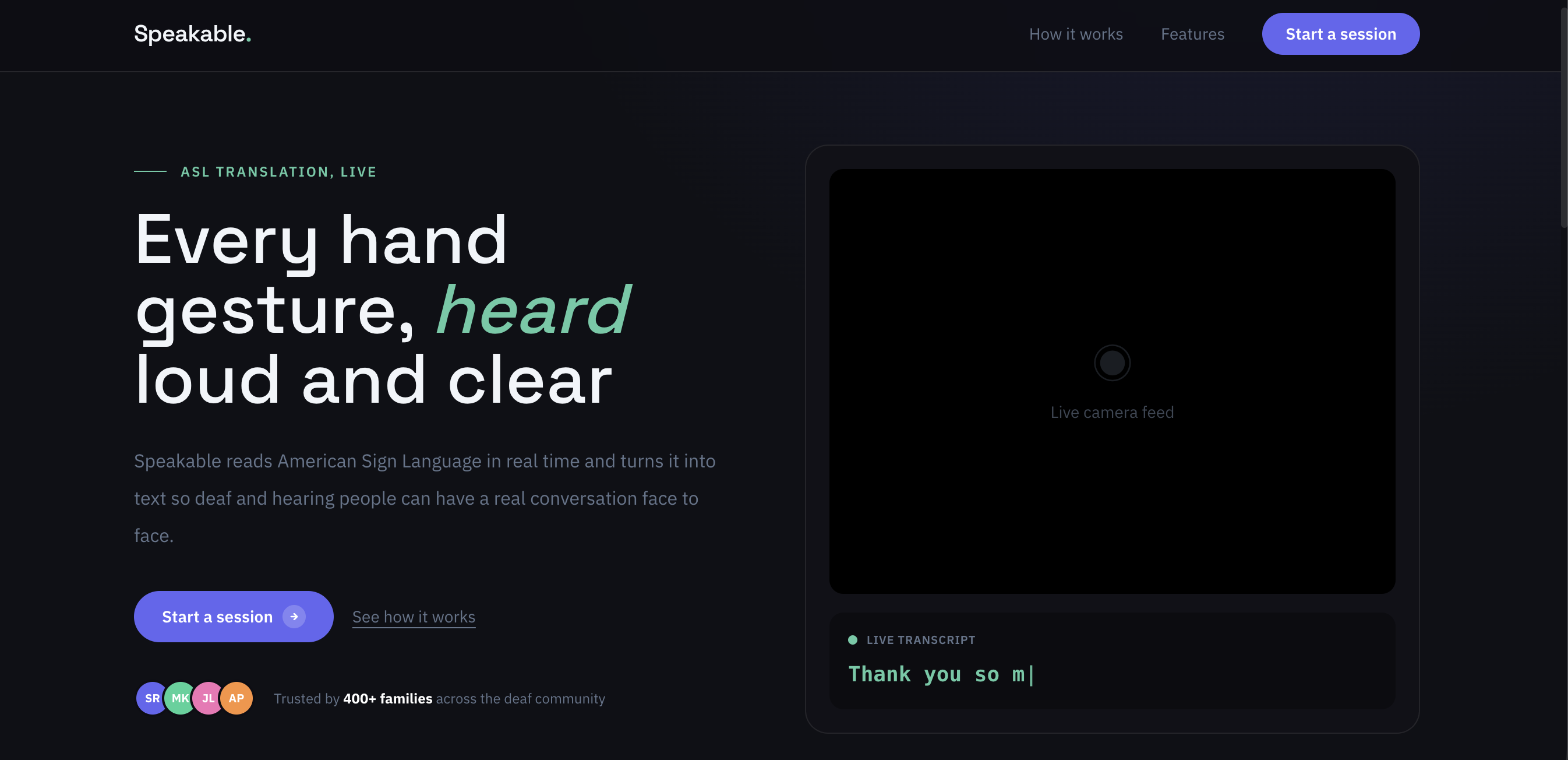
Home Page
-

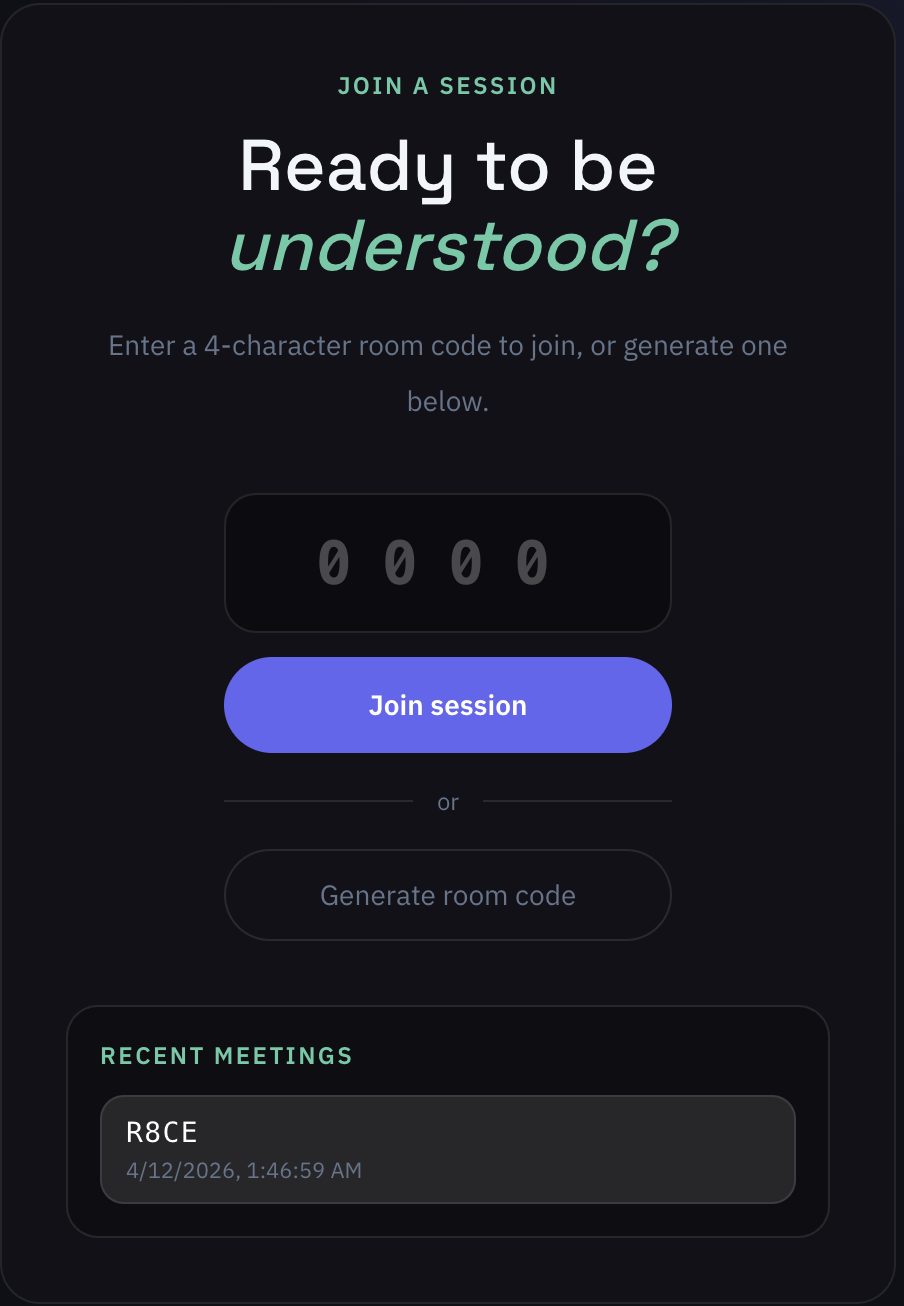
Join/Create Room Page
-
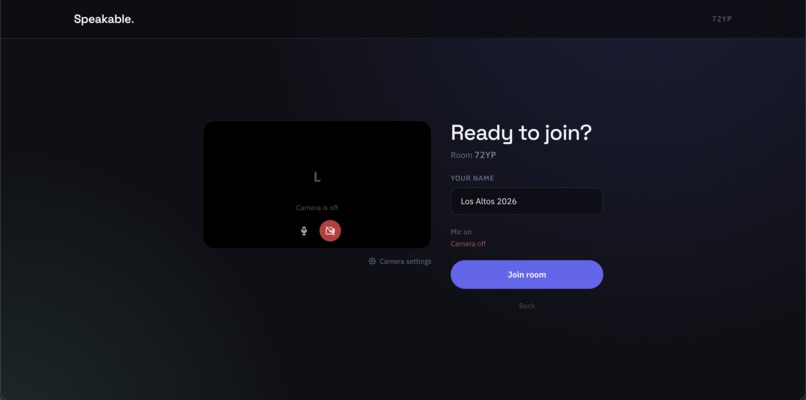
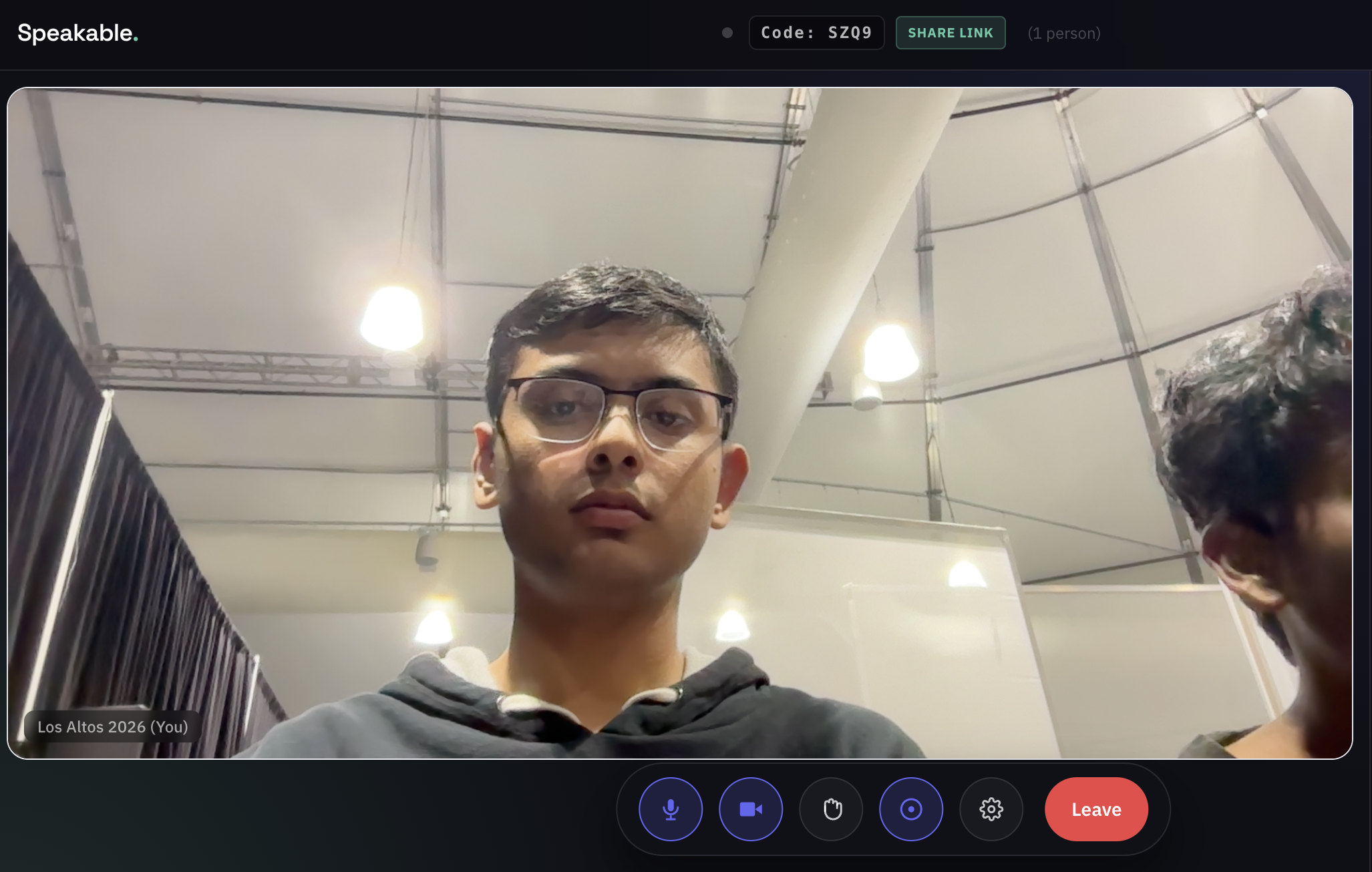
Prepare to Join
-
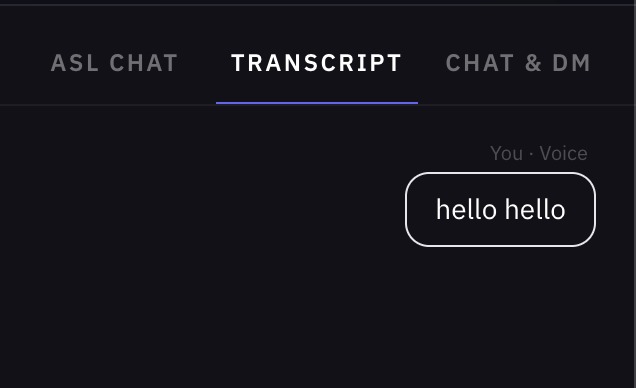
Many Ways to Communicate
-
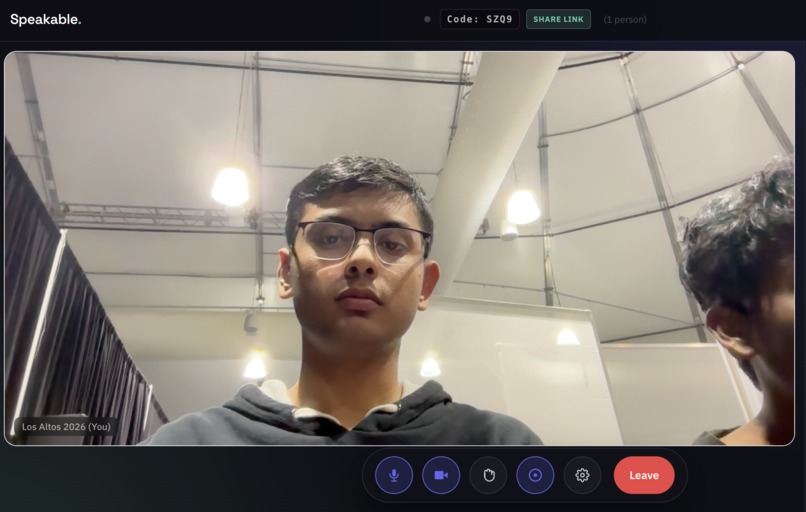
Familiar Calling Feel
-
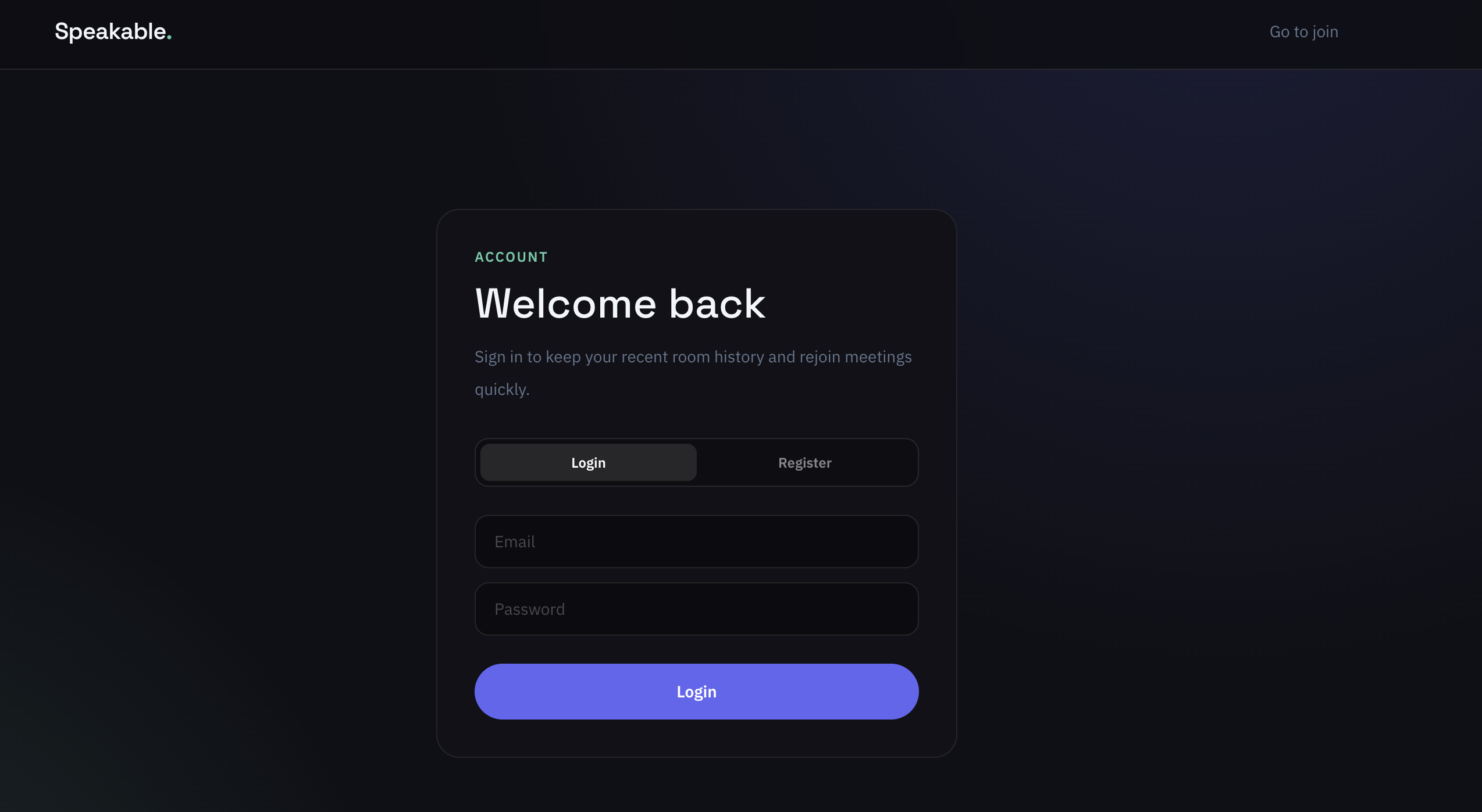
Sign up and never lose a beat
-
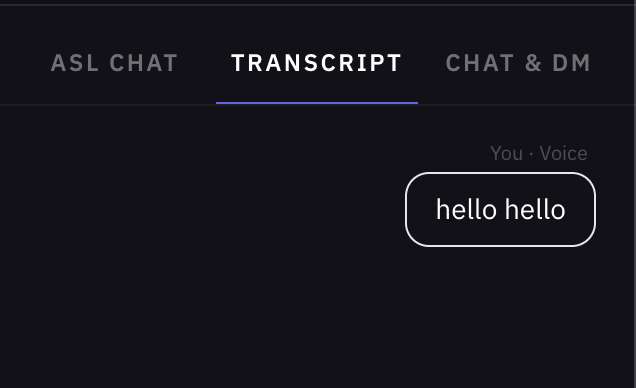
View your recent meetings

Inspiration
The practical issue of communication difficulties, especially when it comes to hearing- and speech-impaired individuals, becomes the starting point for developing the Speakable application. The common problem of being unable to communicate effectively or understand others, relying on writing out notes or losing track of conversations altogether, made us realize that the solution can be found with the help of technology. Hence, the application was designed using such capabilities as text-to-speech translation, speech-to-text transcription, and friendly interfaces for users, which allows for an easier way to interact and communicate.
What it does
Speakable facilitates the conversation between deaf and hearing individuals. The deaf individual signs their message to the camera, and our unique AI algorithm processes the signing in real time to produce text. This text is processed to form grammatically correct sentences by means of the LLM algorithm and then translated into speech using text-to-speech via the ElevenLabs API. The hearing individual responds vocally, and the ElevenLabs API transcribes the response back into text for the deaf individual to read.
How we built it
We first developed a custom model to perform ASL recognition locally, where we used MediaPipe to detect hand landmarks, which were then provided to the RandomForest classifier. Our initial test code proved that we can do low-latency letter detection from a live camera feed.
Once we had the basic communication in place, we added real-time communication between two people, where each person had a live camera feed. In the next step, we integrated the transcript pipeline, which involved buffering raw detected letters and sending them to the LLM using OpenRouter to autocorrect and create complete sentences.
Now that we had our backend ready, we turned our attention to the frontend, which included developing a neat, animated landing page and user interface for the ongoing session. The most challenging part of this project was to deploy our backend since MediaPipe needs OpenGL installed system-wide, and no popular cloud provider has it installed by default.
Our RandomForest classifier was also retrained in the cloud via Google Colab, using an extensive data set—a considerable increase in the number of data sets from around 1,600 to tens of thousands, thus greatly increasing the accuracy of the identification process. Lastly, we utilized the ElevenLabs API to render the optimized text as speech.
Challenges we ran into
The installation of the backend turned out to be our most significant headache. MediaPipe needs OpenGL ES system libraries (libGLESv2) at the operating system level, which is something that none of the top cloud providers pre-installs. We tried different services like Railway, Render, and Fly.io, using different approaches ranging from custom install scripts to apt-get commands and even declaring packages in Render.yaml but only succeeded in fixing it by creating a custom Dockerfile. In terms of the frontend, we encountered problems due to different environments on Vercel and Railway where codes that work seamlessly locally fail when deployed, especially those dealing with environment variables.
Another issue was the poor quality of training data used. Our first model was trained with only 1,619 instances, not due to a lack of data, but because MediaPipe could detect hands in most pictures due to inconsistent lighting and backgrounds. In real-life use, this resulted in noisy, redundant results that caused an overflow of the transcript with junk symbols, repeats, and even whole unnecessary words. To solve the problem, we decided to replace the training set for a better one and move the training process onto Google Colab with tens of thousands of instances. Additionally, we added confidence threshold adjustment, repeat symbol removal, and correct control token treatment, such as DEL, SPACE, and NOTHING.
Creating a reliable peer-to-peer WebRTC connection was challenging because of problems like dealing with ICE candidate generation, timing the offer-answer exchange, and synchronizing media states. The slightest problem in timing would result in one-sided connections or black screens on the video feed. It was also important for us to synchronize ASL recognition events between the worker loop and the front end.
The integration of ElevenLabs’ TTS also came with some challenges of its own. We had to switch our TTS calls to run on the server side to prevent API credentials from being sent to the browser, develop our own proxy route on the front end to ensure reliability, and process the text input before synthesis to make sure all of the symbols and abbreviations in the ASL string were vocalizable.
Rebuilding the UI in React and Next.js—rather than using plain HTML—required careful attention to preserve all existing functionality across the landing, join, lobby, and room screens. Next.js App Router constraints around search params and Suspense boundaries introduced subtle bugs in the join flow. Keeping participant naming, real-time transcript updates, and ASL toggle state consistent across all screens through multiple rounds of changes took significant iteration. A full product rename from Talkable to Speakable also had to be propagated cleanly across source files, package metadata, and documentation without missing anything.
Throughout everything, we were simultaneously managing frontend, backend, real-time communication, AI inference, TTS, and deployment—all in one continuous sprint without breaking the core call flow.
Accomplishments that we're proud of
What we achieved in a hackathon sprint to build a full-fledged communication tool is something we are quite proud of. We began by wondering whether we could build a tool that would detect ASL in near real-time and output spoken words. We are really happy that our tool allows two people to have a genuine conversation through ASL detection and synthesis.
Another thing we are proud of is the manner in which we overcame adversity. There were several difficulties with the development process. For instance, we had problems with the size of our model, the fact that some libraries weren't available for our deployment platform, the need to secure our TTS credentials server-side, and the need to set up a permanent WebRTC connection. We managed to overcome all of these challenges. It was especially gratifying when we were able to retrain our model on several tens of thousands of samples and see how the accuracy increased mid-hackathon.
Lastly, we can boast about our interface. Tools for accessibility are usually efficient but not aesthetically pleasing. We aimed to create a product that was good to use and visually appealing and believe we succeeded in doing so with Speakable.
What we learned
We found out that deploying ML-backed services is fundamentally different from deploying regular web applications. Dependencies at the system level, such as OpenGL, do not appear in requirement.txt files, which makes the process unpredictable and hard to debug. We found that using Docker for this type of stack is not negotiable. It is the only way to ensure that your environment will be consistent across different platforms.
We discovered the importance of data quality over data quantity when training our model. While the first dataset we worked on was abundant in images, we could hardly use most of them due to the inability of MediaPipe to recognize hand movements in the images.
In terms of product development, we understood how much thought goes into building an accessible product. Each decision—be it about when to refresh the transcript, handling of silence, or when to perform sentence reconstruction—was crucial in determining how natural or frustrating the user’s experience would be. We had to rethink our approach to communication in order to build something that would cater to people who are deaf.
In addition to product development experience, we got an opportunity to get firsthand experience with signaling in WebRTC, extraction of hand landmarks using MediaPipe, and TTS proxy architecture.
What's next for Speakable
The first step should be developing ASL recognition capabilities beyond the alphabet. The current iteration recognizes letters, but many fluent signers communicate in words and phrases that are more convenient to recognize in full. Training an AI to recognize words and phrases used in common ASL conversations will significantly enhance the application's usefulness for the deaf community.
Another enhancement idea worth pursuing is making Speakable mobile. Conversations are not necessarily confined to a fixed space; therefore, a version optimized for mobile devices would allow people to use the tool more conveniently, for example, at work interviews or when buying products in the store.
As far as AI development is concerned, we need to replace OpenRouter with a fine-tuned ASL-to-English reconstruction solution to speed up, simplify, and improve sentence correction processes.
A long-term goal of our project could be creating additional support options for BSL, Auslan, and ISL to expand Speakable's usability across the world. Another potential development would be incorporating a function to save conversation history for legal, medical, or any other purposes.
Built With
- elevenlabs
- flask
- flask-socketio
- framer-motion
- google-colab
- gunicorn
- html/css
- javascript
- mangodb
- mediapipe
- next.js
- node.js
- numpy
- opencv
- openrouter
- palantir-coding-tools
- python
- railway
- react
- scikit-learn
- tailwind
- typescript
- vercel
- webrtc




Log in or sign up for Devpost to join the conversation.