-
-
Architecture
-
Landing Page
-

5 English Characters, 5 Non-English Characters
-

Mode Selection Screen
-
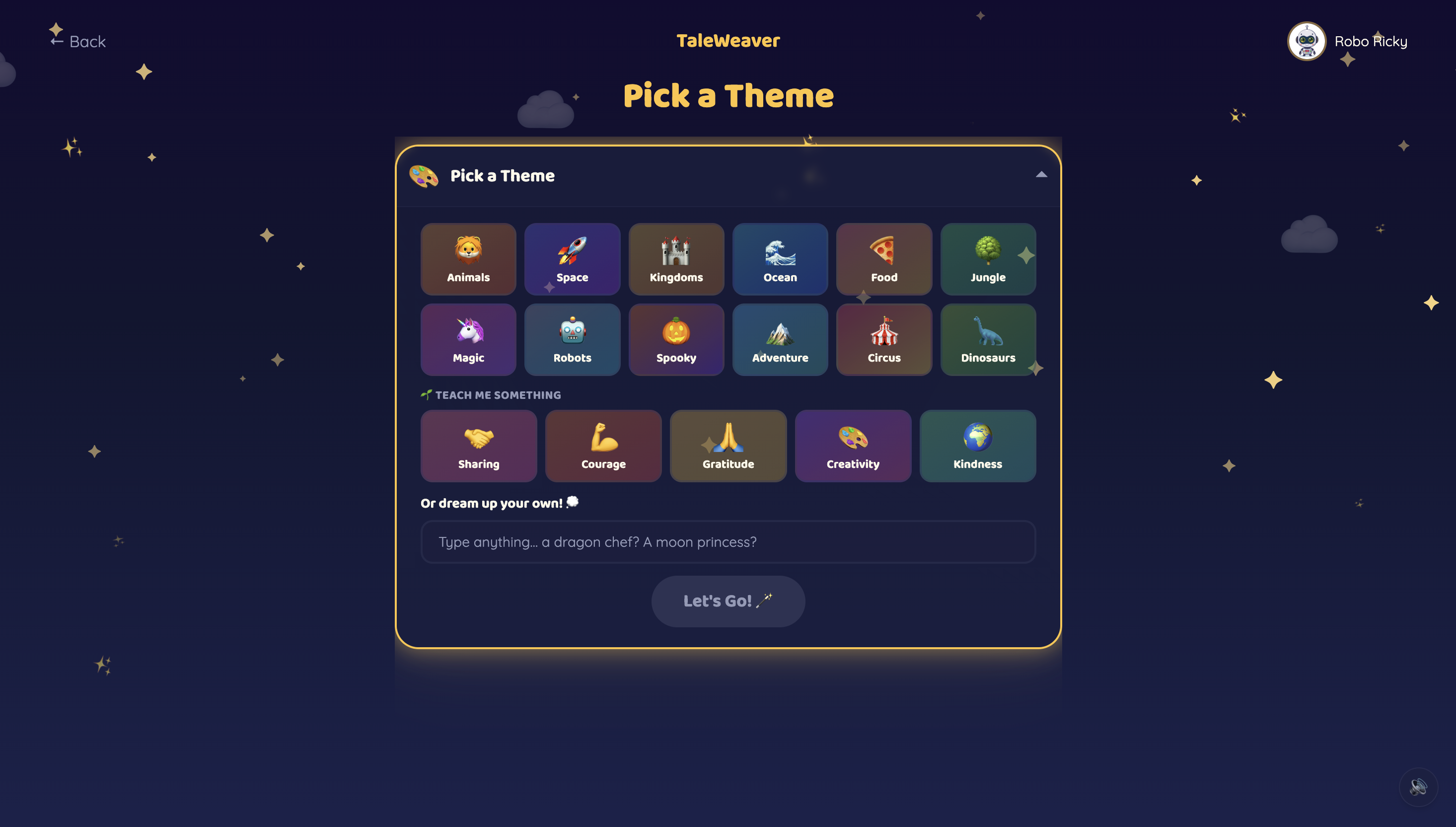
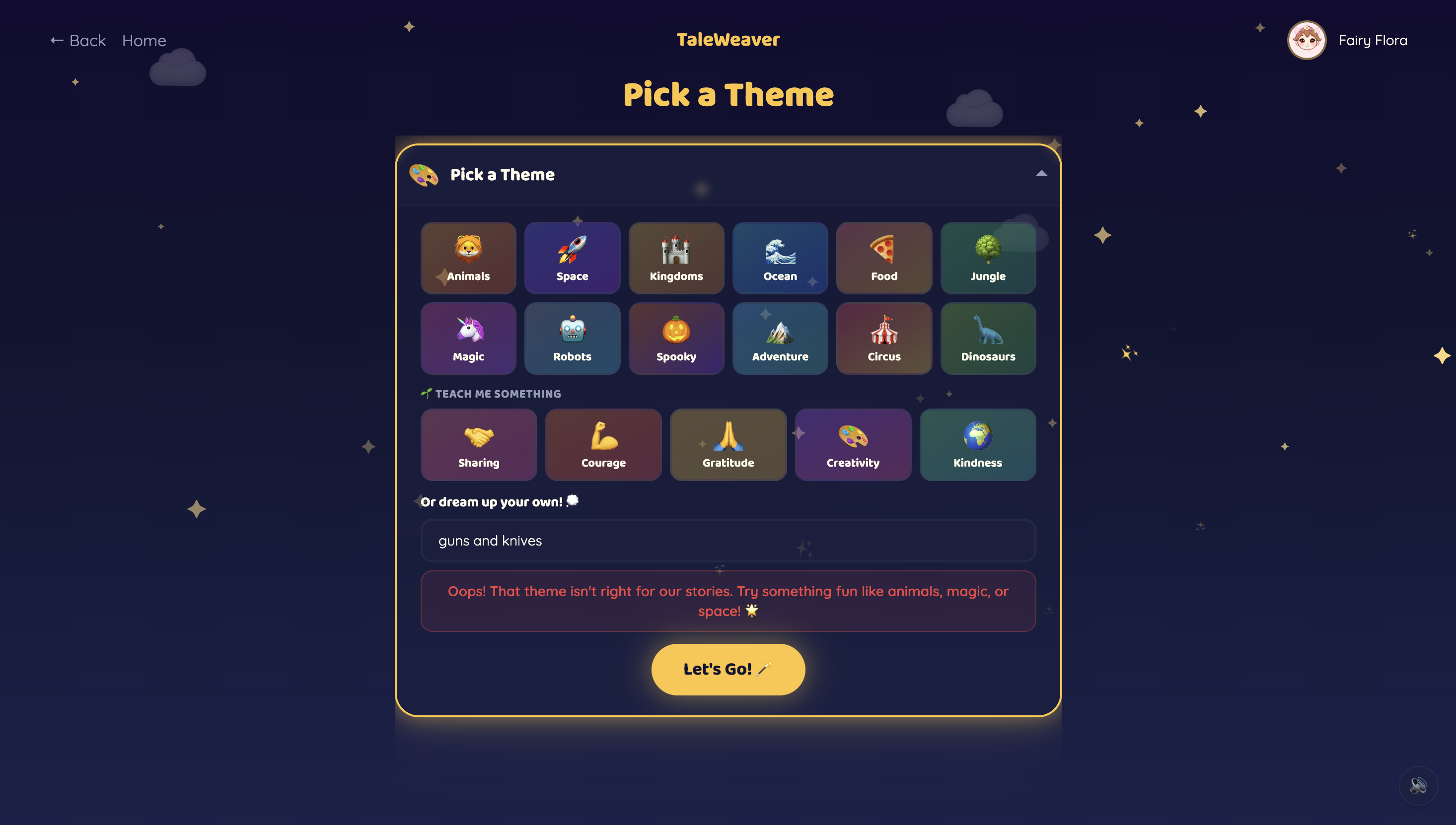
Theme Selection
-
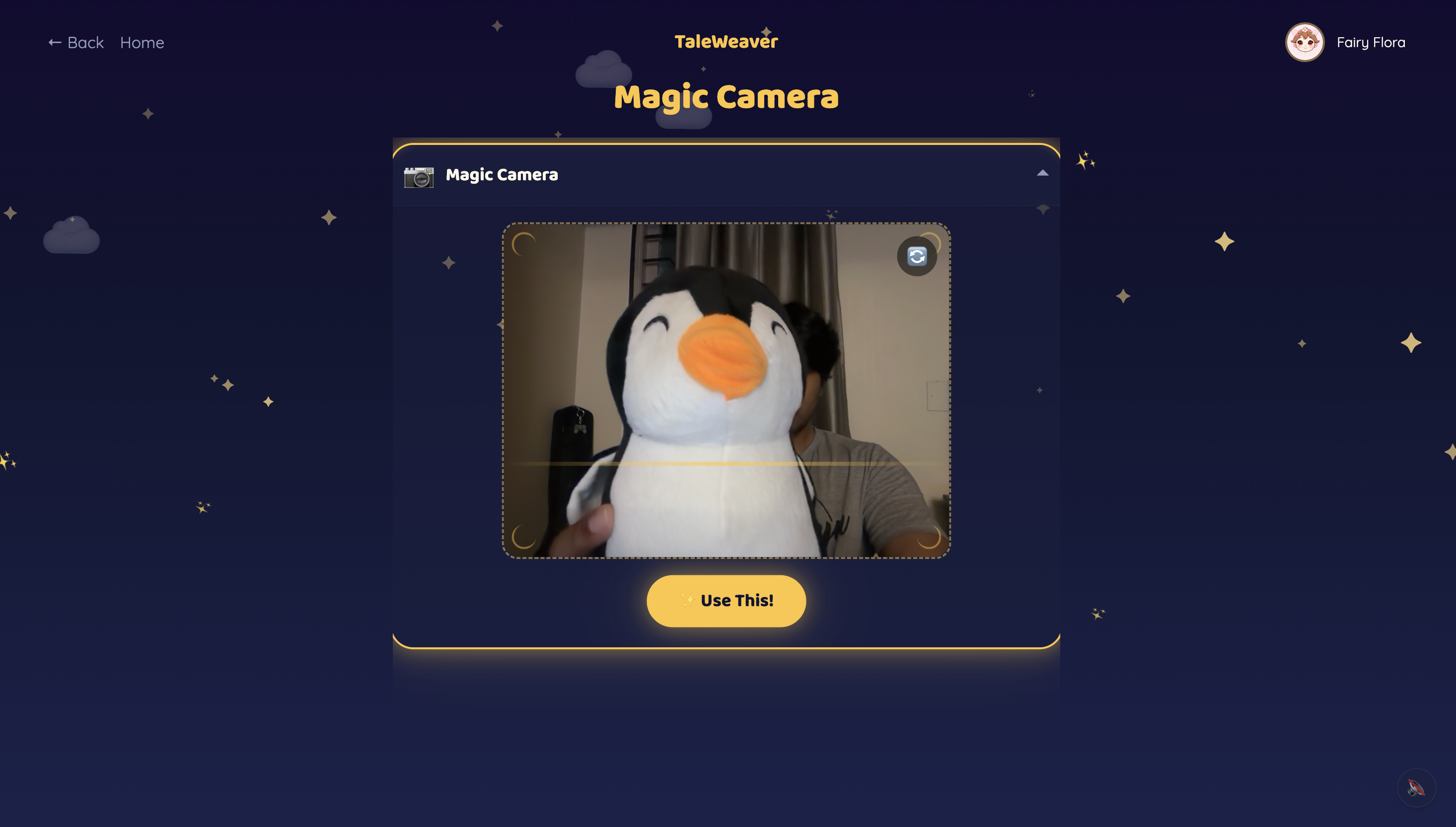
Magic Camera Photo
-
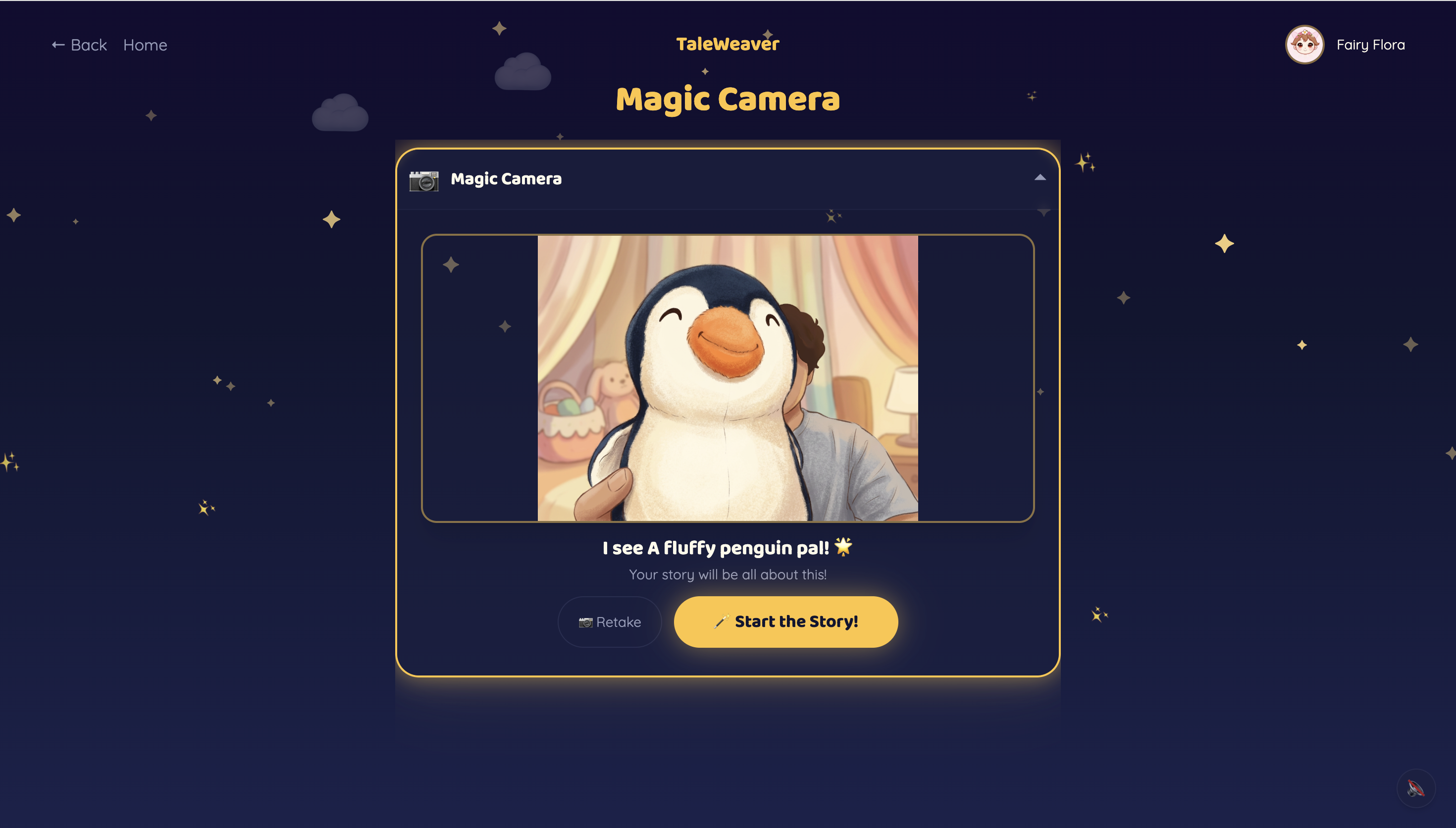
Magic Camera Identification
-
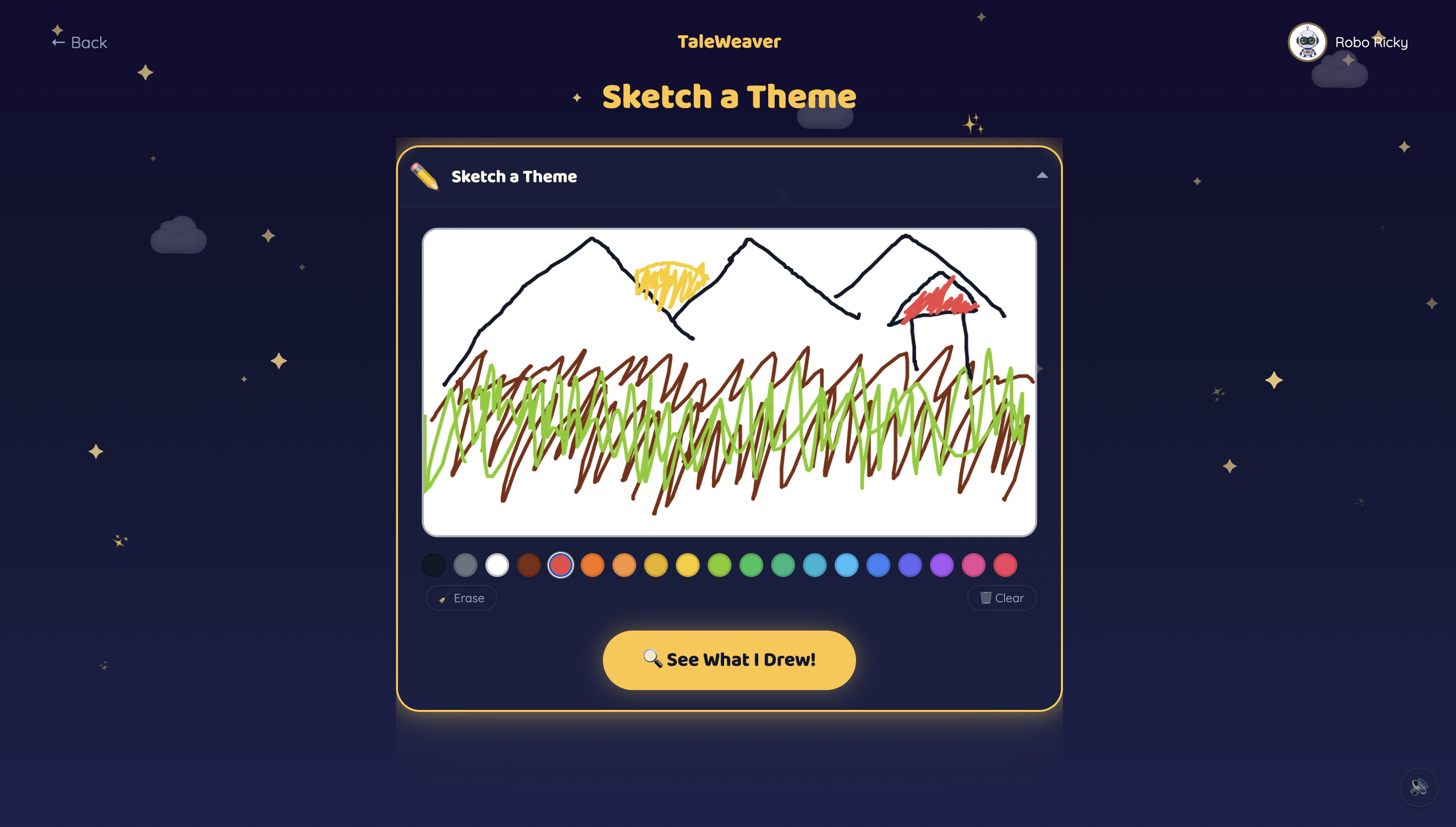
Sketch
-
Sketch Identification
-
Safety Filter In Action
-
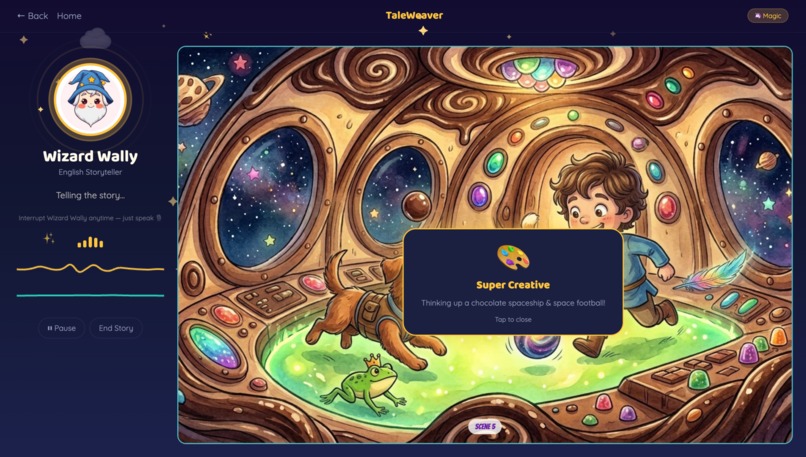
Creativity Badge Awared
-
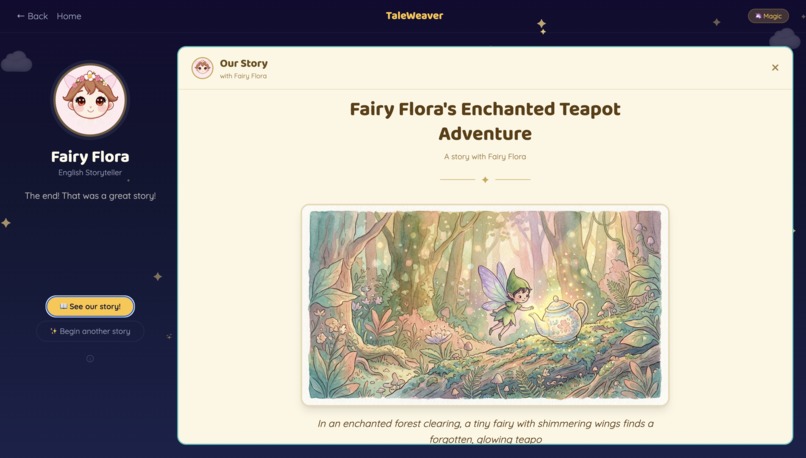
Story Recap





The Idea
Every child is a natural storyteller. Ask a five-year-old what happens next and they'll tell you — without hesitation — a story full of dragons and cloud-beds and candy castles. The problem is that most "interactive" storytelling for kids is still one-way: a book reads to you, an app plays a video, a voice assistant answers a question.
None of them listen back.
TaleWeaver changes that. For the first time, a child can interrupt the story mid-sentence — the way they do with a real parent at bedtime — and have the AI weave their words into the next beat without breaking stride. Add real-time image generation and what you get isn't a chatbot with a story skin. It's a living, illustrated adventure that the child is genuinely co-authoring.
TaleWeaver is that experience. Built for kids. No reading required. No typing. Just talk.

How It Works
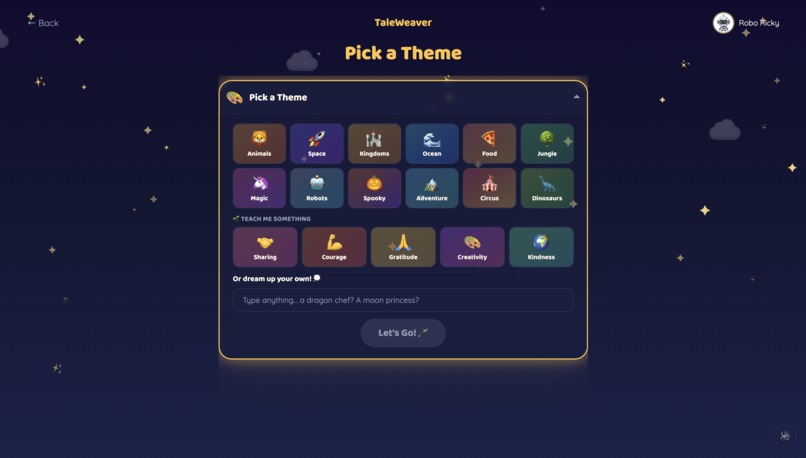
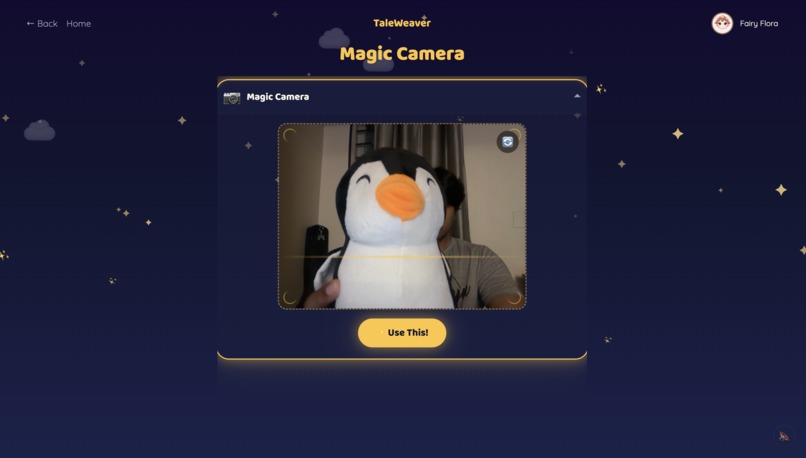
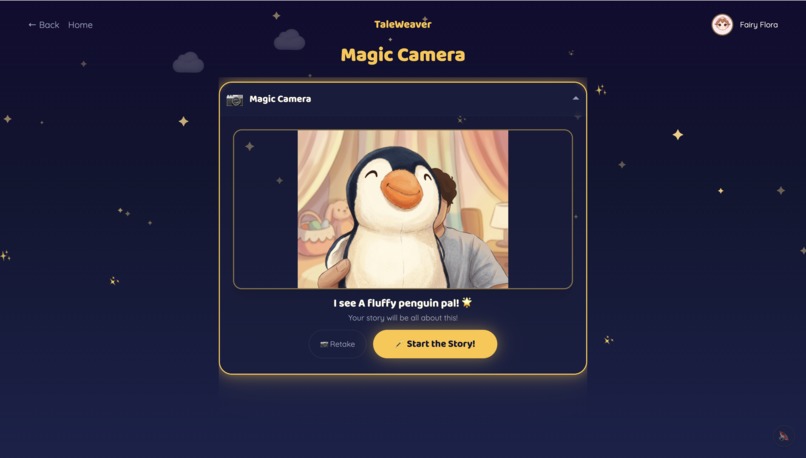
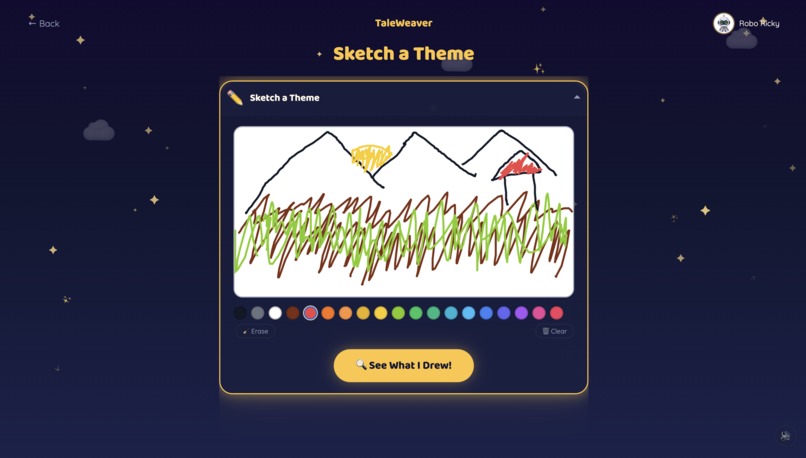
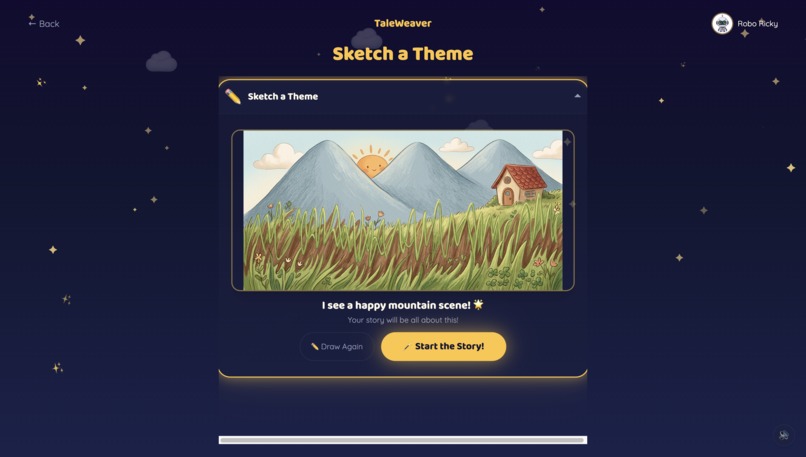
Children pick from 10 storyteller characters — 5 English storytellers and 5 world-language storytellers (Hindi, Tamil, Mandarin, Spanish, French) — each with a distinct voice and personality. The world-language characters are designed to showcase what Gemini's multilingual capabilities make possible. They start a story one of three ways: pick a theme, hold up a toy to the Magic Camera, or draw a Sketch. Gemini identifies the object or drawing and makes it the hero.
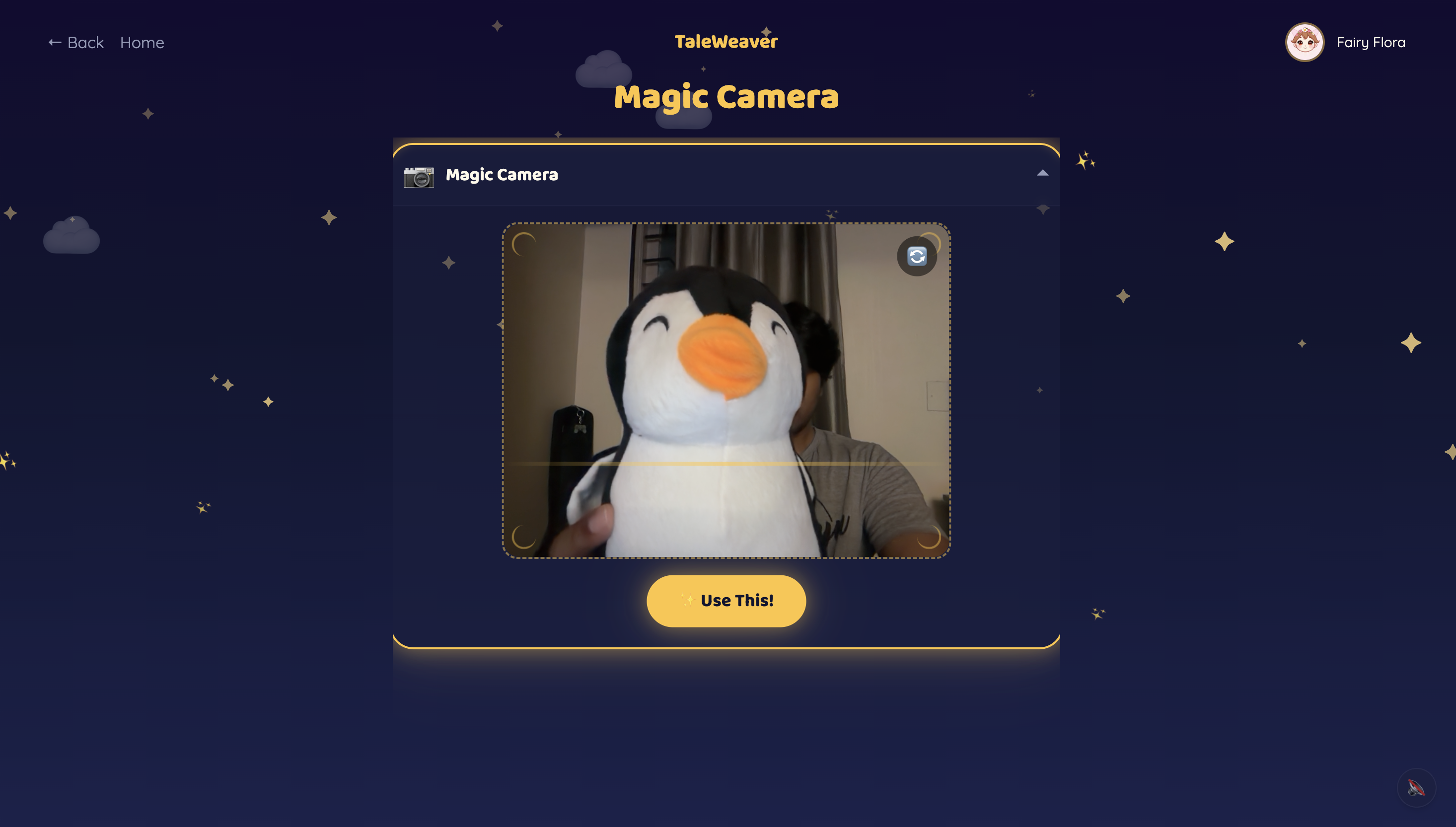
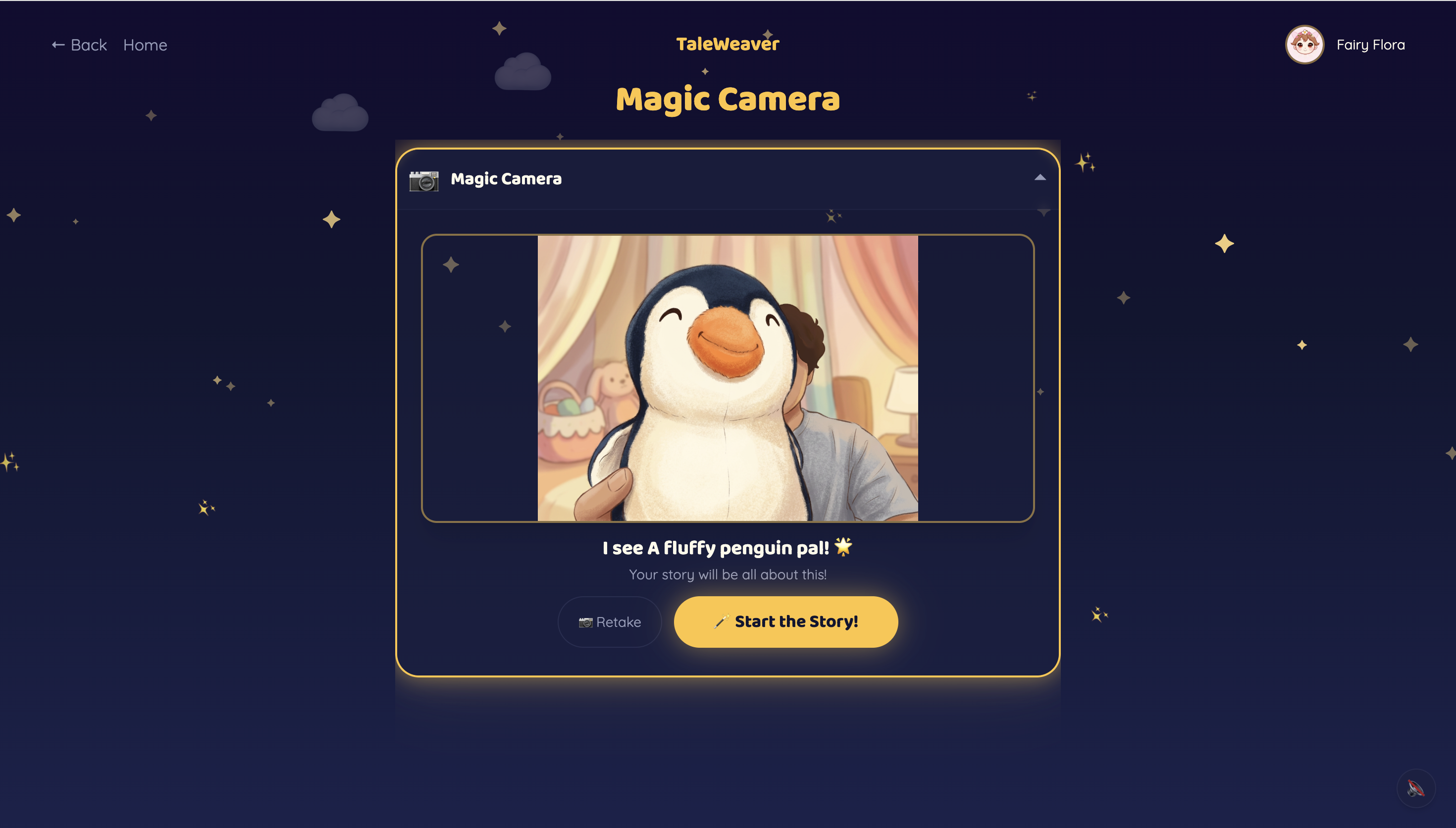
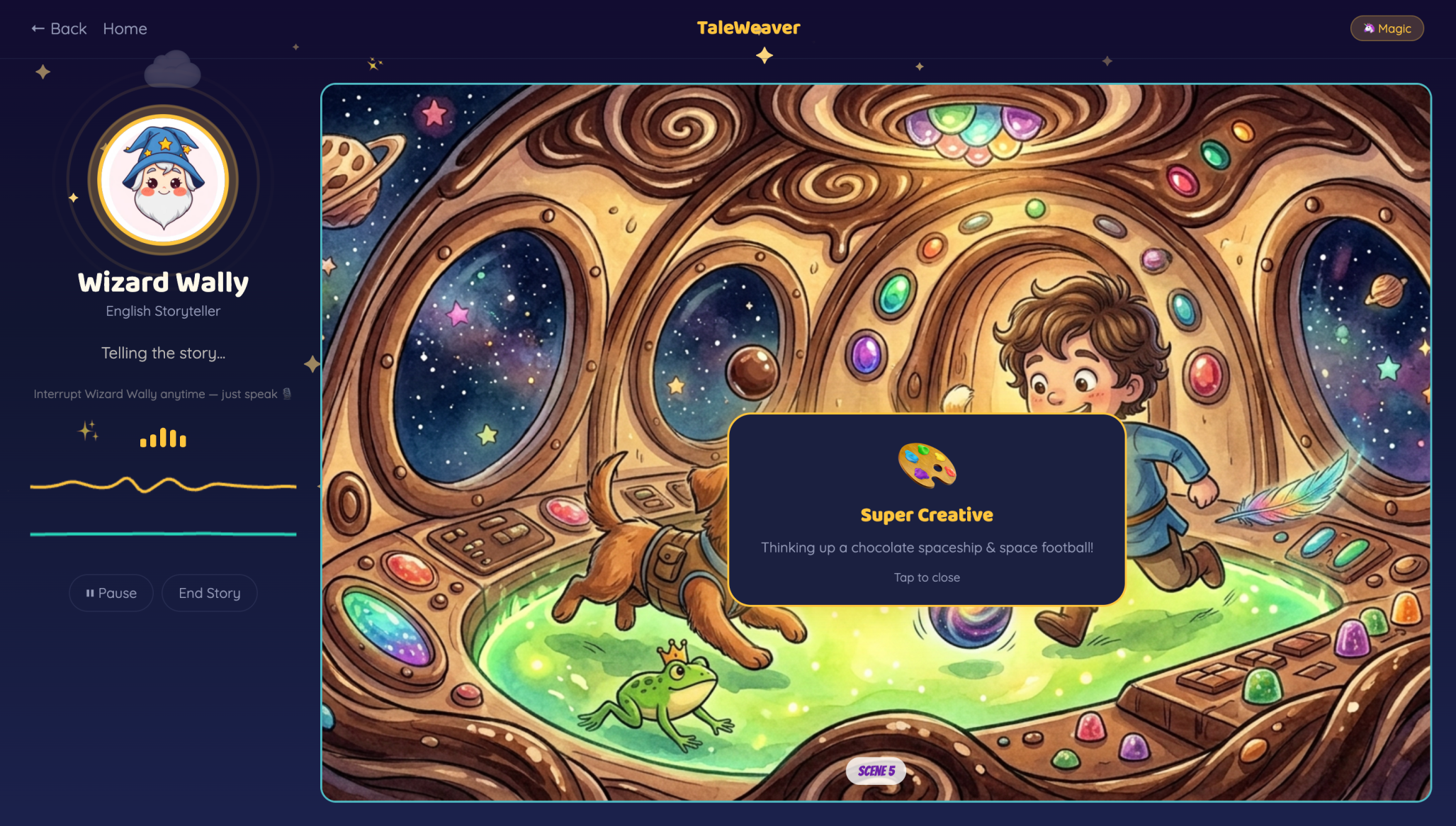
Once the story begins, gemini-live-2.5-flash-native-audio takes over as the agent — narrating, listening for barge-in, and autonomously calling two tools: generate_illustration when a visual moment lands, and award_badge when the child contributes something genuinely imaginative.
AI: The ant, the ladybug, and the fairy were tired after their long journey...
Child: Make a cloud their bed!
AI: And just like that, a soft fluffy cloud floated down,
curling around them like the cosiest bed in the world!
Illustrations appear as the story unfolds — Gemini writes its own scene description and each new image is generated with the previous one as context, keeping characters and art style visually consistent across every scene.
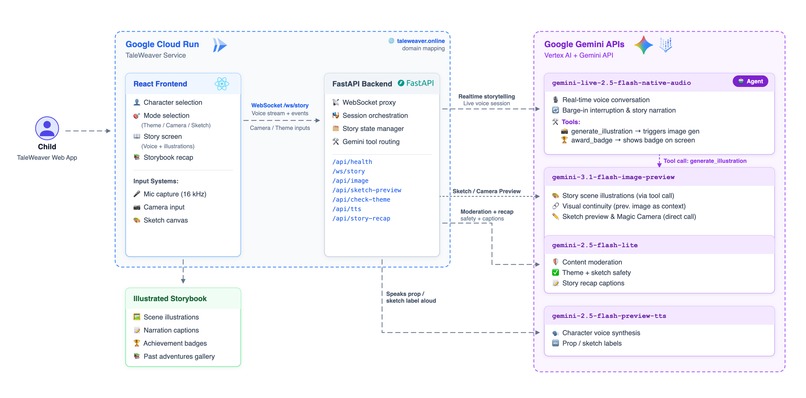
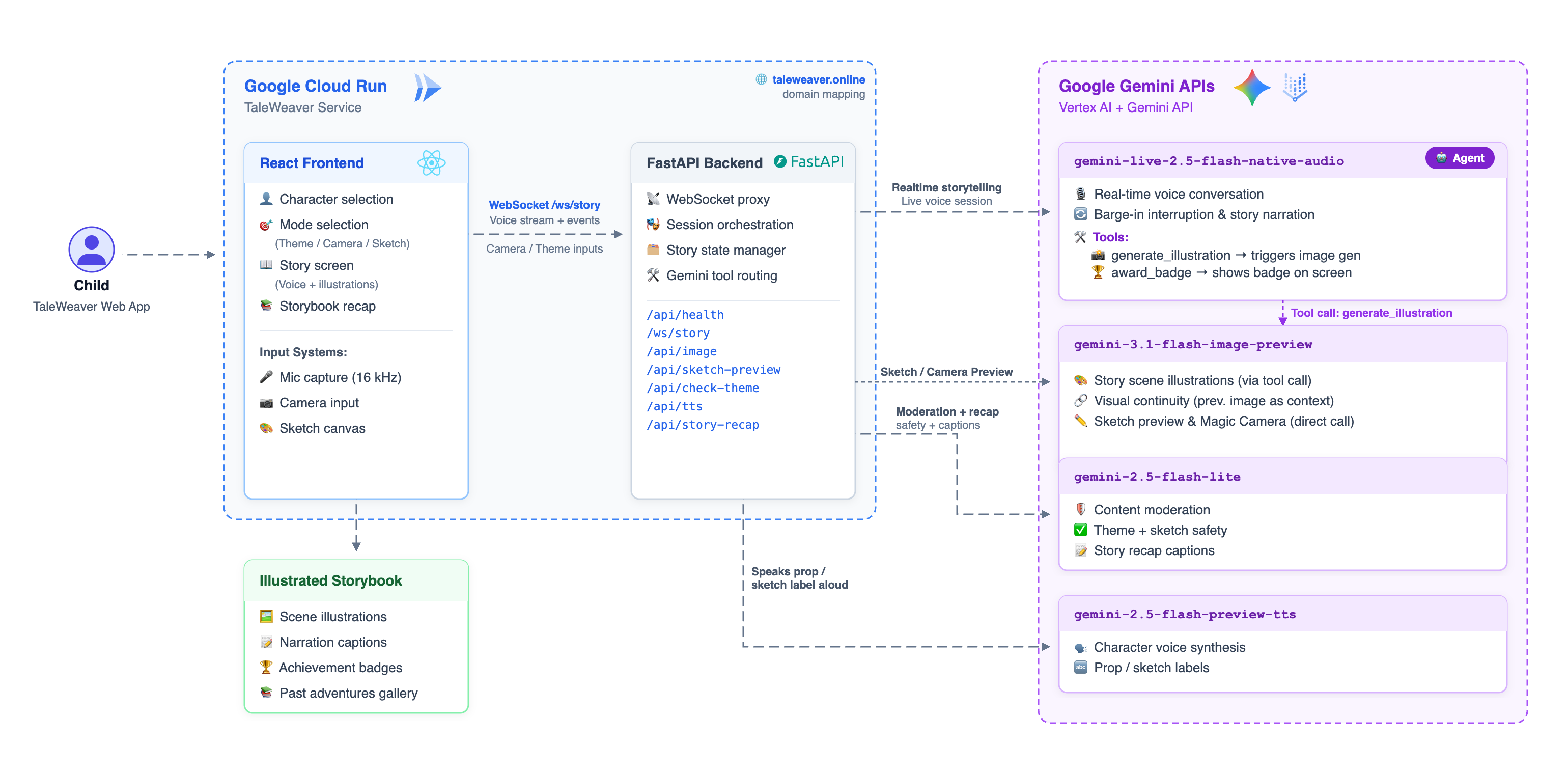
The Architecture
Four Gemini models, each with a distinct job:
| Model | Used For |
|---|---|
gemini-live-2.5-flash-native-audio |
Real-time voice conversation, barge-in, autonomous tool calls — the Agent |
gemini-3.1-flash-image-preview (Nano Banana 2) |
Scene illustration generation |
gemini-2.5-flash-preview-tts |
Character voice for prop and sketch labels |
gemini-2.5-flash-lite |
Content moderation + storybook recap |
The backend is a WebSocket proxy that sits between the browser and Gemini Live — handling GCP authentication, injecting character system prompts, routing tool calls, and synchronising session start.
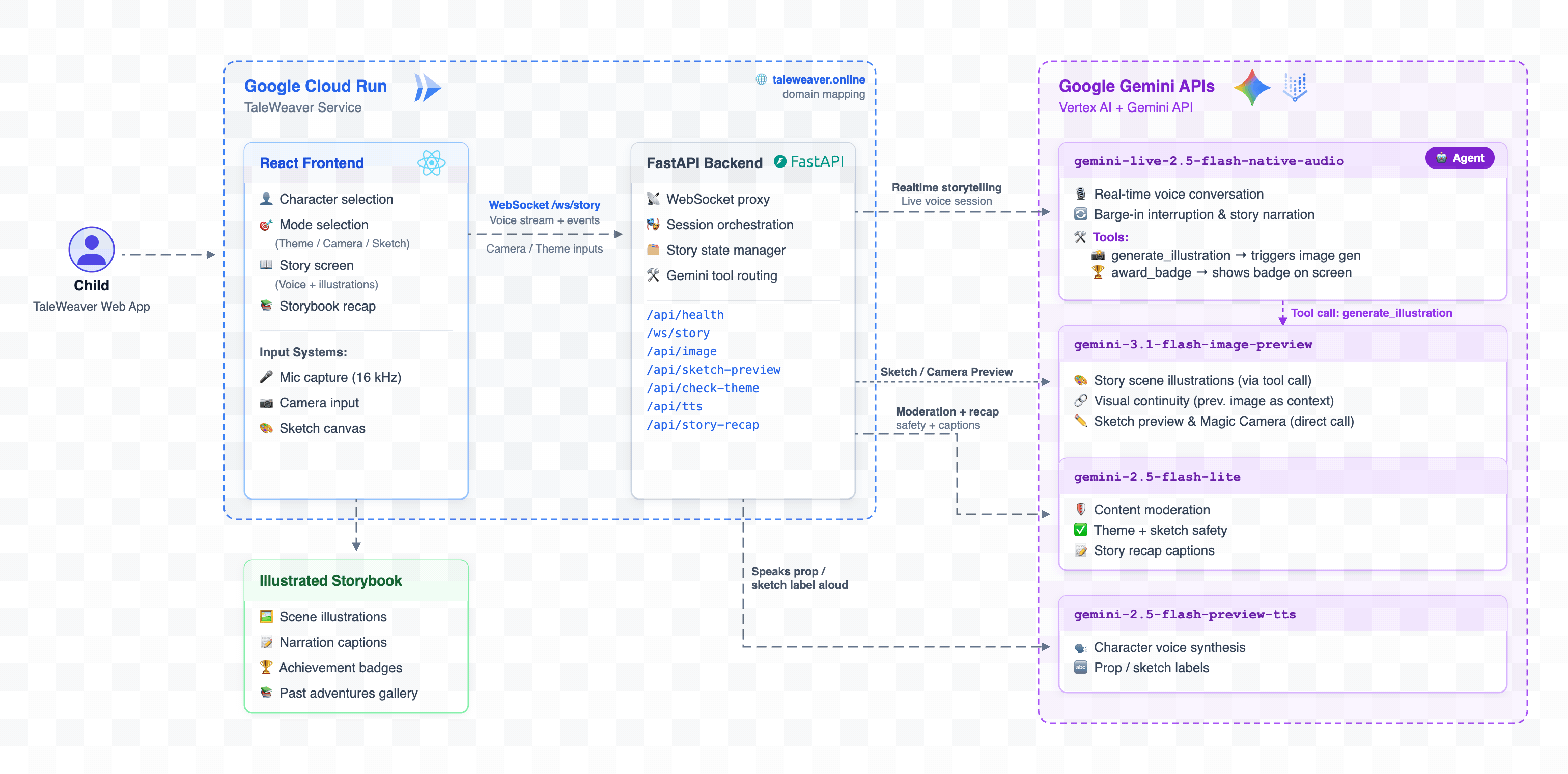
Deployed as a single Cloud Run service: Node 22 compiles the React 18 frontend, Python 3.13 FastAPI serves both the API and static files. Push to main → Cloud Build → Artifact Registry → Cloud Run.
What We're Proud Of
Interleaved storytelling. Voice narration and image generation run in parallel inside a single Gemini Live session. During narration the agent calls generate_illustration, allowing illustrations to appear while the story continues. The narrative never pauses for visuals.
Illustrations generated from the story itself. Gemini chooses the visual moment, writes the scene description, and generates the illustration from the narration. Each image references the previous one so the art style stays consistent across the entire story.
Natural voice interruption. A child can interrupt mid-sentence and introduce a new idea. The storyteller immediately absorbs it and continues the narrative, turning the child into an active co-creator of the story.
Real-time creativity recognition. When a child contributes an imaginative idea such as a unique character or unexpected twist, Gemini awards a creativity badge instantly. The feedback arrives in the moment the idea appears.
Creative screen time. Every story evolves from the child’s imagination. No two sessions are the same because the narrative grows from the ideas the child introduces.
Multiple models working together. Conversation, illustration generation, moderation, and speech synthesis operate together in real time. Voice can trigger an illustration. A creative idea can trigger a badge. The system works as a single seamless storytelling experience.
Challenges
Visual continuity — Chaining images with the previous one as context keeps characters and art style consistent, but a silent data corruption bug in that pipeline took time to find.
Barge-in audio timing — Getting the handoff from AI speech to child speech to feel seamless — no gap, no stutter — required precise audio scheduling and many iterations.
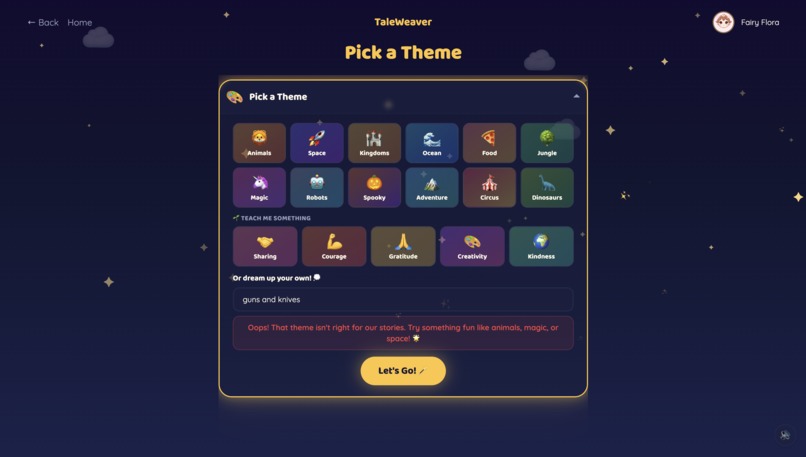
Calibrating the safety filter — Overcorrected once: everyday objects like mugs started getting blocked. The final pass only flags genuinely harmful content and defaults to safe.
Session synchronisation — Ensuring the story opening, audio playback, and WebSocket proxy all start in the right order required careful orchestration to avoid silent or broken session starts.
Multilingual language lock — Gemini Live adapts so naturally to the user that a Hindi storyteller would switch to English and stay there. Strict, adversarially-tested prompt rules fixed it.
What We Learned
Gemini Live is a paradigm shift. Barge-in, VAD, streaming audio — previously required a custom ASR + VAD + TTS stack. The engineering challenge shifts entirely to audio scheduling and session management on the client side.
Voice models need different prompting than text models. A voice model will eagerly match the user's language and register. Behaviours that feel obvious to lock in a text model require explicit, adversarially-tested prompt rules in a voice model.
Timing matters more than features. The race conditions and audio scheduling gaps weren't hard engineering problems — but all of them would have made the experience feel broken to a child. Getting seams right was more important than any individual feature.
What's Next
The immediate focus is polish — fine-tuning prompts, hardening edge cases, and perfecting the end-to-end experience across more devices and conditions. World-language characters in particular need more testing and refinement before they're ready for everyday use.
On the product side, a richer UI/UX is planned — more expressive storyteller animations, smoother transitions, and a more immersive storybook feel. Native iOS and Android apps are the natural next step to put TaleWeaver where children actually are, with offline resilience and proper audio handling on mobile.
Further out: Live Camera in story mode (Gemini sees the child's toys without breaking the narrative), a Learning Mode that weaves curriculum goals invisibly into the story, Cloud Storage so adventures persist across devices, and a Parent Dashboard to surface creativity patterns over time.
Team
| Name | Role |
|---|---|
| Padmanabhan Rajendrakumar | Primary Developer |
| Sharmila Raghu | Supporting Developer |
Built With
- fastapi
- gcp
- gemini
- gemini-2.5-flash-lite
- gemini-2.5-flash-preview-tts
- gemini-3.1-flash-image-preview
- gemini-image-generation
- gemini-live-2.5-flash-native-audio
- gemini-live-api
- gemini-tts
- google-artifact-registry
- google-cloud
- google-cloud-build
- google-cloud-run
- google-genai-sdk
- google-secret-manager
- nano-banana-2
- python
- react
- tailwindcss
- typescript
- vertex-ai
- vite
- websockets




Log in or sign up for Devpost to join the conversation.