-
-
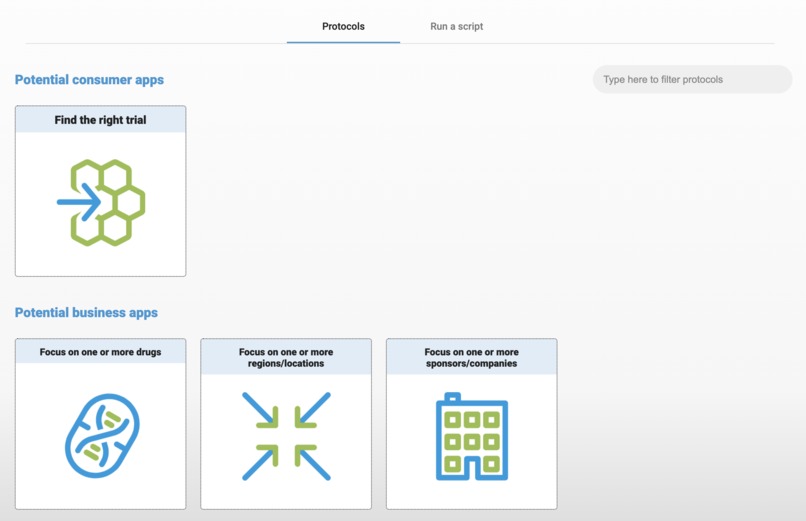
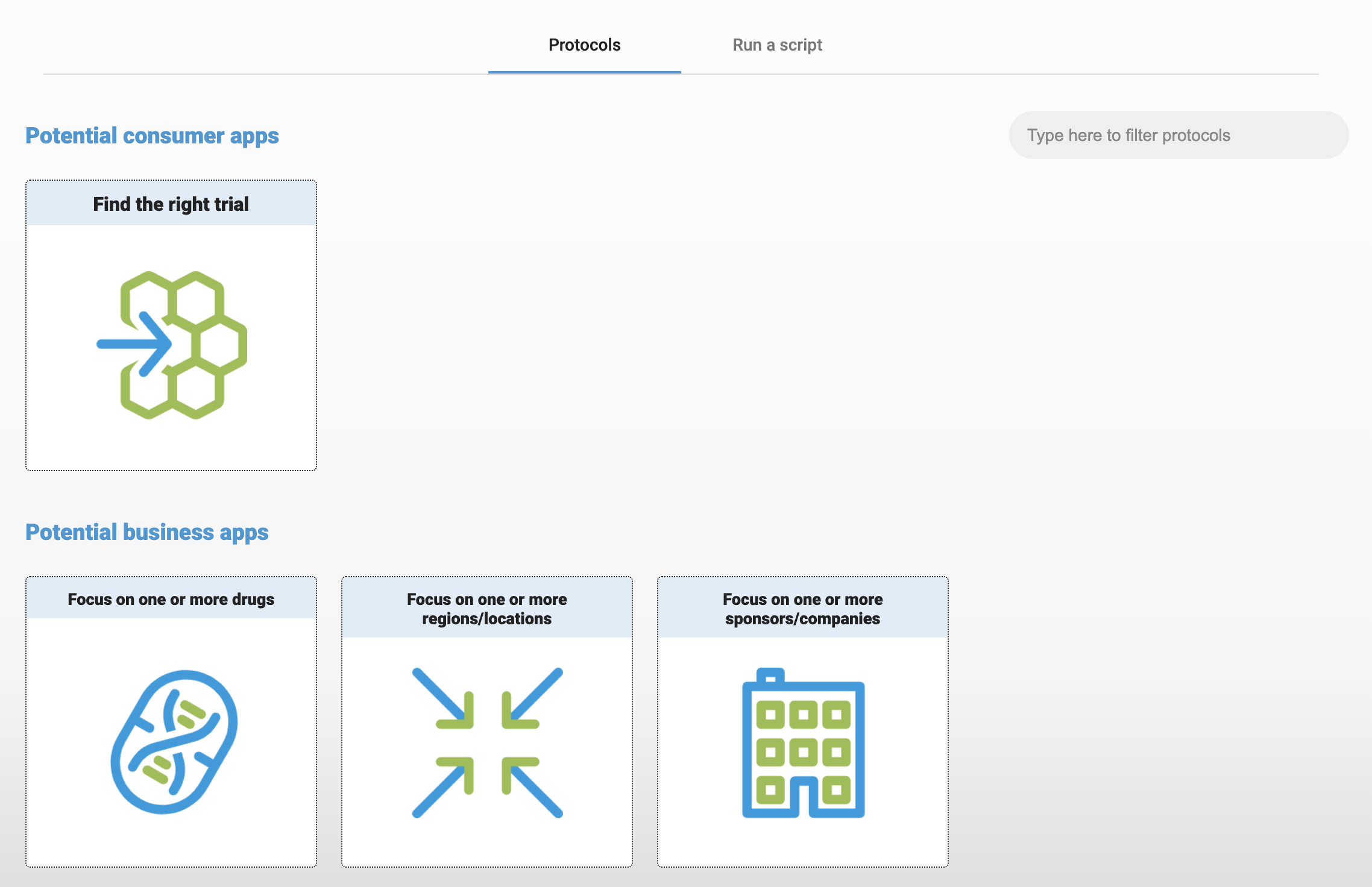
4 analysis apps!
-
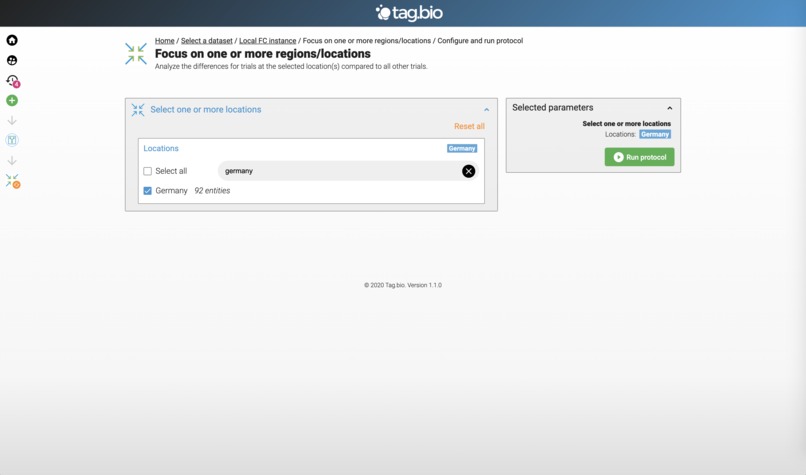
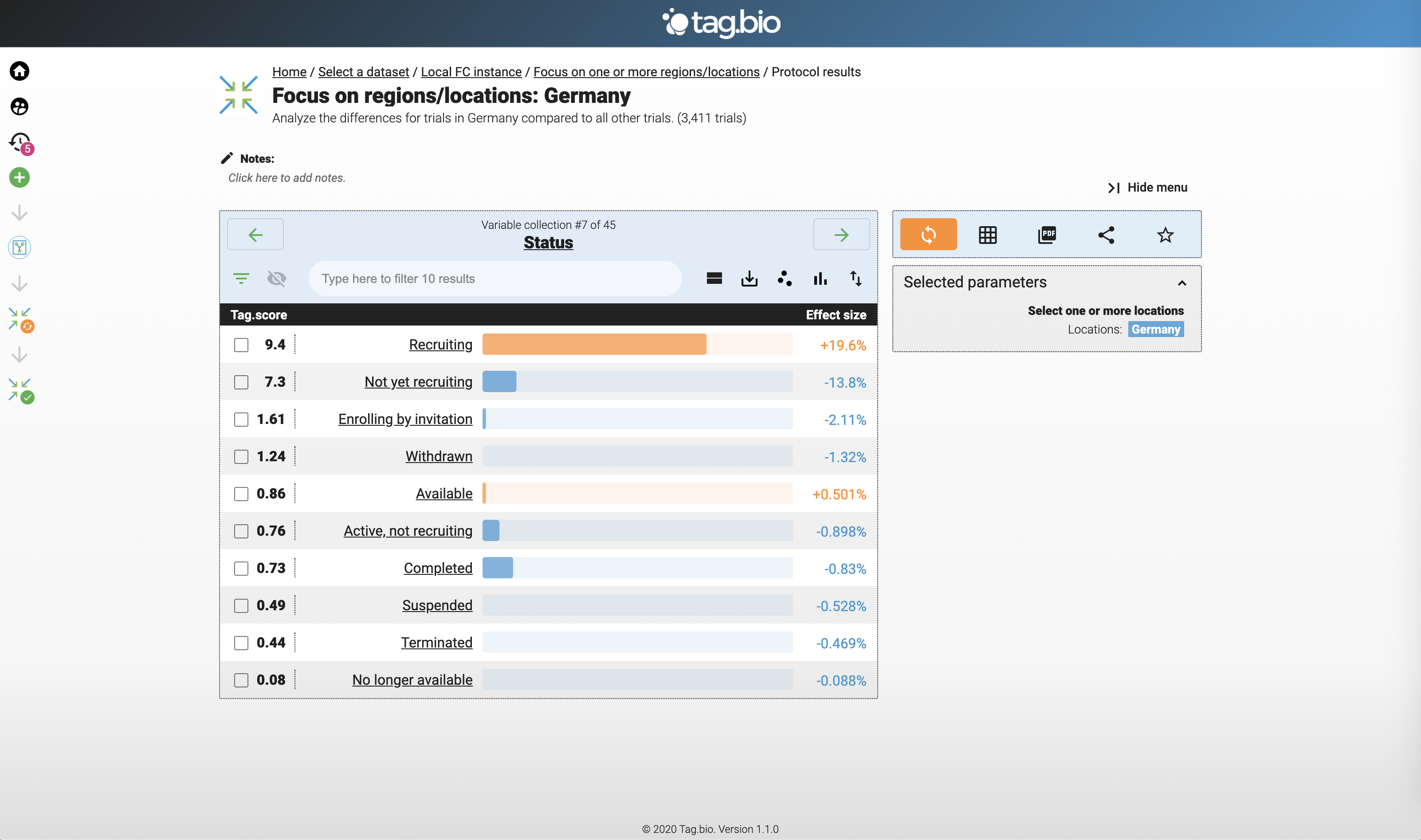
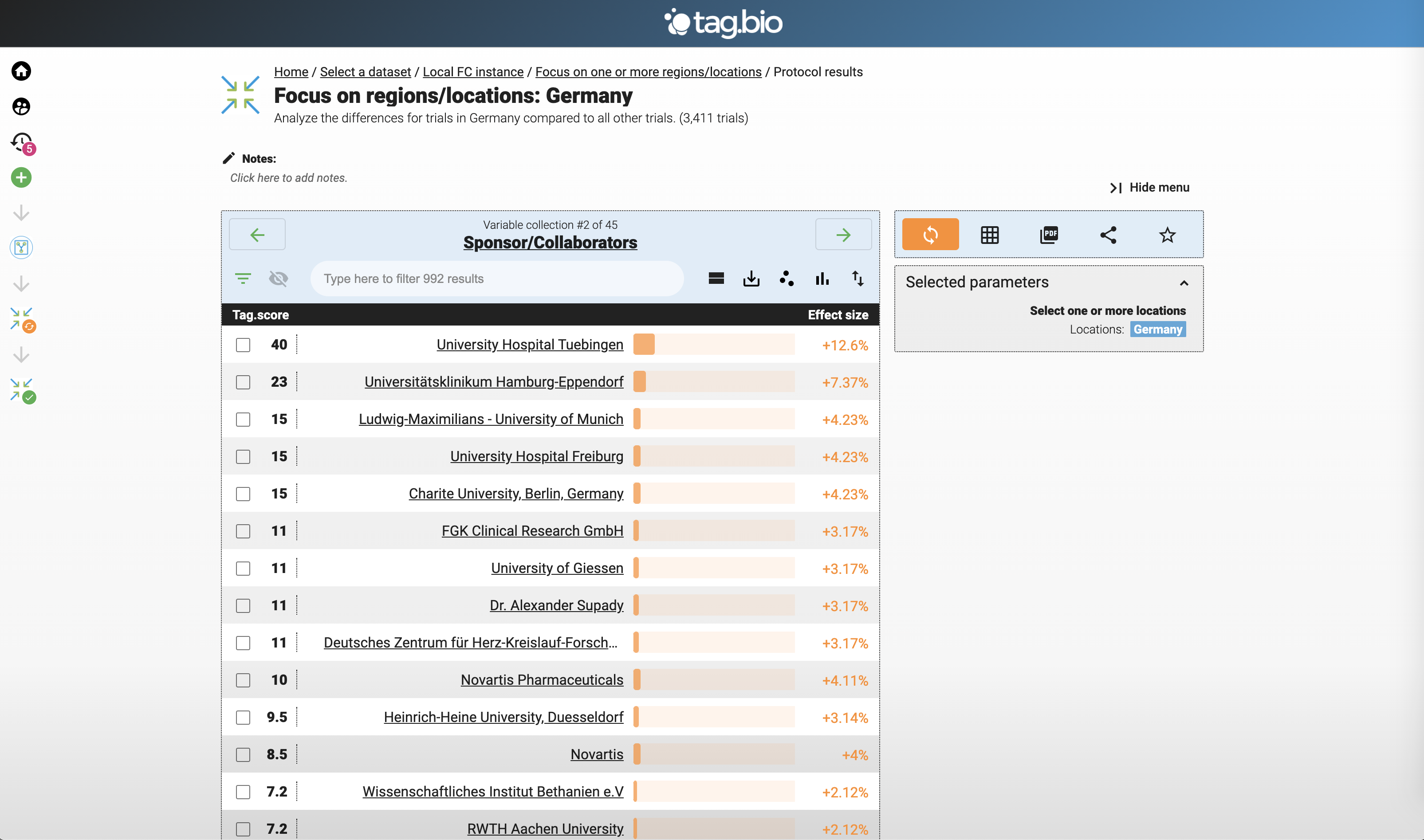
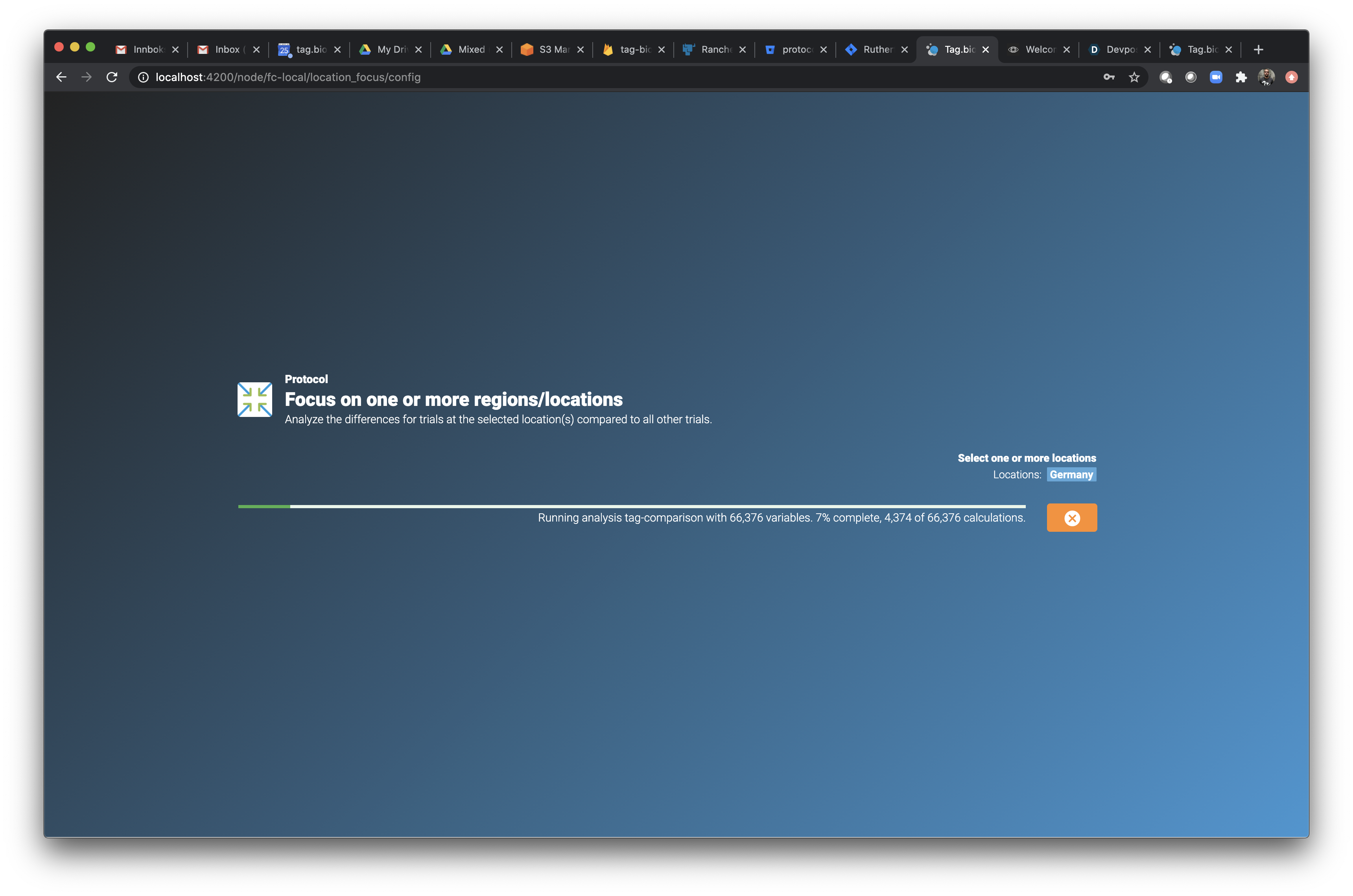
Focus on region: Germany.
-
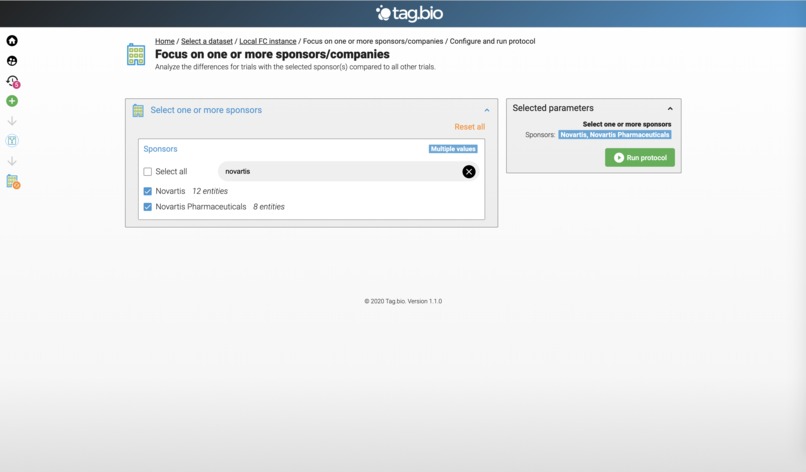
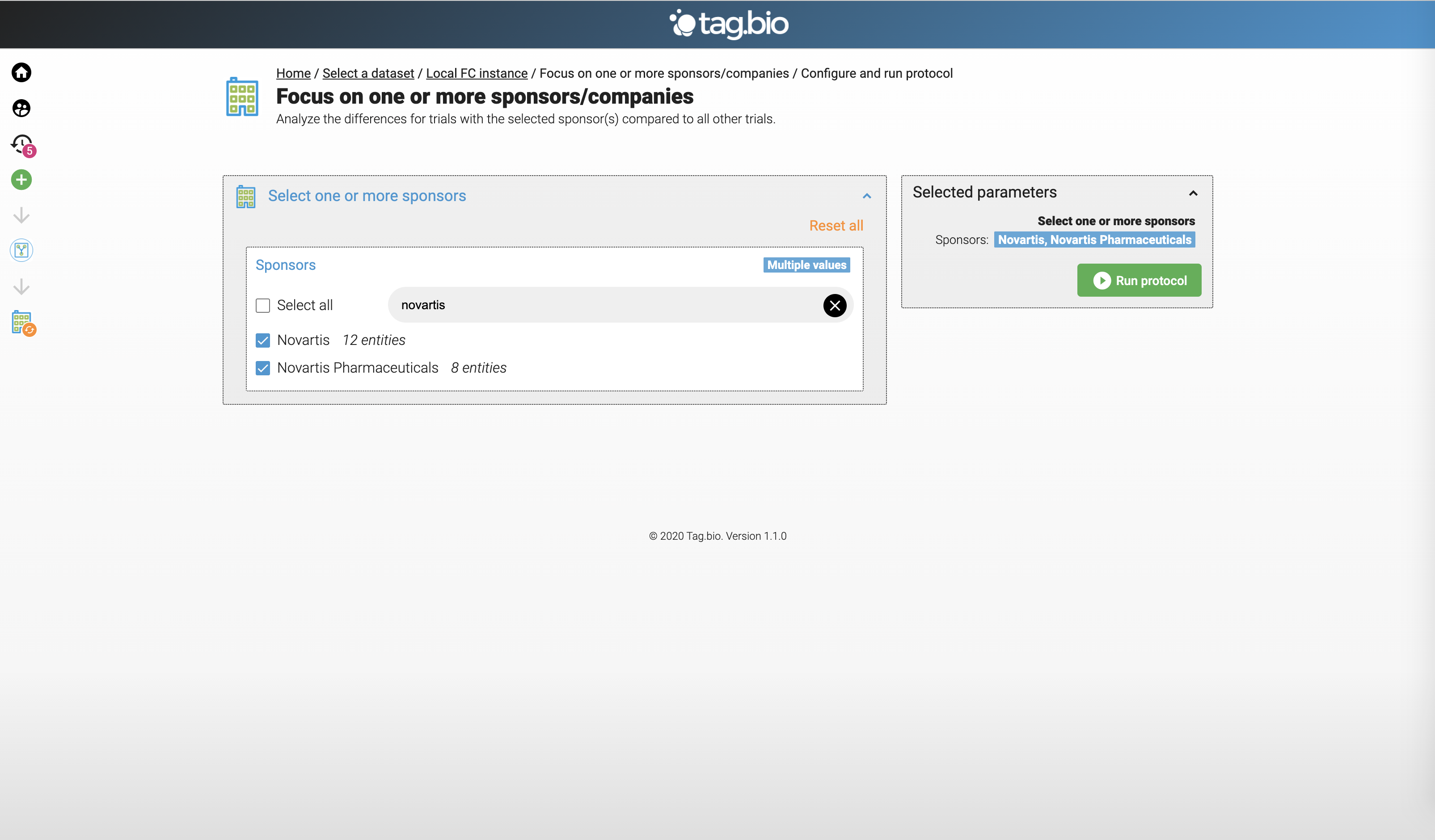
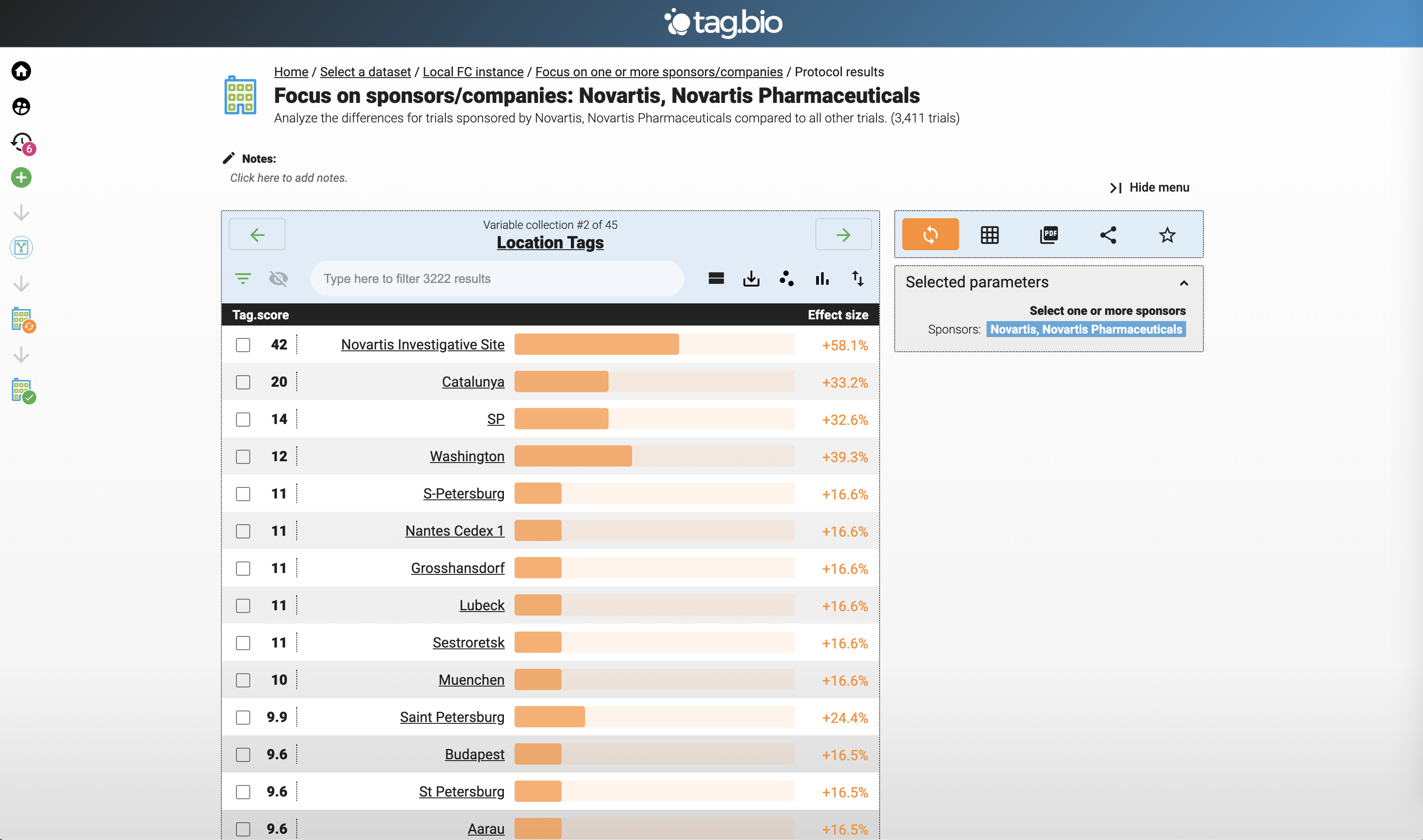
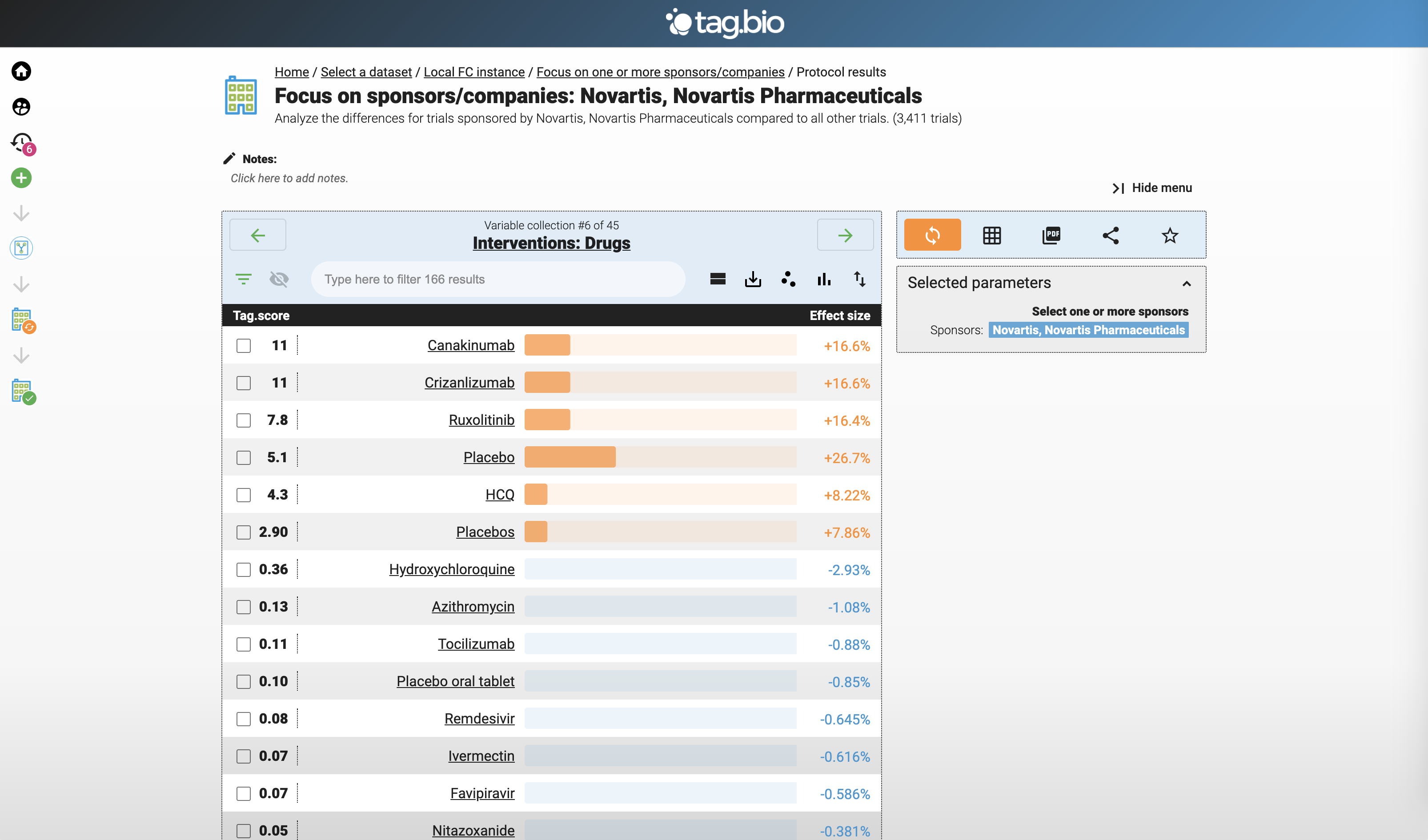
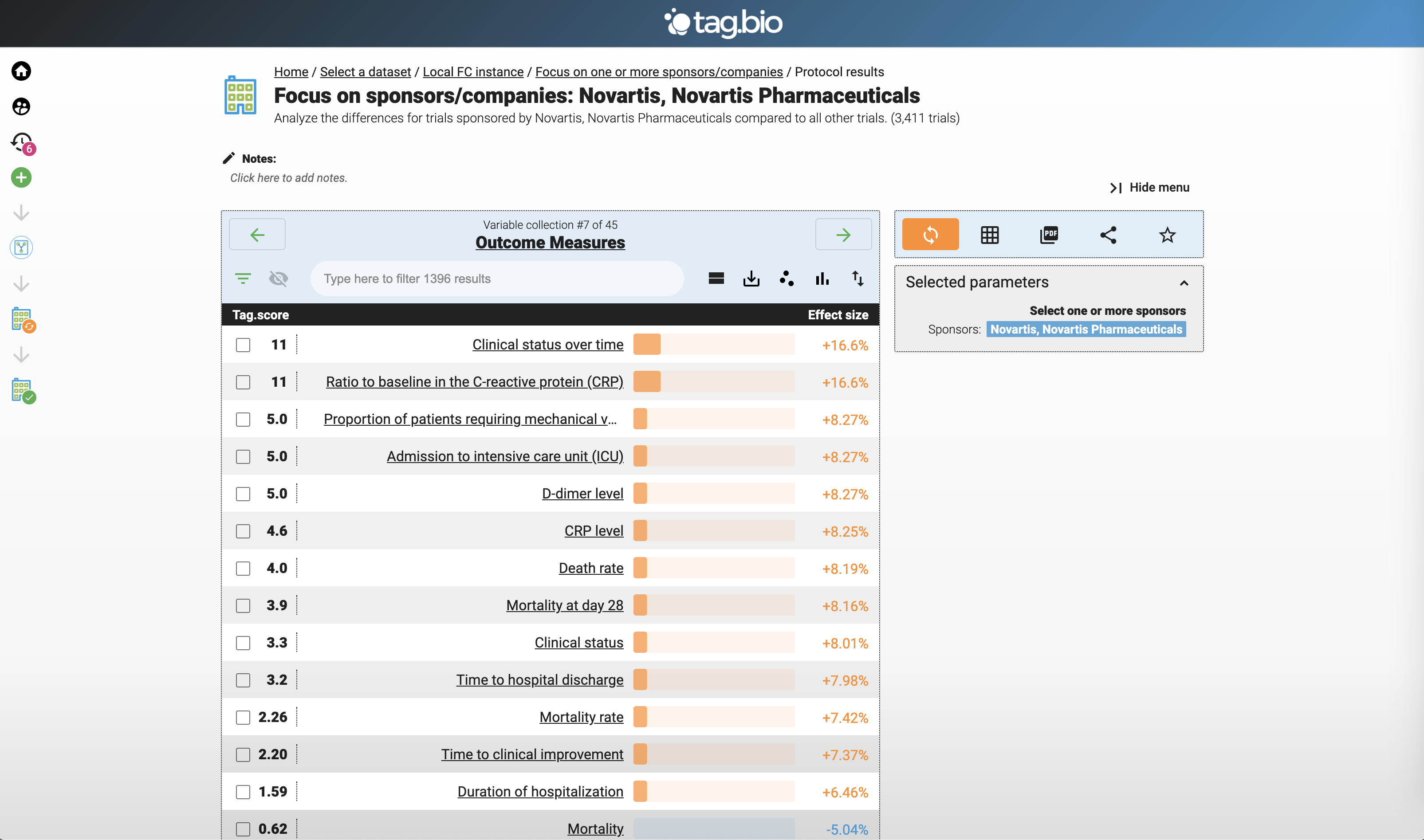
Let's focus on Novartis clinical trials.
-
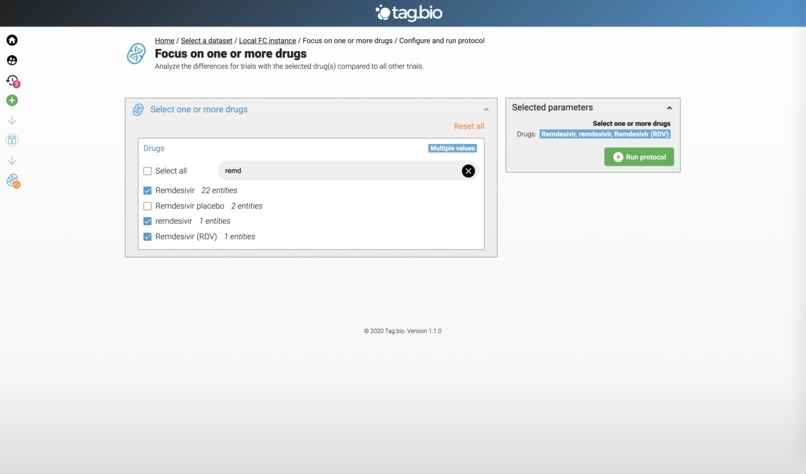
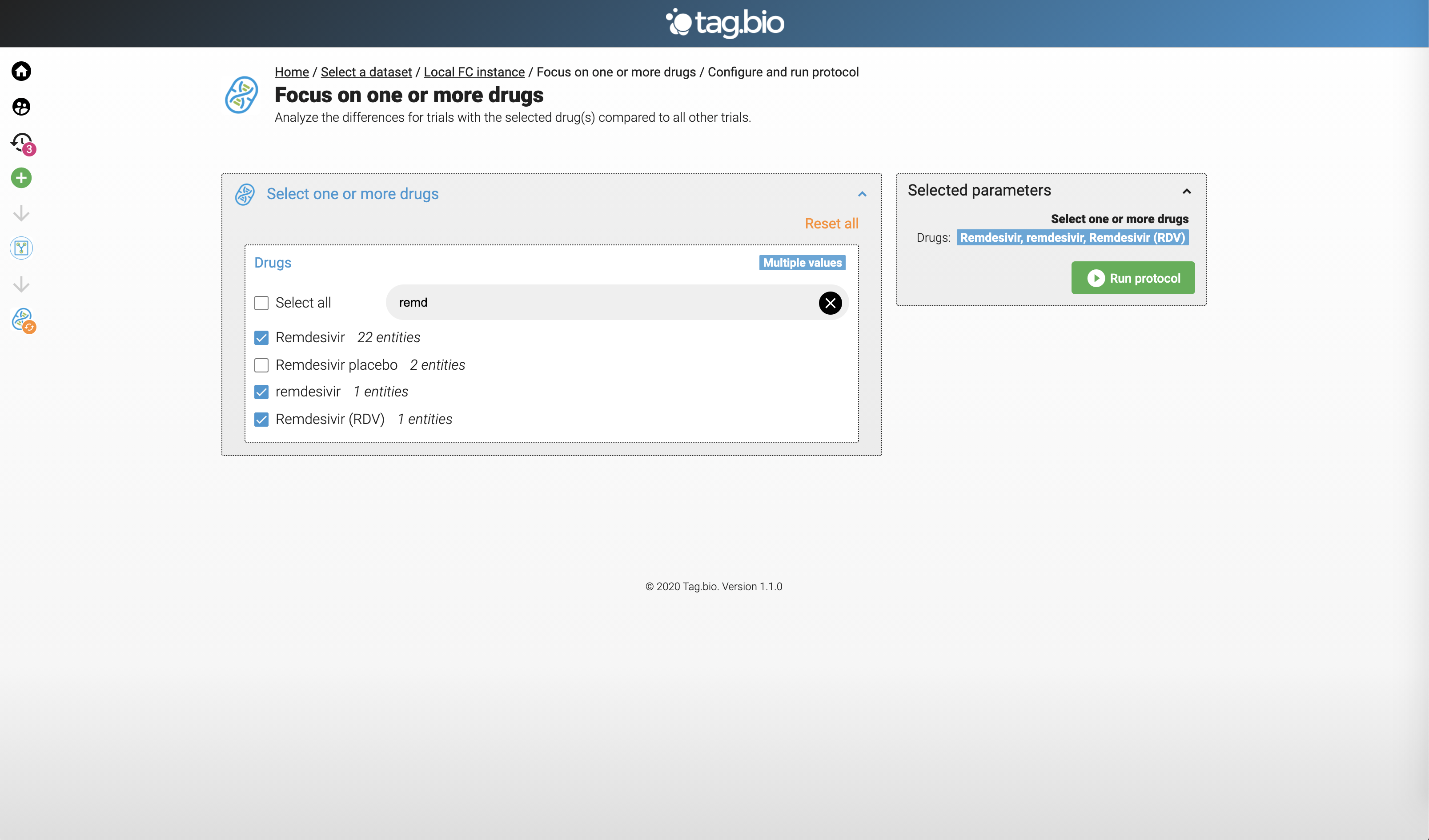
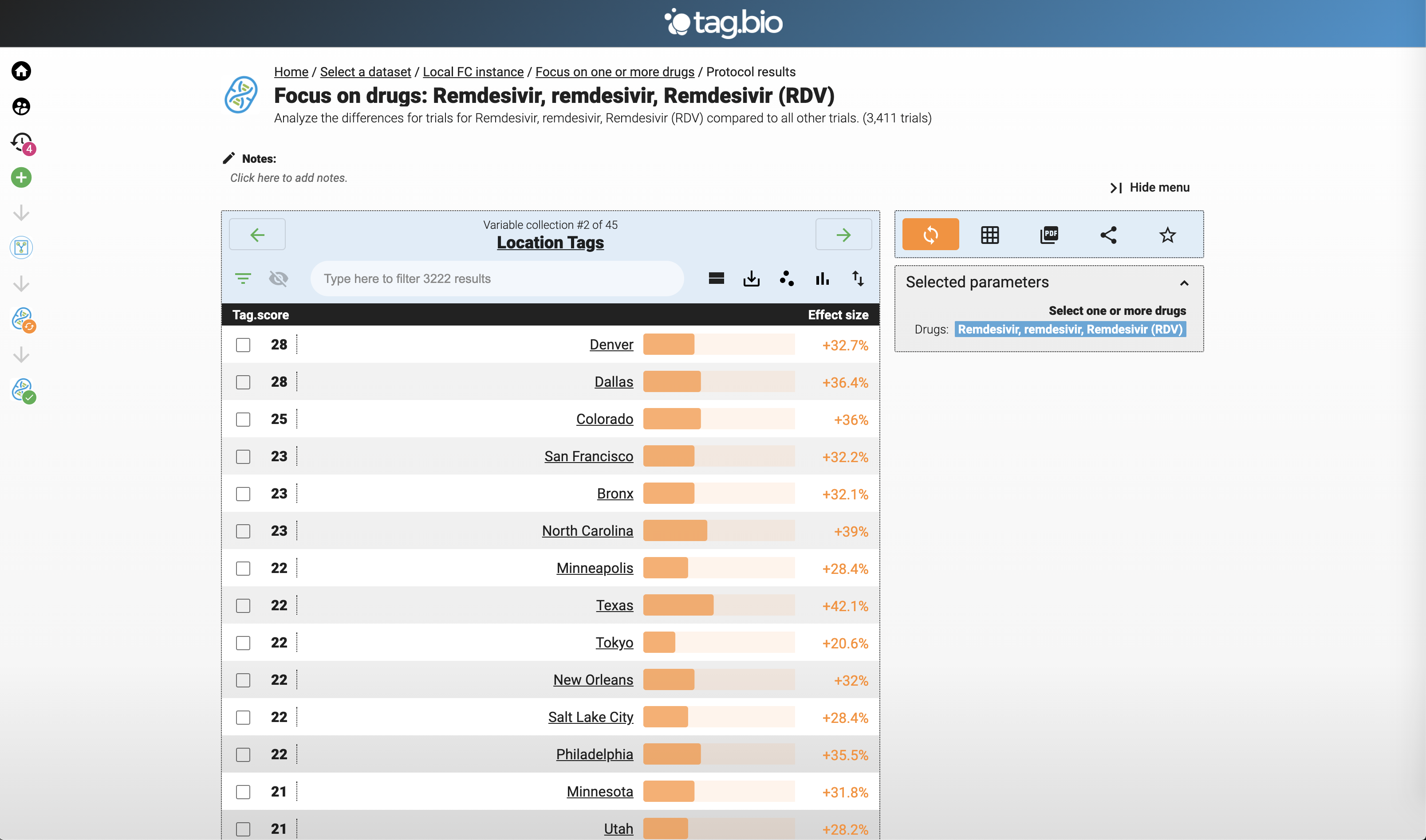
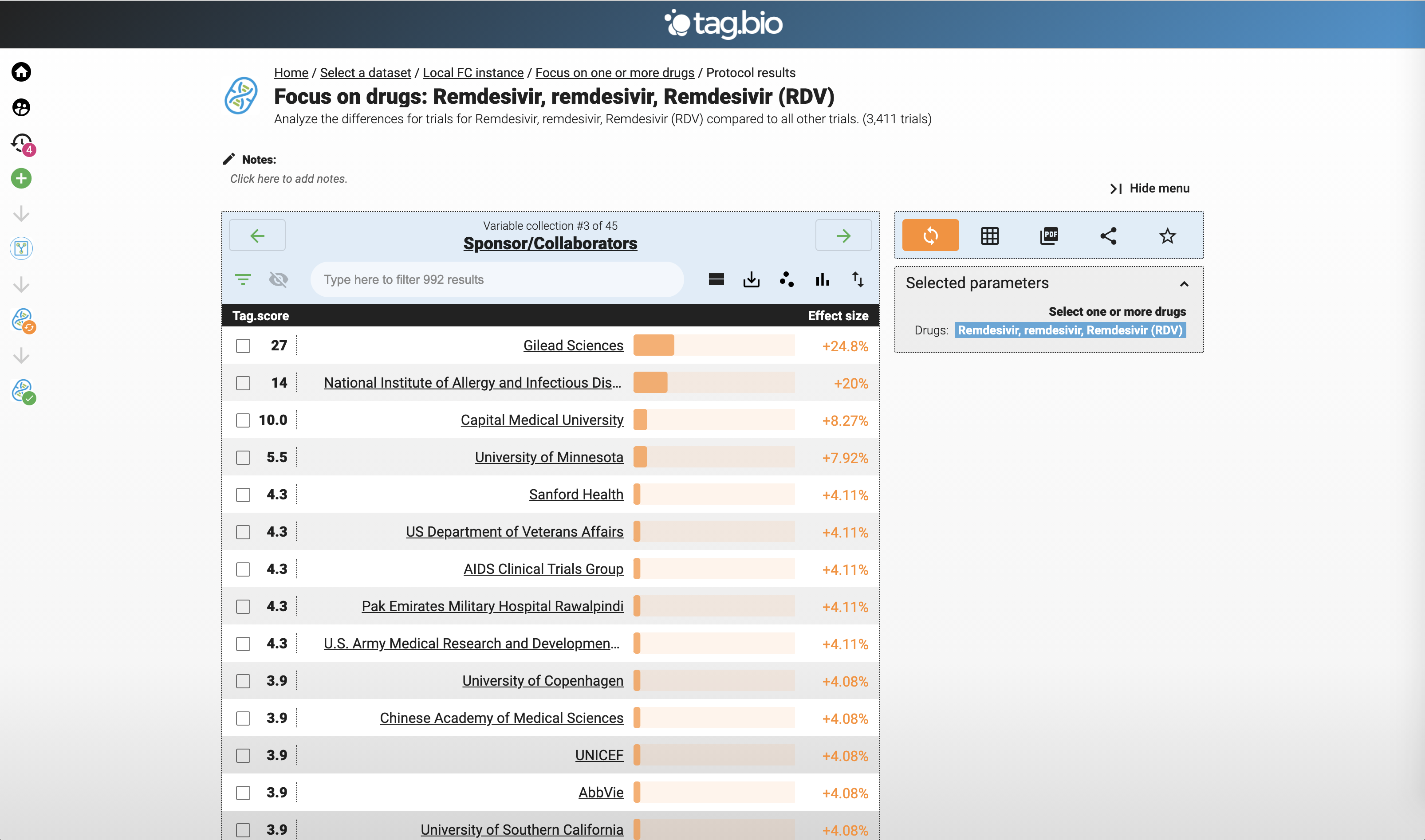
This should be above - using the drug app to focus on Remdesivir.
-
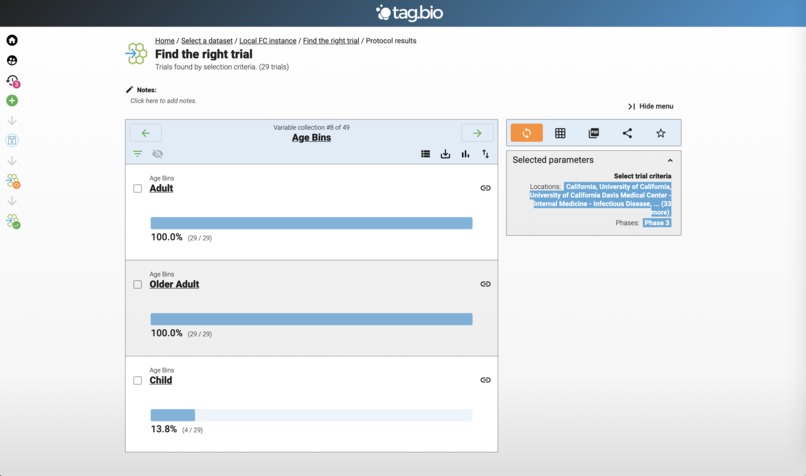
Found some!
-
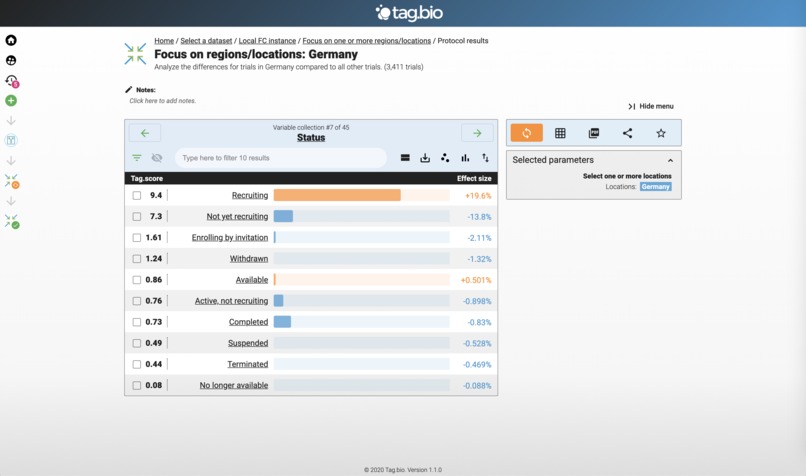
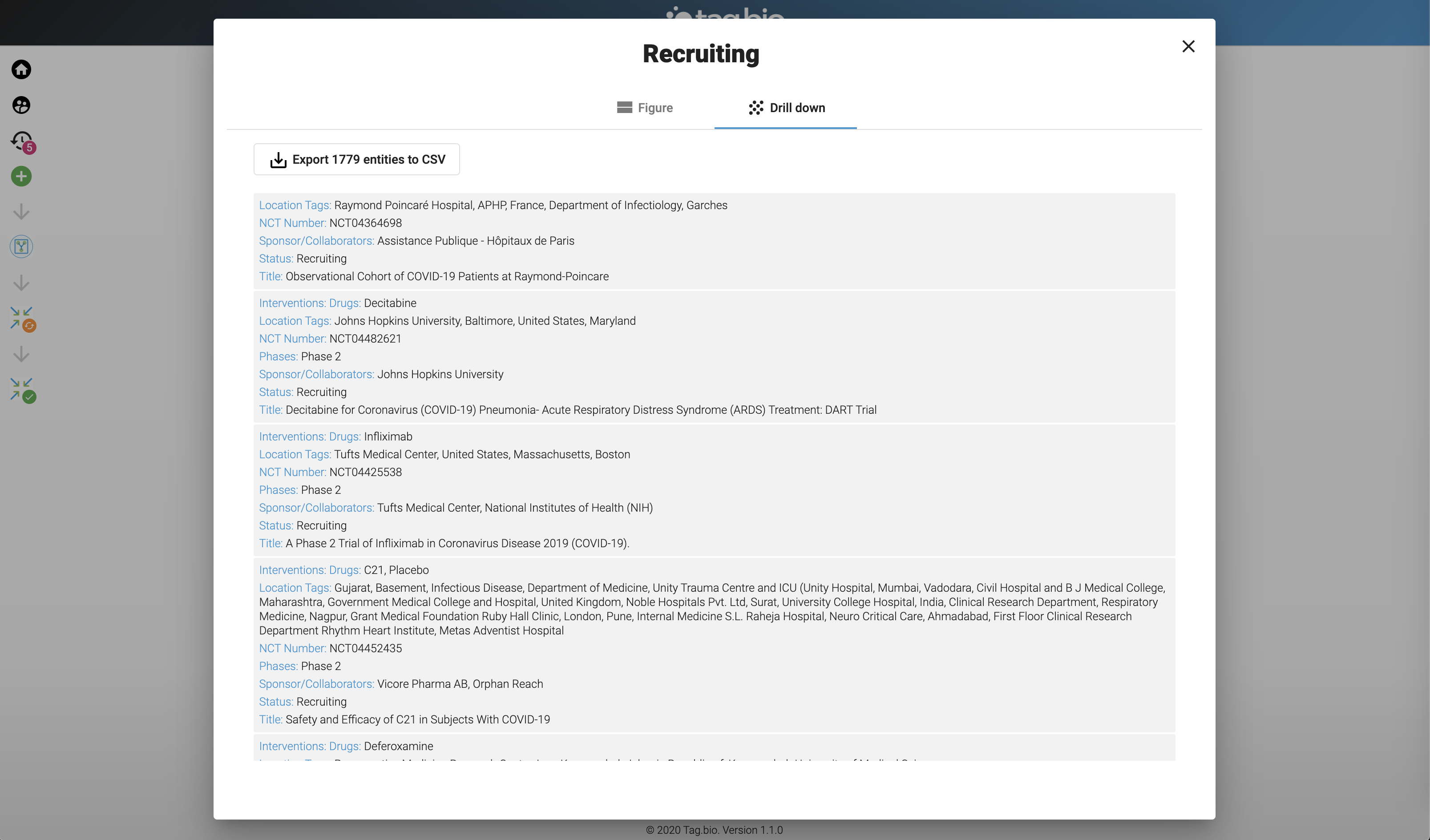
Lots of Recruiting trials in Germany!
-
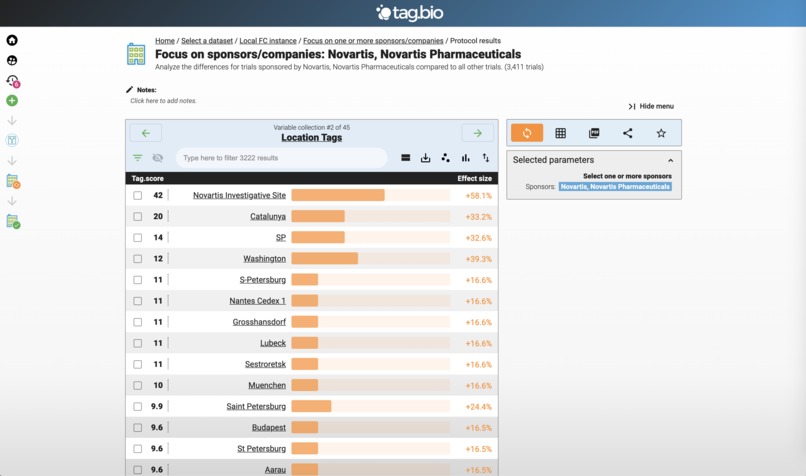
Here are the top locations for Novartis clinical trials.
-
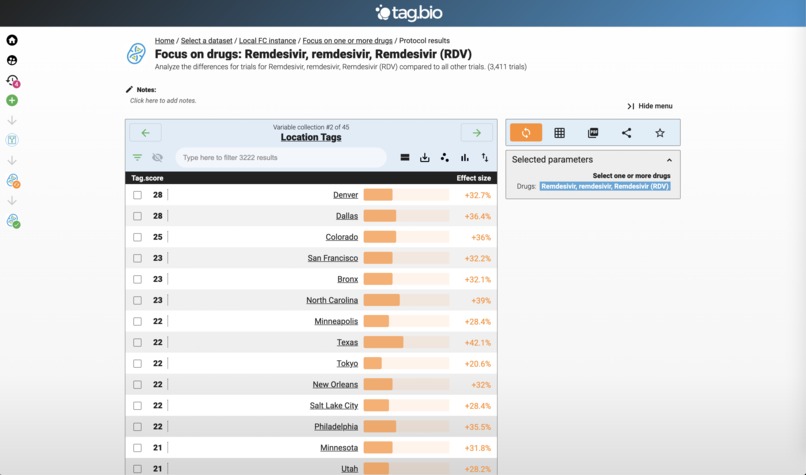
Top Remdesivir trials locations.
-
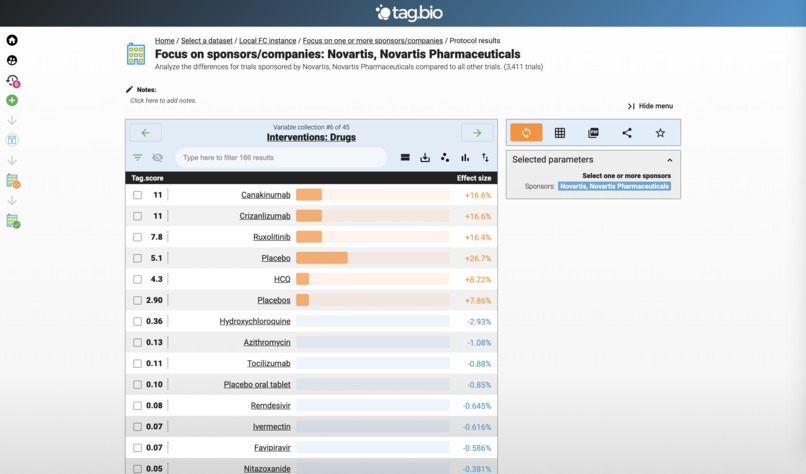
Here are the drugs for Novartis clinical trials.
-
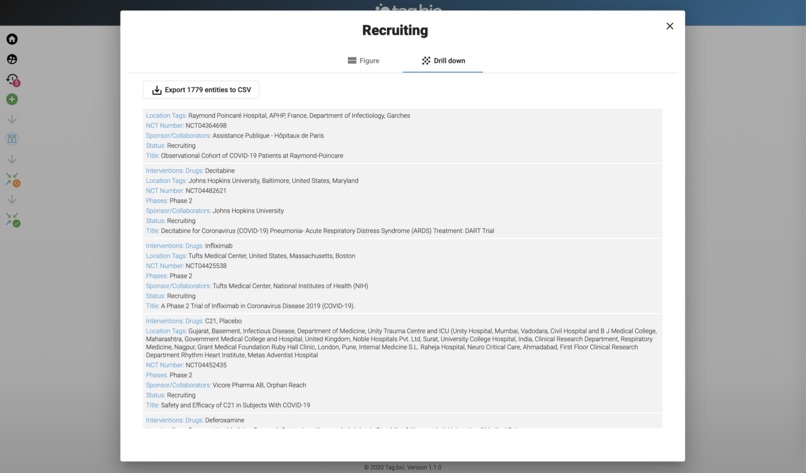
Can be downloaded by CSV.
-
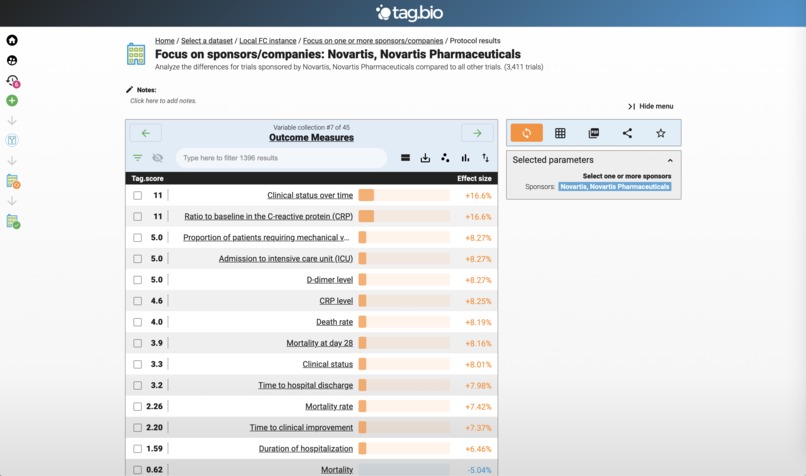
Here are the Outcome Measures for Novartis clinical trials.
-
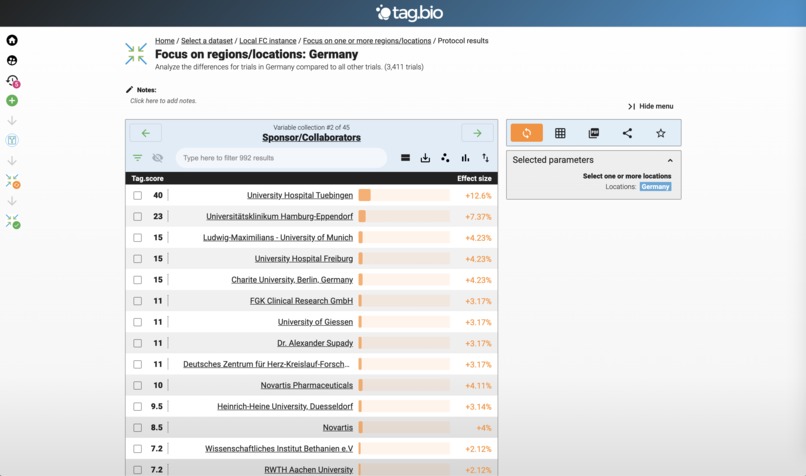
Top clinical trials locations in Germany.
-
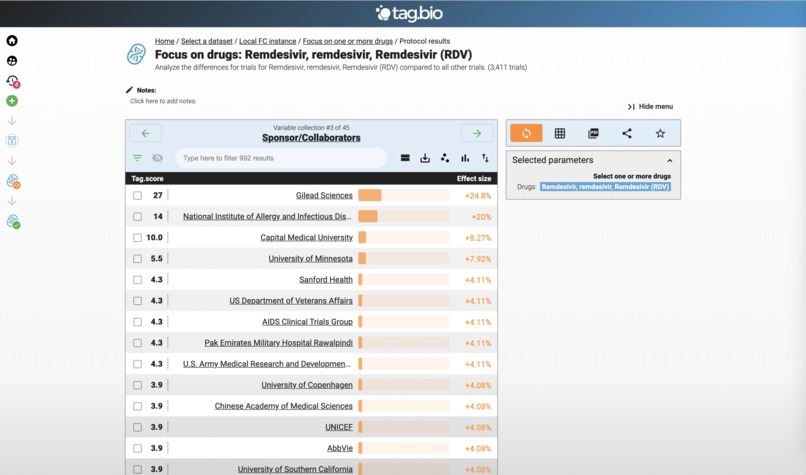
This is out of order - this is the result of the Remdesivir app. Clearly a Gilead drug, but note the collaboration.
-
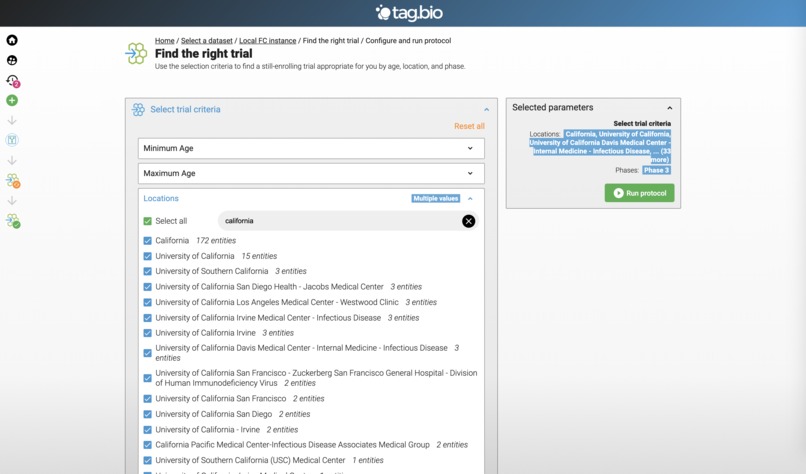
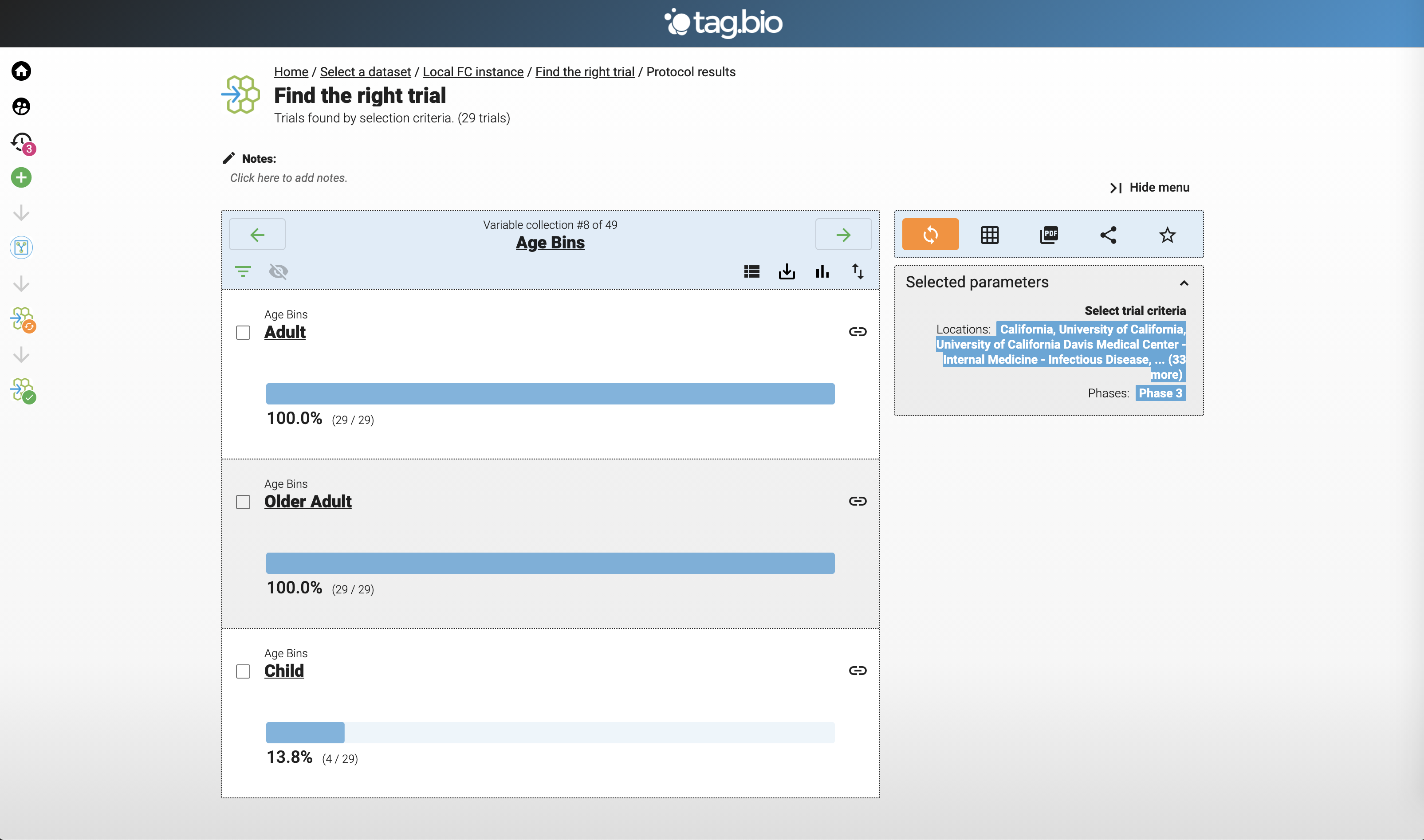
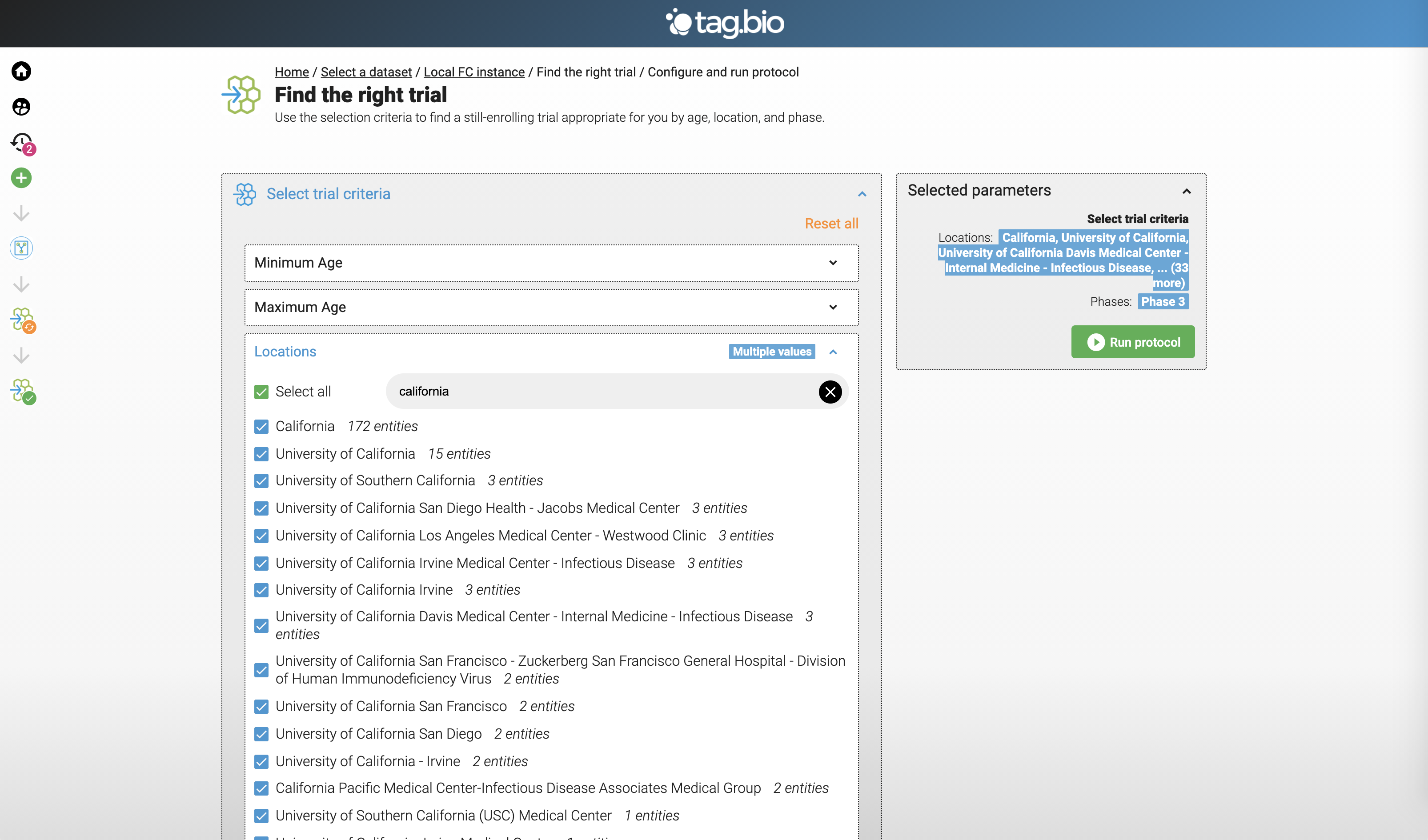
Looking for Phase 3 Clinical Trials in California.
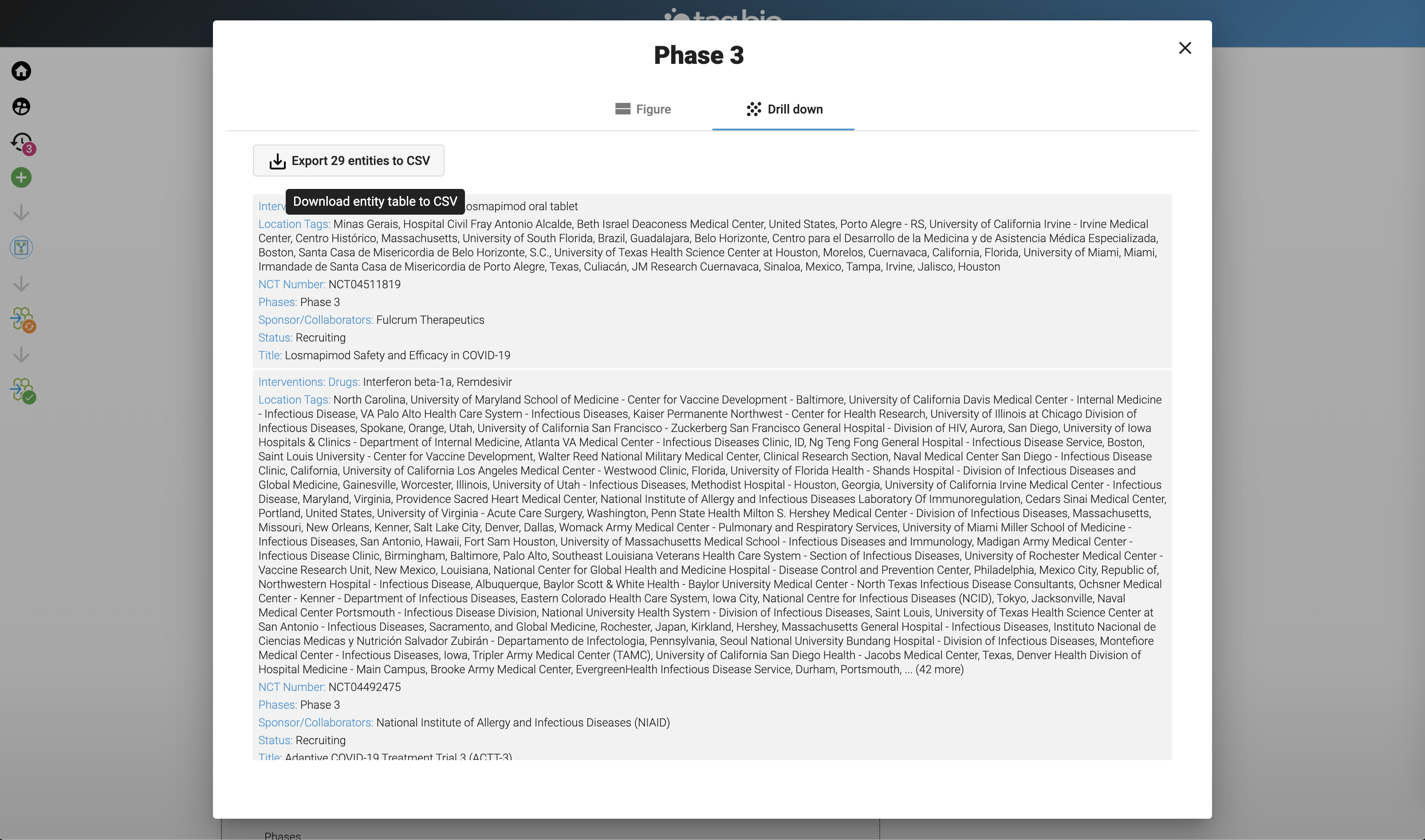
-
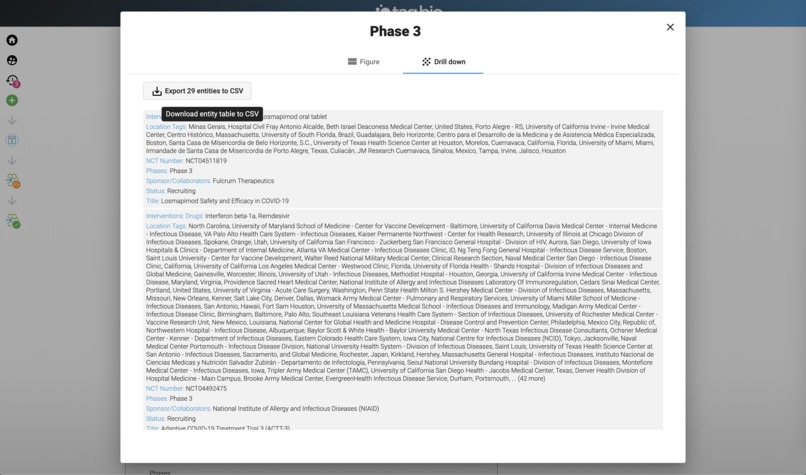
Can download these to CSV.
-
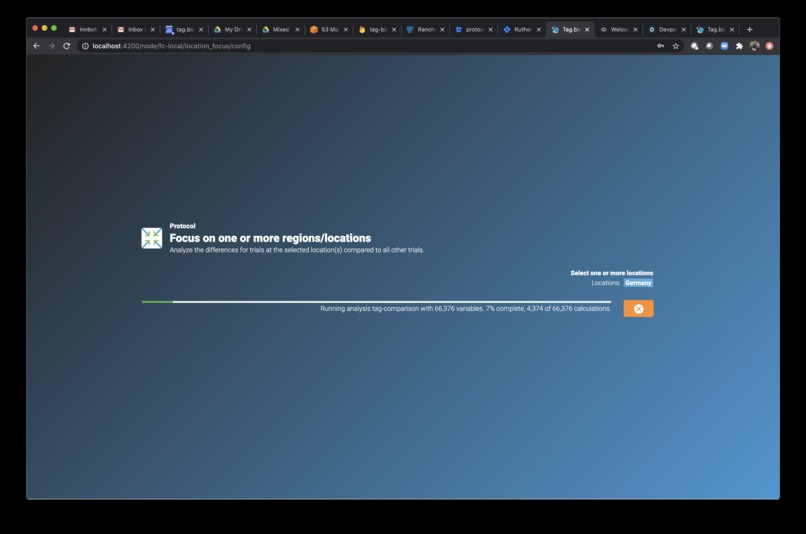
Note the number of variables analyzed - all analyses take less than 3 seconds.

Inspiration
Tag.bio is an early-stage San Francisco based startup, with founders from UCSF (Jesse Paquette, CSO) and Stanford (Tom Covington, CEO). We are focused on accelerating accessibility, scalability, security and value from Healthcare and Life Sciences data. This is a massive challenge, as the wide variety, size and data governance requirements around data present signifiant blockages to hospitals and pharmaceutical companies attempting to do this themselves.
Our technology, from its decentralized architecture - domain-specific nodes in data mesh - to its innovative, easy-to-understand user experience yields significantly faster, agile delivery of data applications within an enterprise, and a democratization of access and analysis capability to end users - doctors and biologists - who have high-value questions.
See: link for more information and customer stories.
For the hackathon, we used the idea to apply our platform to a novel dataset to demonstrate the speed of deployment and fast time-to-value - specifically given the Healthcare Data Accessibility Challenge.
The dataset, which we just started working on less than 24 hours ago - a single-disease (COVID-19) dataset from Clinicaltrials.gov containing metadata on over 3400 COVID-related clinical trials.
We deployed link as a working web application. We had hoped to make it publicly available by the Hackathon deadline, but at this point, however, it still requires us to manually set up logins for people that request them.
What it does
The link site makes clinical trials data more accessible and useful, as demonstrated by the COVID Lifeline data node. It provides the ability for users to ask interesting, valuable questions around regions, companies, treatments, and helps them find trials that could be available to them or their patients.
How we built it
Tag.bio is a software platform that handles the automation of data ingestion and application functionality via JSON-based templates. The platform also orchestrates container-based, secure cloud deployment of applications as data nodes. Essentially it automates the configuration and deployment of sophisticated data analysis applications of disparate types.
The customization templates for the COVID Lifeline project - involving processing and transformation of data and configuration of analysis apps (i.e. protocols) - were added to the Git repository here link.
Challenges we ran into
Data quality! The semi-structured Clinicaltrials.gov data isn't really useful in spreadsheet form at all.
Many of the fields have pipe | delimited values, like: "Assessment of the presence of the SARS-COV-2 virus at T4|Assessment of the presence of the SARS-COV-2 virus at T1|Assessment of the presence of the SARS-COV-2 virus in the peritoneal effusion at T2 or T4|Assessment of the presence of the SARS-COV-2 virus at T3|Assessment of the presence of the SARS-COV-2 virus at T5"
Or there are fields with inner key/value relationships, like: "Drug: Remdesivir".
The Age field was particularly a mess, with a typical value looking like "18 Years to 75 Years (Adult, Older Adult)".
All of the above problems we solved with our data mapping templates.
Another big issue arose from polymorphisms in spelling: the same field could contain "COVID19" for one trial, "COVID" for another trial, and "COVID-19" for a third, not to mention all the other forms of "Coronavirus", "Corona Virus", "Coronavirus Infection", etc. Drug names were equally as polymorphic.
That problem we address by letting the user's intelligence in the web app select all applicable synonyms.
Accomplishments that we're proud of
We worked really well together - and quickly - as a team, and we had fun. It would be nice to deploy a few more analysis apps, as they only take about 30 minutes to build, but we don't have any more time. And we usually revise analysis functionality by iterative consultation with people that really care about asking questions of each dataset. So that's the next step.
What we learned
Clinical Trials data is really messy, and could be so much more useful if it could be made cleanly accessible with apps for people that really need it.
What's next for Tag.bio COVID Lifeline
We'll get feedback from some folks (doctors, pharmaceutical researchers, financial analysts) who have a keen interest on using this data. We might consider deploying a B2C app, but for the moment, our startup focus is B2B.
It's clear that we can utilize the same templates and process for any clinical trials in this format, so we'll likely create a data node with the entirety of Clinicaltrials.gov, and focus on Oncology and Immuno-Oncology clinical trials with our Pharma customers.

Log in or sign up for Devpost to join the conversation.