-
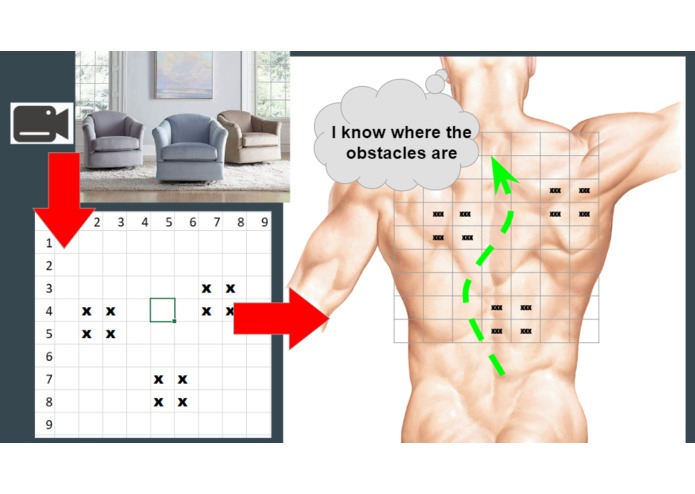
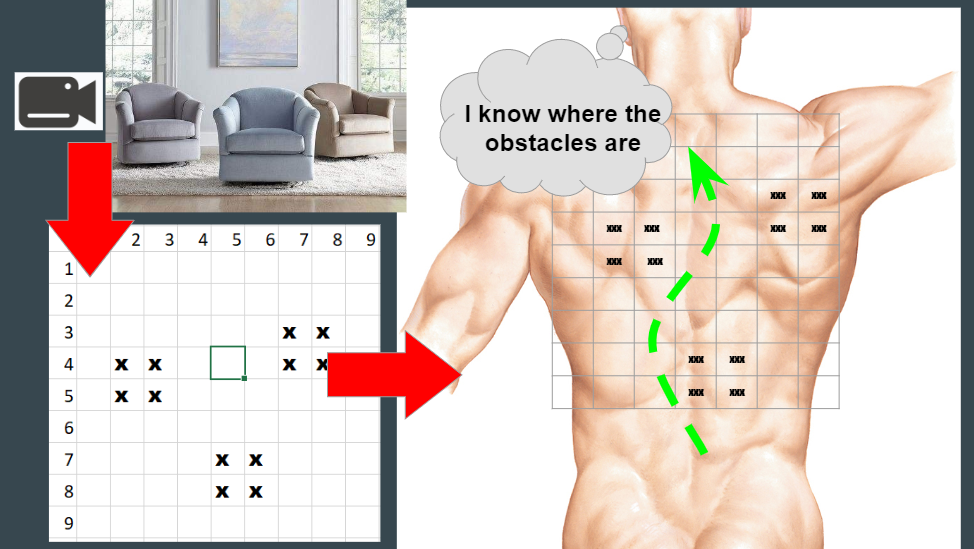
In the xz-map mode, the locations of objects are plotted on the skin, allowing for quick navigation/maneuvering
-
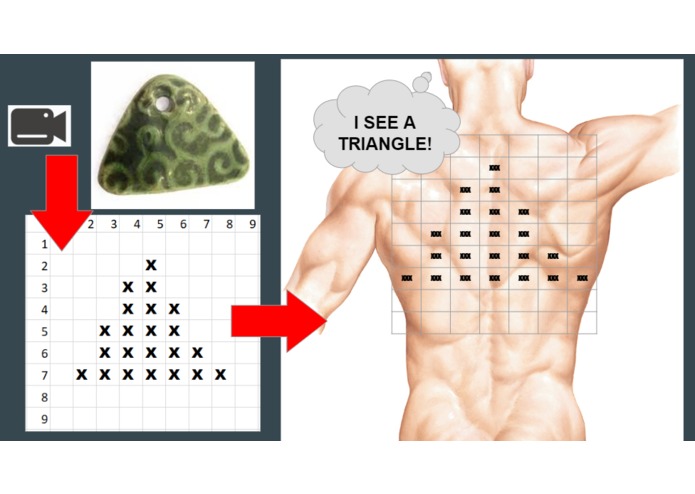
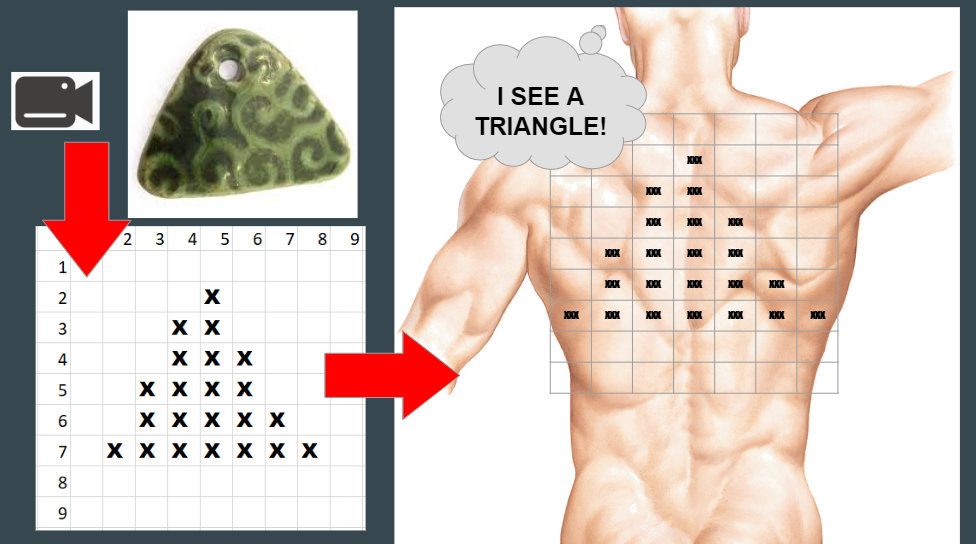
In image mode, shapes of objects are plotted on the skin, allowing for image recognition.
Inspiration
According to a survey by the Wilmer Eye Institute, 47.4% of Americans believe loss of sight was the "worst possible" health problem that a person could experience in their lifetime. This is no surprise, as total blindness can be debilitating. So many of our instrumental activities of daily living are dependent on vision. Blindness is the ultimate chronic disease as it robs us of not only our most important sense, but also our independence.
Currently, blind people compensate by using aids such as braille, guide dogs, voice controlled devices, and human assistance. While these technologies and systems have improved quality of life and independence by leaps and bounds, none of them address the most fundamental problem - that blind people cannot acquire detailed spatial orientation of objects around them.
Our goal is to enable the blind to perceive objects in their environment by using a visual prosthetic device.
What it does
In order to understand the device, we must first delve into the concept of graphesthesia. If someone writes a letter on your hand, or draws a shape on your back, you can easily perceive what it is they wrote. Our skin has an intrinsic ability to understand and map out spatial data. In this respect, it is almost exactly like the retina of the eye, with the key difference that the skin responds to touch, while the retina responds to light.
By using a camera, we can collect visual data. A computer program then analyzes the data and highlights the most important details while suppressing background noise.
How we built it
Since the aim of the hack is to provide visual information in the form of tactile feedback, the subjects receives the tactile signals which are encoded in a way that allows the transmission of the location and distance of the objects from the subject. We carried this out by dividing our solution into three distinct categories. 1) A binocular system composed of two cameras that computes the depth of the objects in the image. This is integrated to an object detection algorithm that detects the objects in that image. 2) An algorithm that transforms the object location and depth to a 5 x 5 grid. Where the columns of the grid tell the patient whether the object is toward the right, center or left, and the rows tell the patient how far this object is from him. This is specifically for proof of concept, can be scaled to a larger grid with increased resolution. 3) A raspberry bi micro controller that
Challenges we ran into
We had many challenges throughout the weekend. First we couldn't figure out which hardware is best to use with the cameras arduino vs Raspberry pi vs phone. A phone would complicate things with the motors and communication of the information and an arduino needed an external connection to be able to connect to cameras, therefore we went with an RPI. MLH did not have a keyboard or HDMI to use and therefore we had to run out and and buy a keyboard and other equipment worth 200$ to be able to use the raspberry pi.
Designing the circuits was a huge challenge where we discussed our design and went back and forth between designs until we figured out a design that works for our hack!
Another major challenge was integrating everything together. It took a lot of brain power to be able to connect the camera to the raspberry pi, translate that into horizontal and depth, output the result to the 5x5 (25) motor grid. There’s a thousand mini steps that we had to figure out while we’re working.
Accomplishments that we're proud of
Our team did not give up. This is one of the most challenging hardware hacks because we are using 5x5 grid of motors. This means we have 25 motors connected to a pi, with rows and columns in series. There’s a ton of wiring to do to also make sure everything stays in place.
We were also able to get the depth of an object with a good accuracy using the limited RAM of a raspberry pi. Reason we were able to is we were downsizing the image so it can be translated.
What we learned
We learned a whole bunch of things as we were combining AI with hardware development. We learned on how to work with the Raspberry Pi and deal with its limited resource (RAM) and referencing a lot of different AI algorithms in order to make one that would detect multiple objects and downsample an image of large resolution to a lower resolution of 5x5 vibration motors
What's next for TacticalVision
TacticalVision We plan to make our algorithm more robust and use more powerful and smaller embedded devices for TacticalVision. We also plan to increase the resolution of the vibrator motor grid so that the user has a more accurate visualization of his or her environment. Overall, we plan to try to give blindness a new method of understanding his surroundings.
Built With
- electronics
- opencv
- python
- raspberry-pi






Log in or sign up for Devpost to join the conversation.