-
-
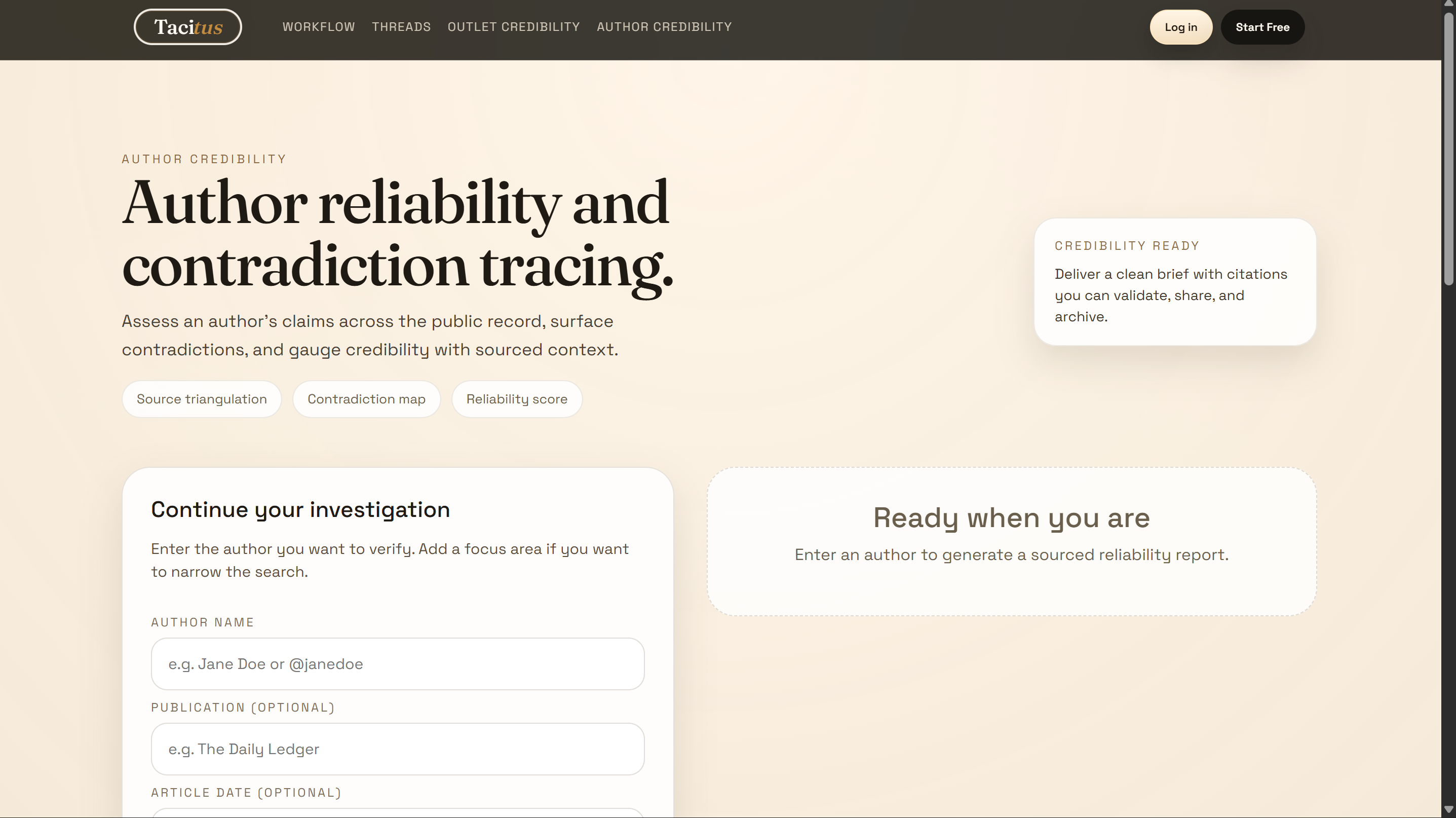
Author Reliability!
-
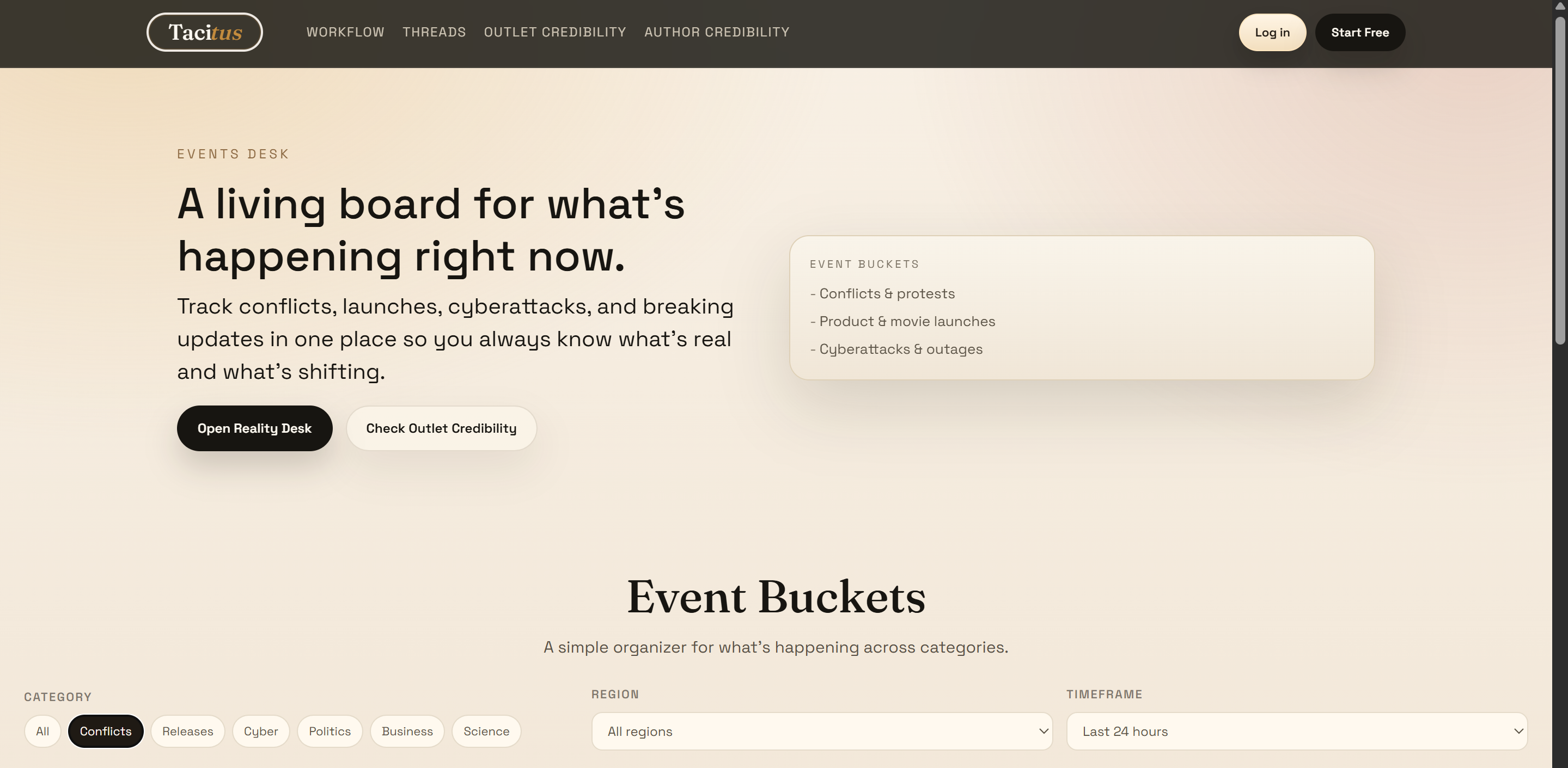
Event Bucket!
-
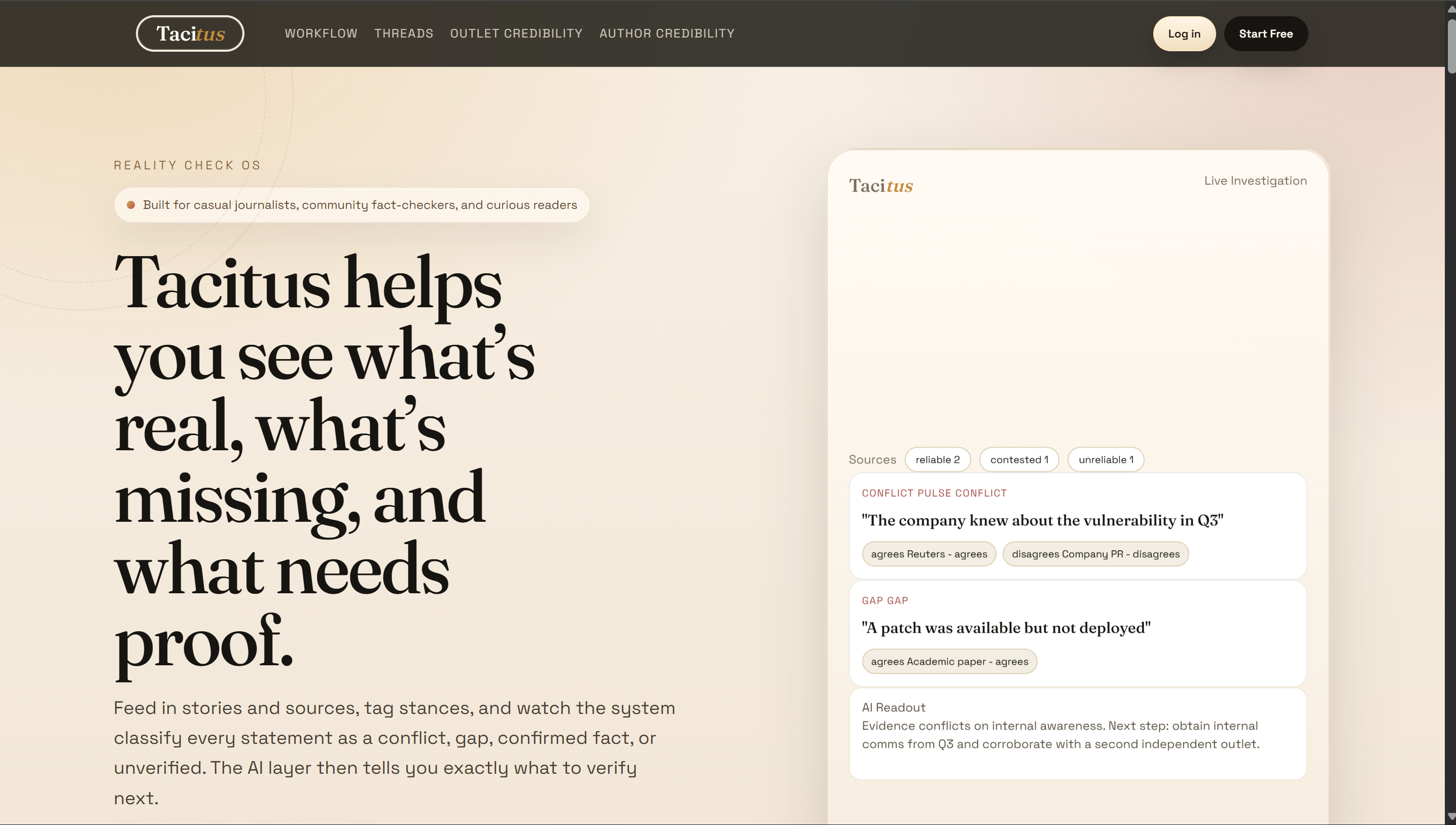
Home Page!
-
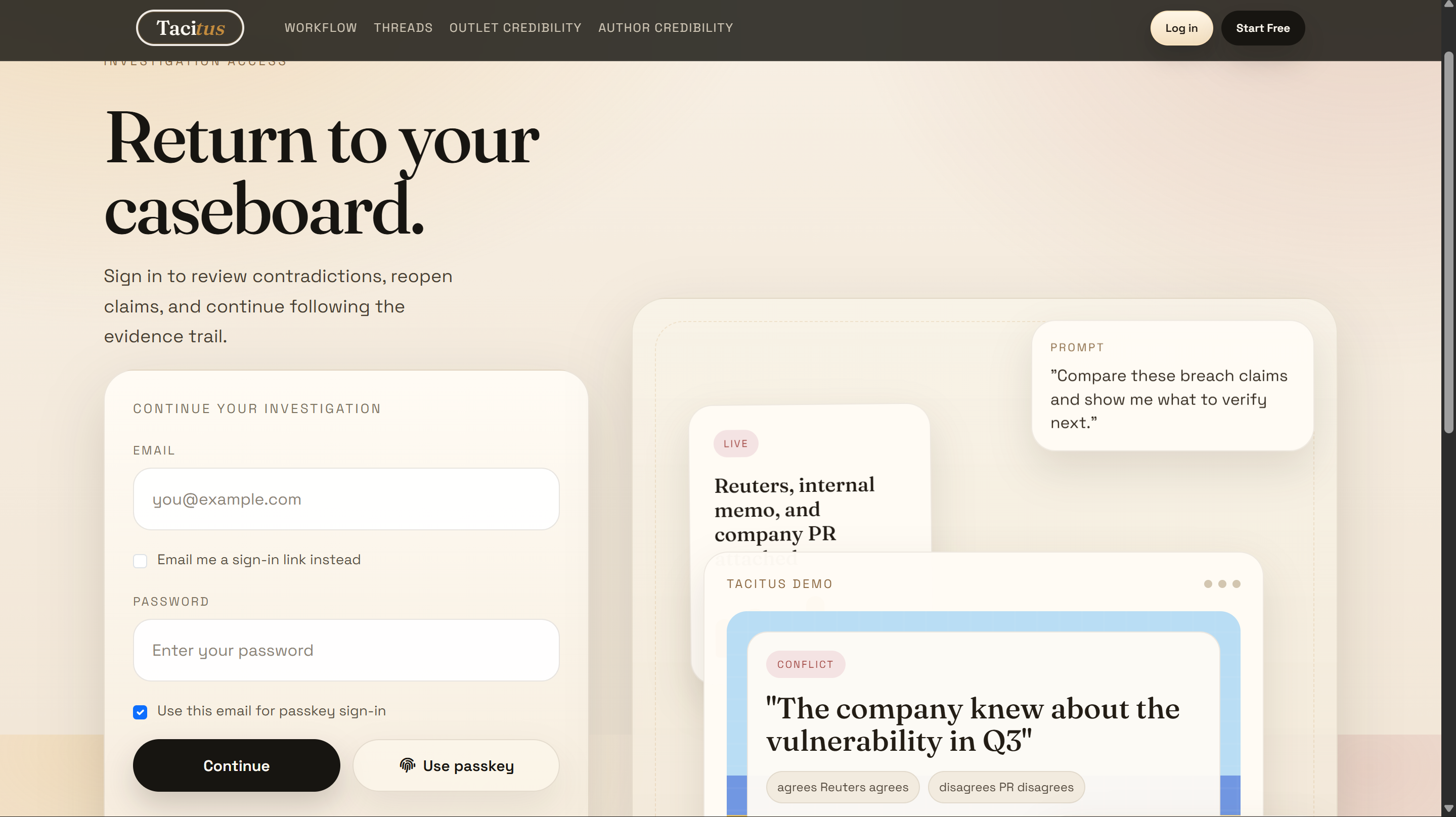
Log in page!
Inspiration
It started in a group chat. Someone posted a news article and immediately half the conversation turned into "that outlet is biased" vs "no, that's literally what happened." Nobody could agree on whether the source was trustworthy, let alone the actual story.
What bugged us wasn't the argument — it was that there was no good way to map it out. You had to hold every contradiction in your head at once, which is exhausting and easy to mess up. We thought: what if you could just see it? Lay every claim side by side, show who agrees, who doesn't, and where the story starts falling apart. That's where Tacitus came from.
What It Does
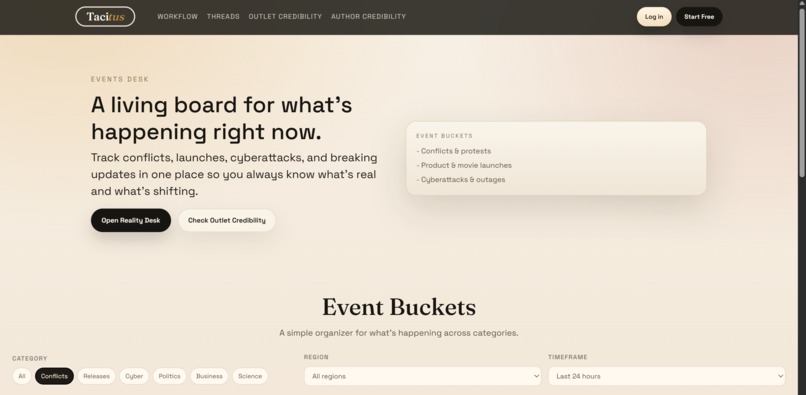
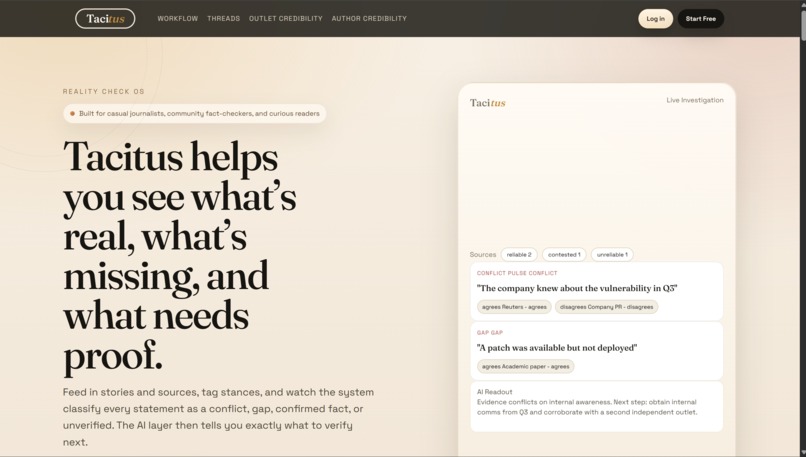
Tacitus is an investigative research tool for tracking claims across multiple sources and automatically flagging where they conflict. You add sources — outlets, people, documents — attach them to specific claims, and tag whether each source agrees or disagrees. The app then classifies every claim into one of four buckets in real time:
- Conflict — at least one source agrees and one disagrees
- Confirmed — two or more independent sources agree
- Gap — only one source has weighed in
- Unverified — nobody has said anything yet
The classifier is just clean math. If \( A \) is agreeing sources and \( D \) is disagreeing:
$$ \text{type} = \begin{cases} \text{Conflict} & A \geq 1 \text{ and } D \geq 1 \ \text{Confirmed} & A \geq 2 \text{ and } D = 0 \ \text{Gap} & A = 1 \text{ and } D = 0 \ \text{Unverified} & \text{otherwise} \end{cases} $$
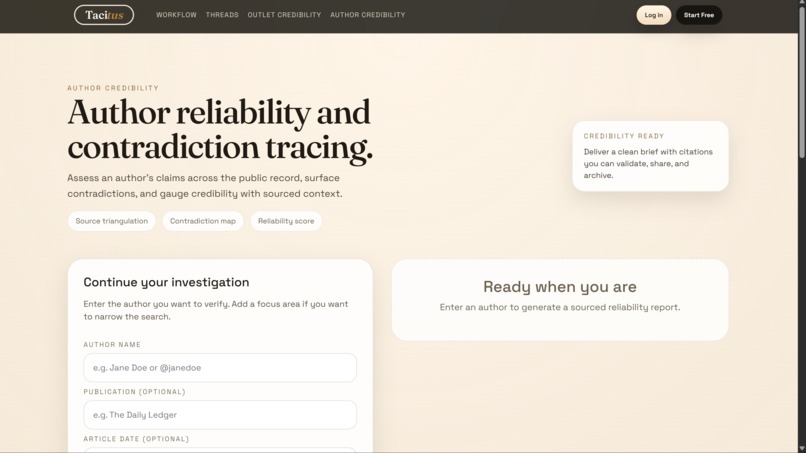
We also built a Fact Check tab where you enter an author's name and it runs a live web search through the Gemini API, returning a reliability score from \( 0 \) to \( 100 \), a political leaning label, known contradictions, and notes on source freshness.
How We Built It
Backend is Node.js + Express. We used MongoDB with Mongoose for
storing users and sessions, and Pug + Sass on the frontend. Auth runs
through Passport — local email/password plus passkey support via
@simplewebauthn, which felt like a win to actually ship.
The most interesting piece was the Fact Check controller. We call the Gemini 2.5 Flash API with Google Search grounding enabled, feed it a structured prompt asking for JSON, then strip markdown fences and parse:
const body = {
contents: [{ parts: [{ text: buildPrompt(author, focus, timeframe) }] }],
tools: [{ google_search: {} }],
};
Challenges
Prompt engineering was genuinely hard. We went through five versions of
the system prompt before it reliably returned clean JSON. The model kept
sneaking in a sentence of explanation before the {, which immediately broke
JSON.parse. We ended up writing an extractJsonString helper that strips
fences and finds the first { to the last } as a fallback.
Scope creep in reverse. We had a ton of ideas — timeline view, evidence vault, PDF attachments. Cutting them mid-hackathon while everyone's still hyped is genuinely hard. Scope management is a real skill and we learned that the hard way.
MongoDB session headaches. Getting connect-mongo playing nicely with
express-session ate about an hour. Turned out to be a version mismatch we
completely overlooked. Classic.
What We Learned
The biggest takeaway: deterministic logic beats asking an LLM to make structural decisions. The claim classifier is just math — it doesn't hallucinate, doesn't drift, always gives the same answer for the same inputs. AI is great for interpretation. It should not be the thing deciding whether a claim is confirmed. That was worth learning early.
Also: every LLM output pipeline needs a fallback parser, no exceptions. And knowing what to cut from a demo matters just as much as knowing what to build.
What's Next
- Evidence vault — attach PDFs and source links directly to claims
- Multi-user collaboration with editor/viewer roles
- Timeline mode to visualize how a narrative drifts over time
- One-click PDF export so you can hand someone an actual brief
Built With
- bootstrap
- codex
- cursor
- express.js
- gemini-api
- github
- javascript
- langchain
- linear
- mongodb
- mongoose
- node.js
- passport.js
- pug
- scss/sass



Log in or sign up for Devpost to join the conversation.