-
-

-
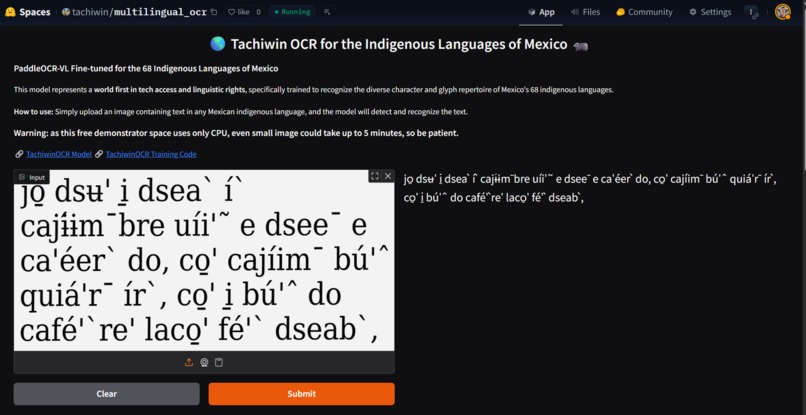
-
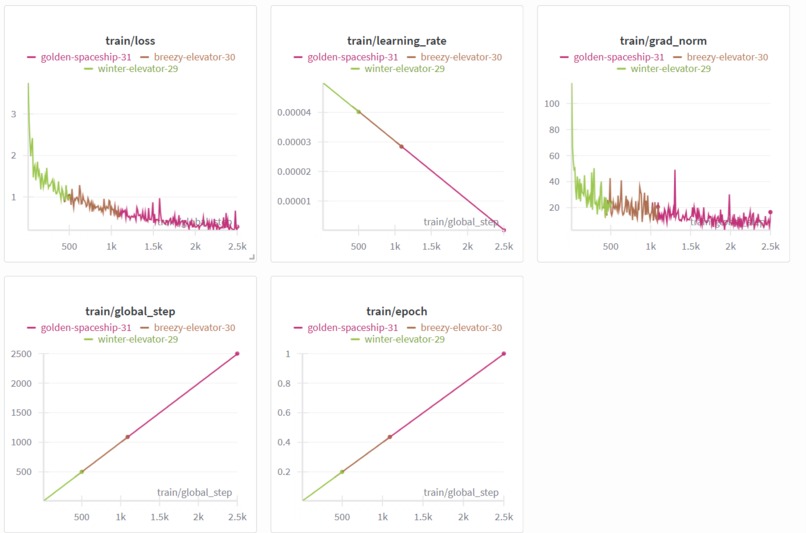
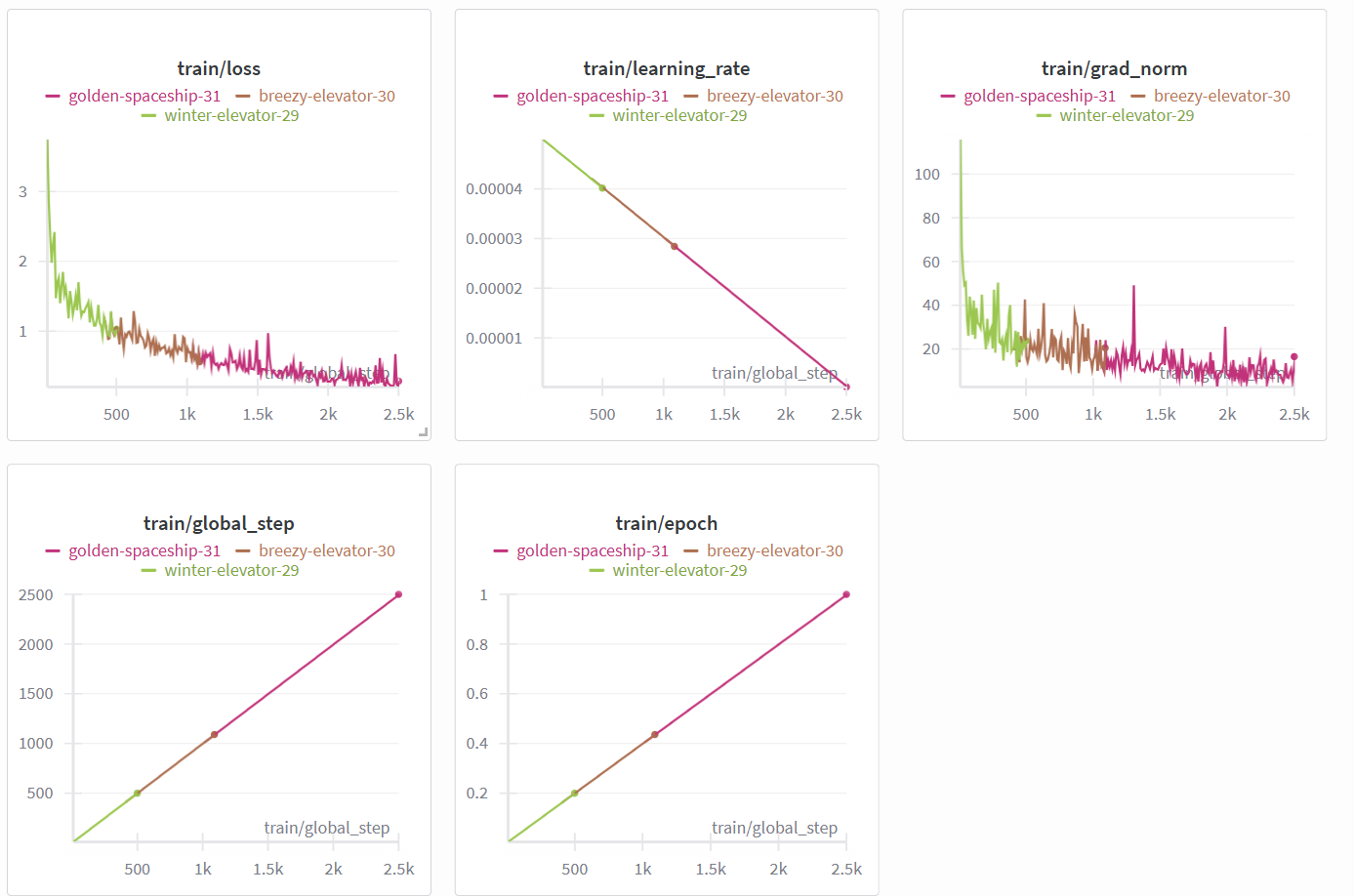
Training Panel depicting the adequate loss curve of the finetune
-
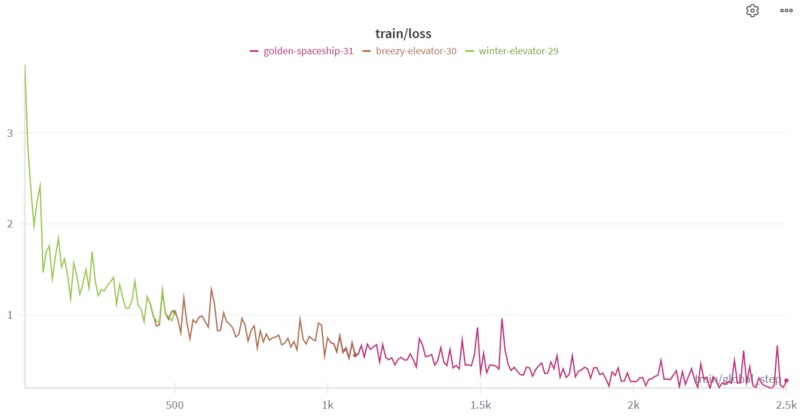
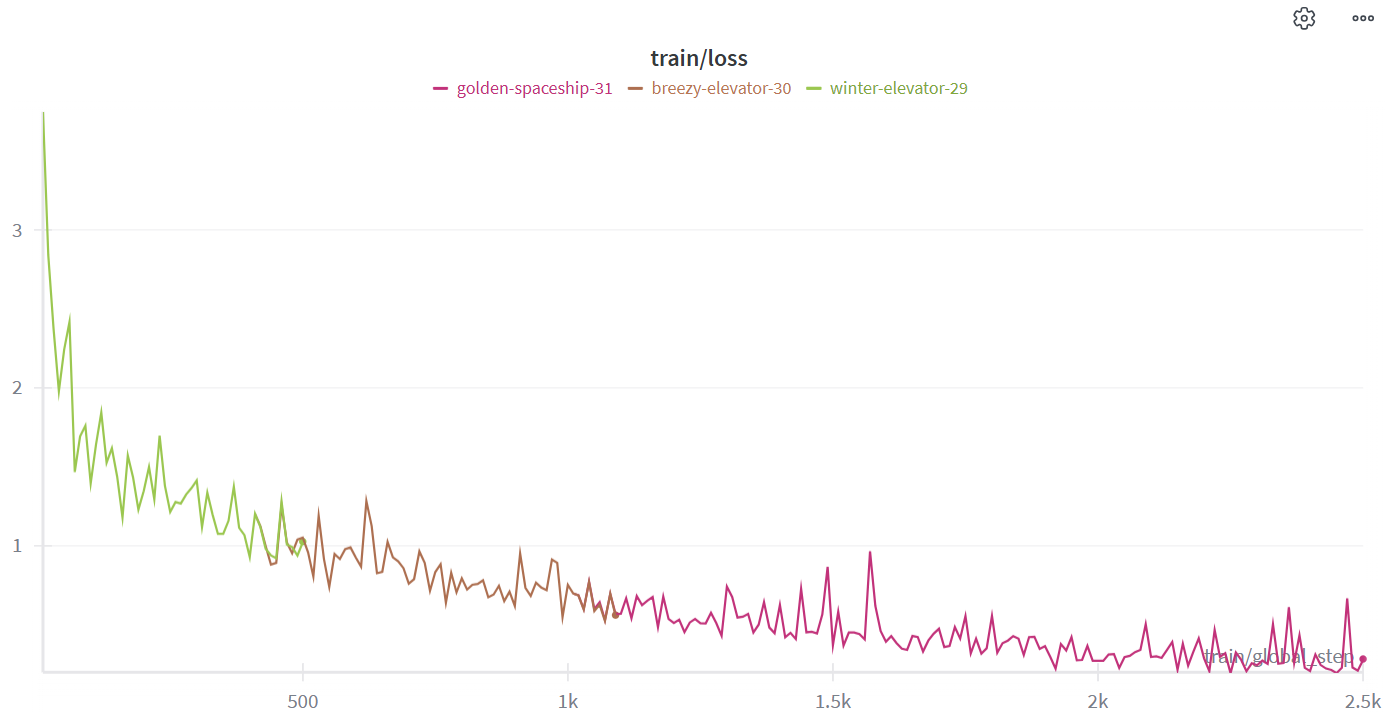
Closeup of the finetune train/loss curve
-
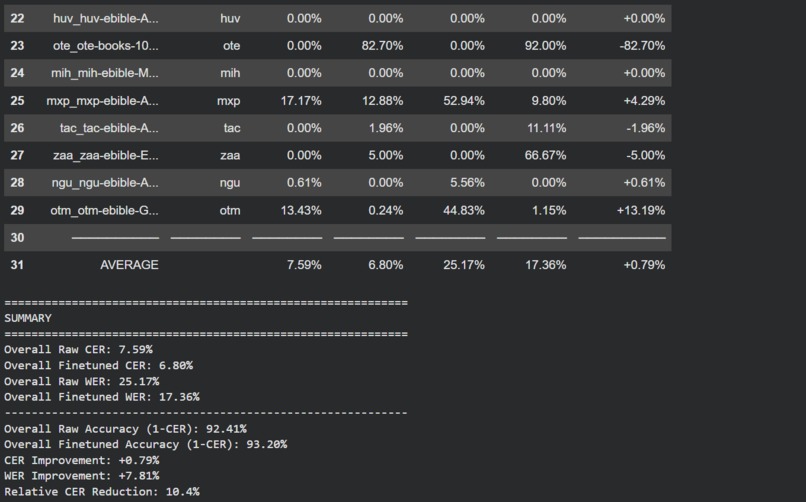
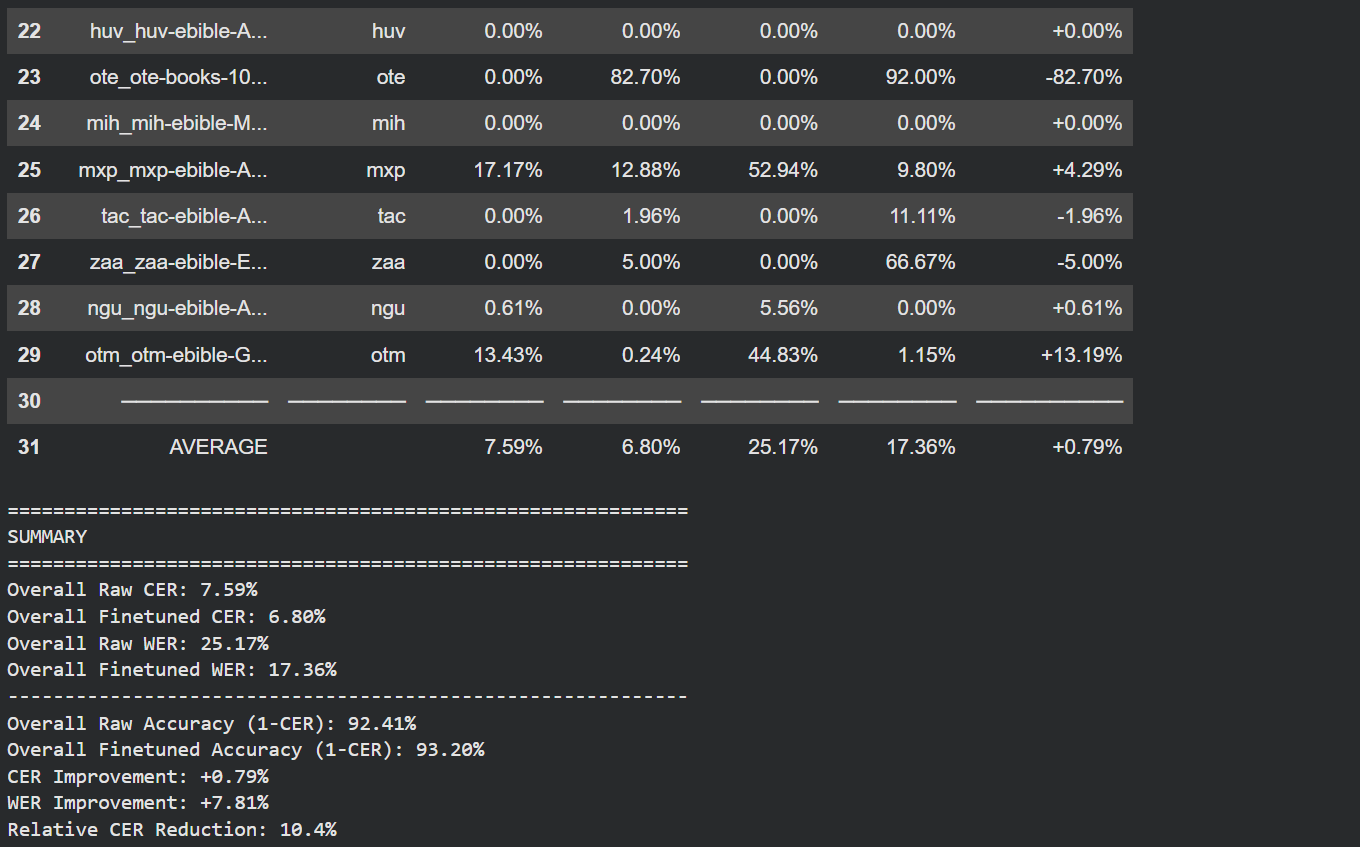
Benchmarks depicting 10% error reduction

Inspiration
The ancestral—yet still living—indigenous languages of Mexico face significant challenges in accessing modern technology such as AI. These languages are technologically underrepresented and do not yet possess the same level of digitized resources as mainstream languages, making it extremely difficult to develop technologies like large language models (LLMs) for them. Therefore, one of the first critical steps is creating OCR models capable of accurately parsing physical books into text, increasing dataset and corpus volume to enable further progress.
What it does
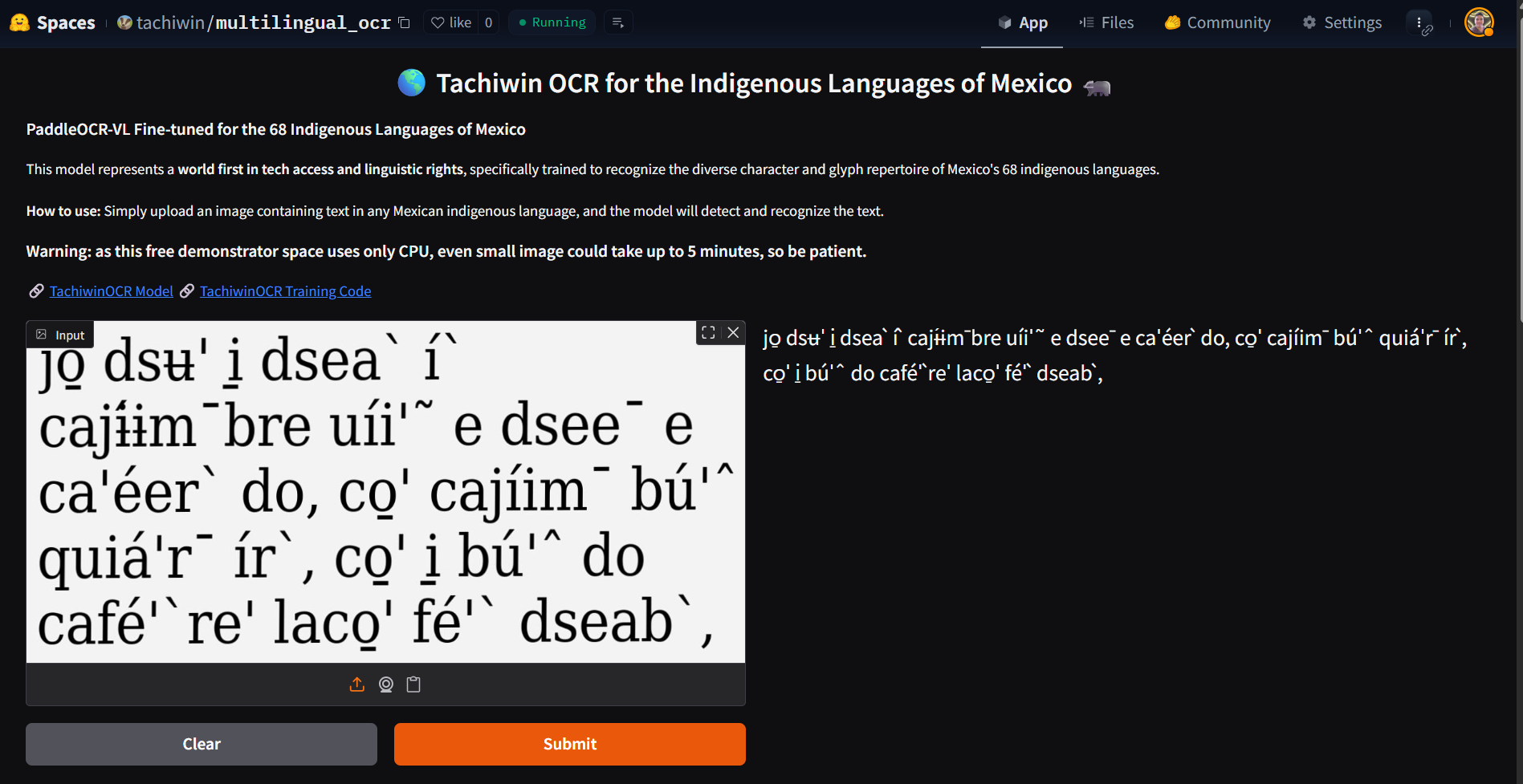
This project is a fine-tuned PaddleOCR-VL model that performs OCR (optical character recognition), transforming images into text while supporting non‑standard Latin characters that are very common in the indigenous languages of Mexico.
How we built it
We first created a synthetic dataset composed of 50,000 images containing text from all 68 indigenous languages of Mexico and their hundreds of variants. We then fine‑tuned a PaddleOCR‑VL model on this dataset.
Challenges we ran into
As a low‑resourced, non‑profit initiative, we currently lack funding and infrastructure. Training was done using free‑tier T4 GPUs and partially on V100 GPUs with limited memory, requiring extreme care to conserve GPU RAM in order to achieve effective training. Handling the enormous dataset and adapting our pipeline to these constraints was also a major challenge.
Accomplishments that we're proud of
Successfully training an effective OCR model through perseverance and ingenuity reducing error rate by 10%, despite having almost no resources beyond our own effort.
What we learned
We gained hands‑on experience with this new generation of OCR models, which show great promise, and explored the outcomes of different training strategies such as LoRA versus full fine‑tuning, as well as different training SDKs.
What's next for Tachiwin Indigenous Languages OCR
We plan to fine‑tune the model further using larger and more diverse datasets, and to expand into additional tasks such as text classification (identifying indigenous languages from text), text generation, and translation.
Built With
- erniesdk
- google-colab
- huggingface
- paddleocr-vl
- unsloth


Log in or sign up for Devpost to join the conversation.