-
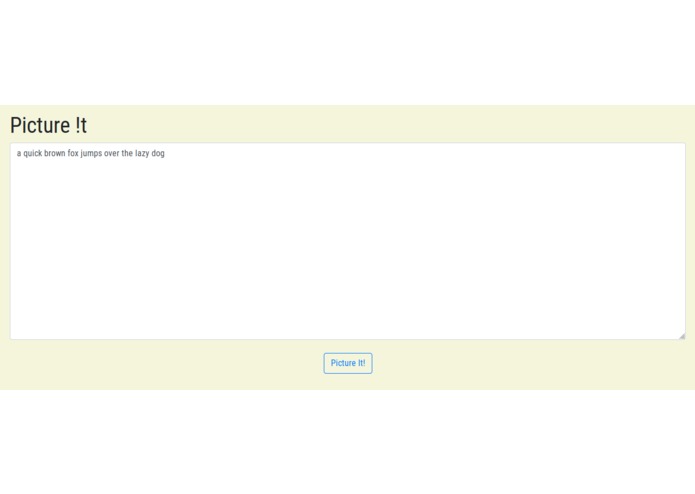
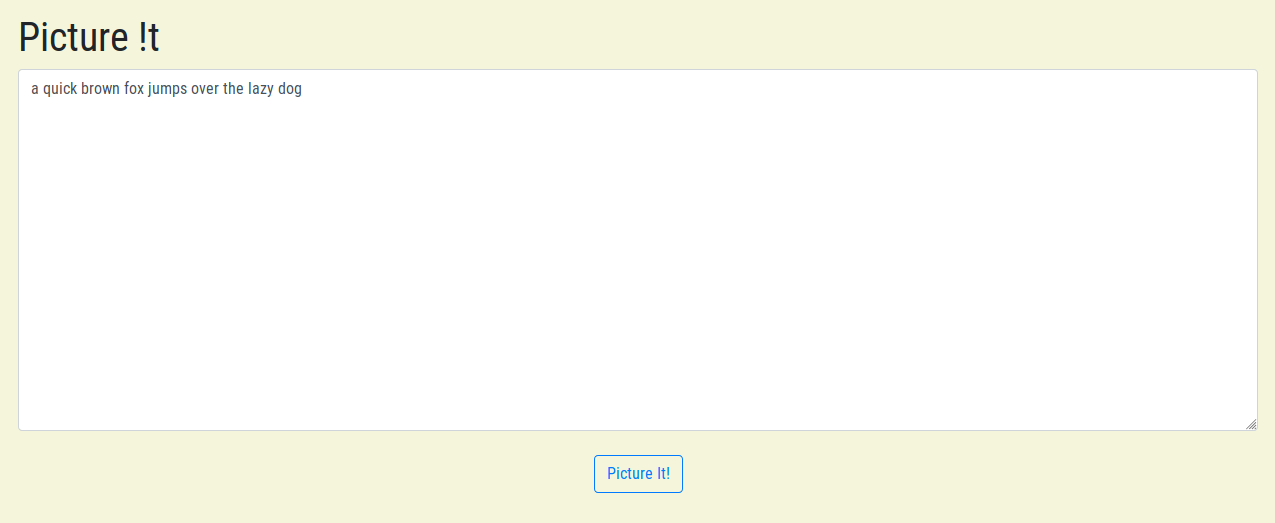
screenshot of our homepage
-
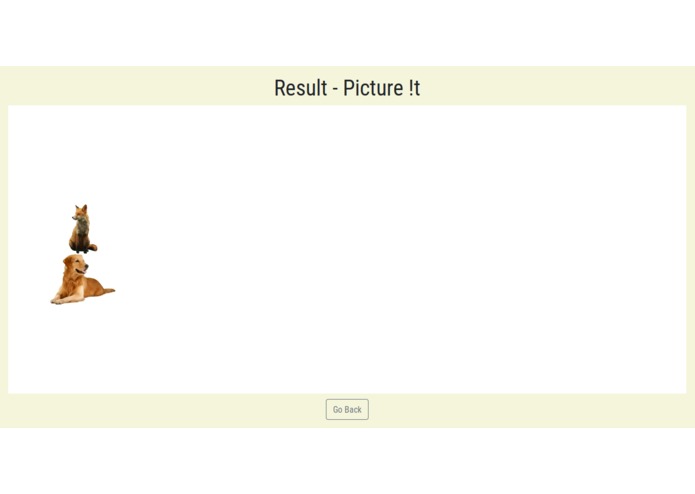
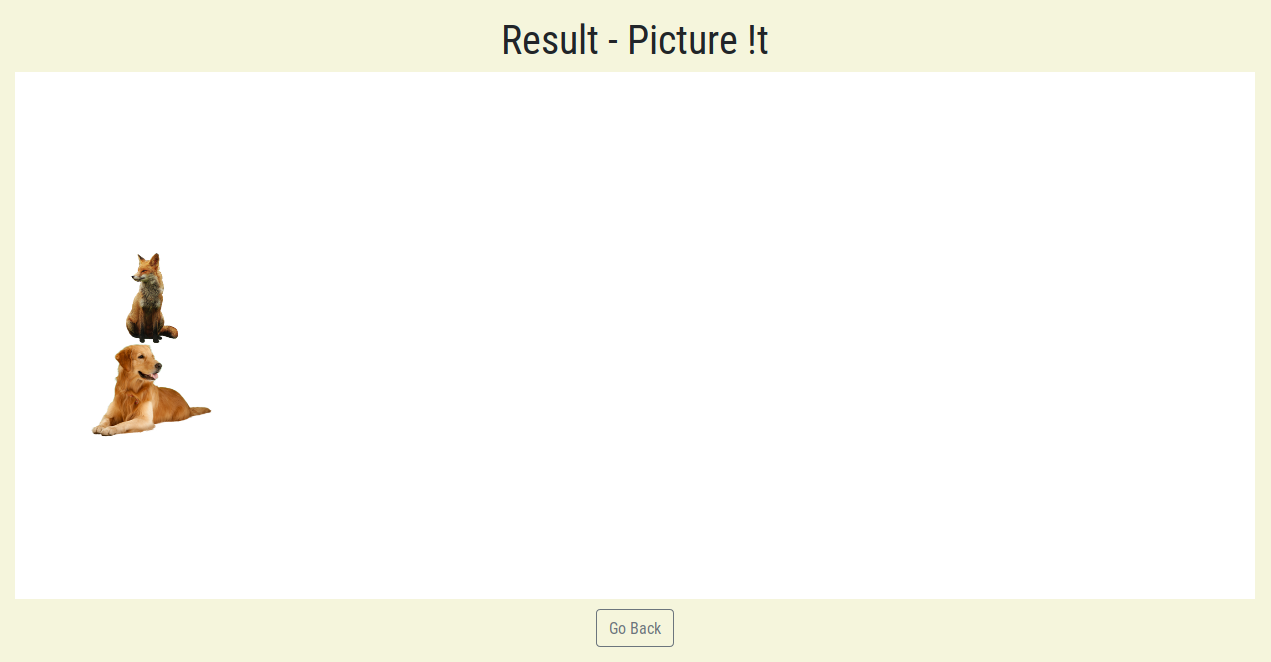
sample output
Inspiration
We already have technologies such as text-to-text translations and text-to-speech. However, for visual learners, there is no available tool to display the pictorial meaning of a sentence. With Picture !t, we hope to use our original approach to help learners of all ages with the difficult task of grasping a new language.
What it does
Picture !t takes a phrase or sentence as an input, and displays images that identify with the nouns from the phrase. These nouns are positioned based on prepositions in the sentence.
How we built it
We build Picture !t as a web application, with Node.js and Express.js back-end, and standard HTML/CSS (Bootstrap) front-end. We used the natural language processing library Compromise.js as a parser for the phrase.
Challenges we ran into
Compromise.js did not have a function/feature to identify and separate prepositions in a sentence. Therefore, we had to write our some of own NLP functionality to overcome this. Also, we had trouble with automating the finding and sizing of images to correspond with nouns, so we created a "dictionary" of possible word-image pairs.
What's next for t2v
One of the main future features that we would like to implement is the support of verbs in our phrases via basic animations. We'd also like to automate the image finding and sizing, so that any noun can be inputted into our program.
Built With
- compromise
- computer-vision
- css
- github
- html5
- javascript
- natural-language-processing

Log in or sign up for Devpost to join the conversation.