-
Login
-
Search Topic
-
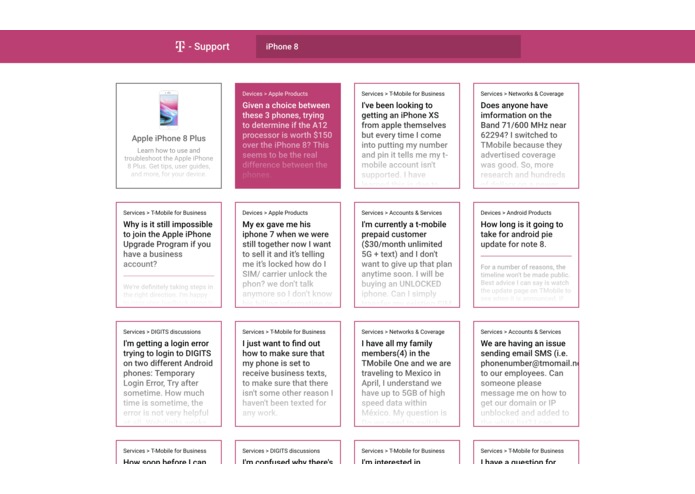
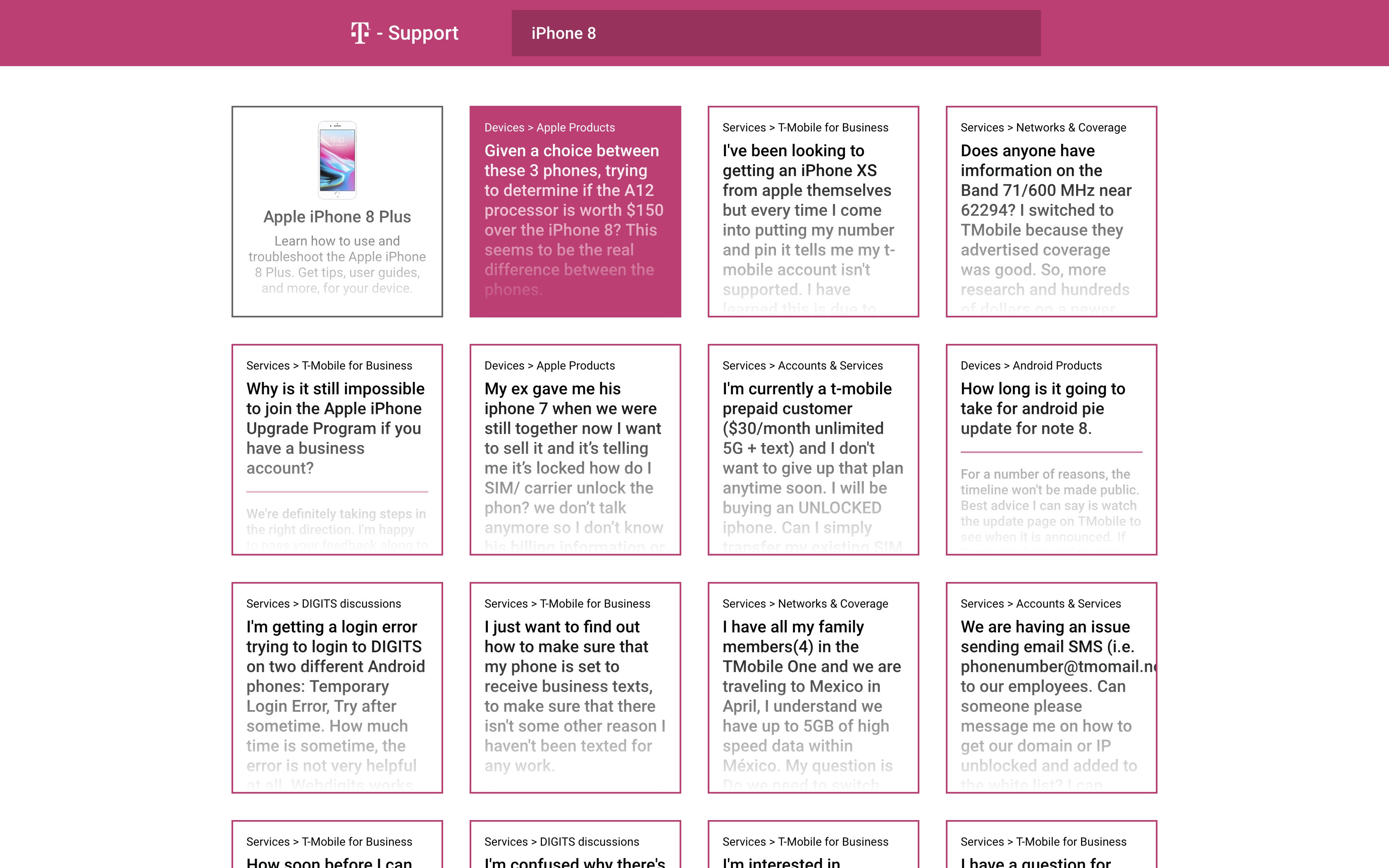
Classified Questions
-

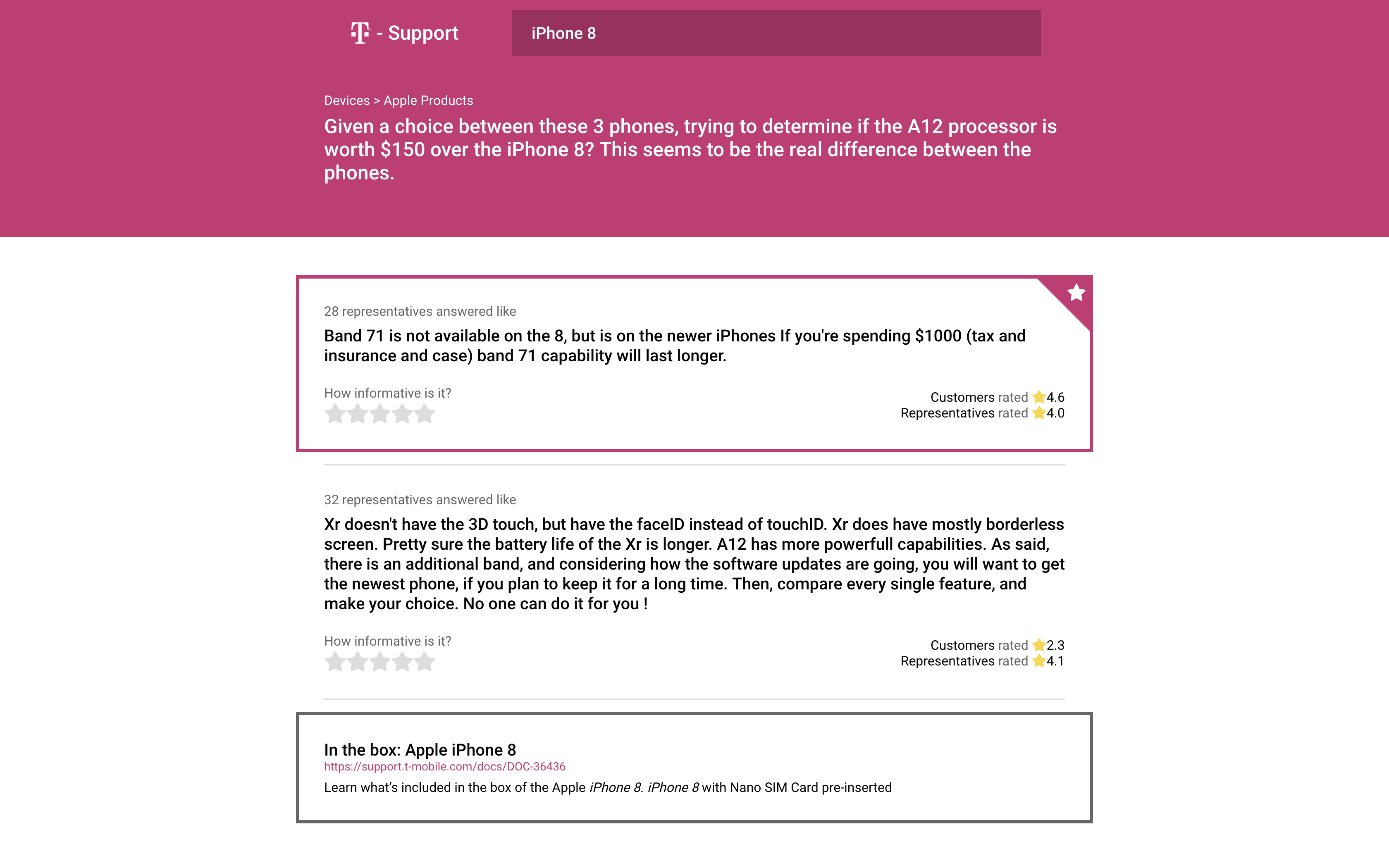
Classified Answers
-
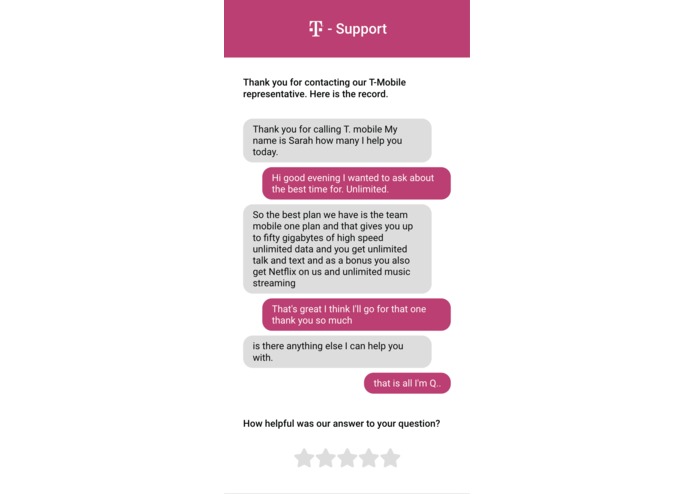
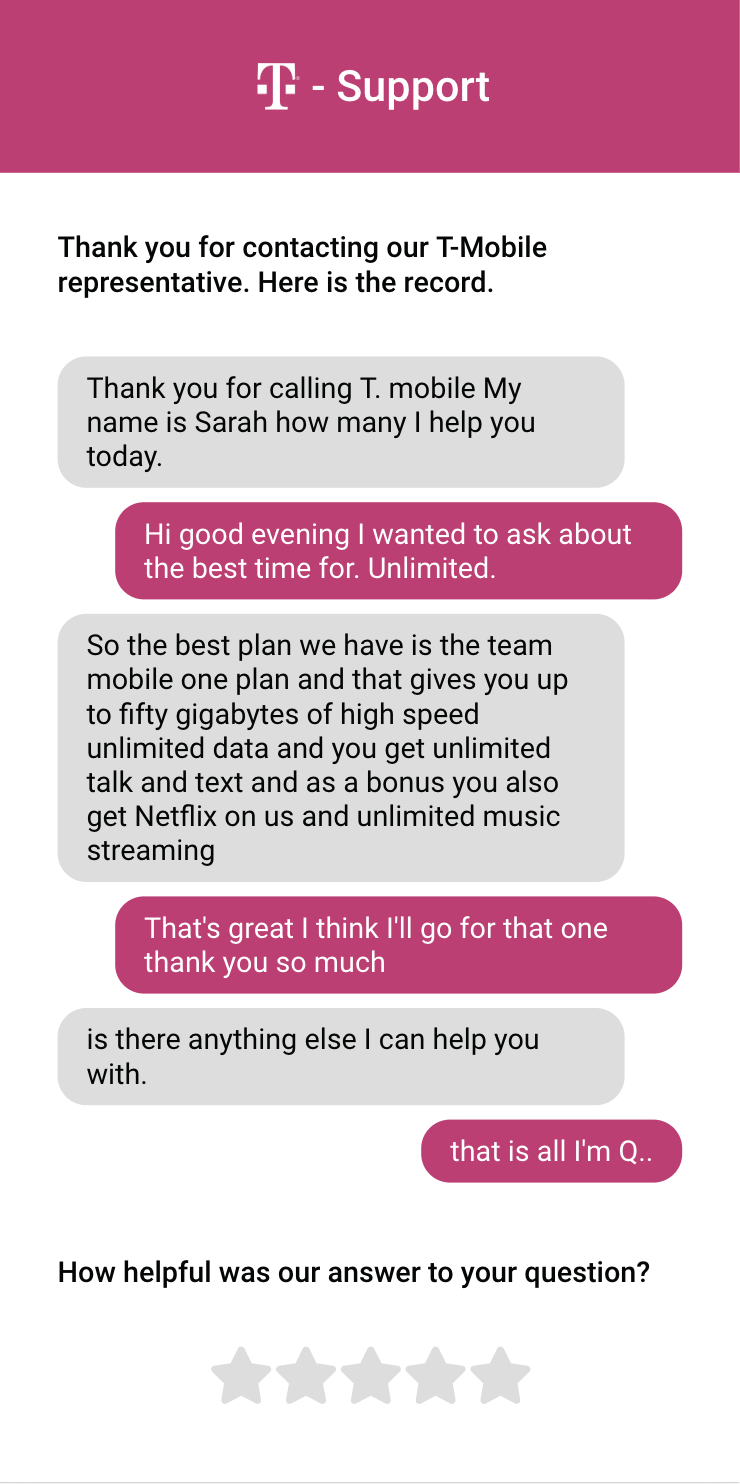
Customer Feedback

Inspiration
T-Mobile provides a multitude of customized solutions to its customers. To deliver the best customer experience, it only makes sense to provide a human assistant to help guide the customer to the right solution. However, although we like to think of T-mobile representatives as geniuses who can solve all of our wireless problems, they are just human and can't possibly memorize everything T-Mobile has to offer. To help T-Mobile representatives provide the most efficient customer service, T-Support helps a representative retrieve the information they need in order to effectively help the customer.
What it does
Using machine learning, T-Support compiles commonly asked questions over telephone calls and pairs them with the best answer given by a representative. Questions can have multiple answers and the best answer will be displayed directly beneath the question. Representatives in-store can search a certain topic or question and deliver the best answer to the customer. T-Support will also link relevant T-mobile website pages to help pull up the information most applicable to helping the customer.
How we built it
We used Twilio to create a transcript of a service phone call between a customer and T-Mobile representative. The question and answer are then separated into distinct text entities that are then sent to our server. We were able to categorize each entry using an Attention model on the sequence of words for each question. Using a pre-trained BERT model, our architecture performed well on our toy examples, updating our visualization with the output category.
Challenges we ran into
Implementing a reliable speech to text algorithm and classification of questions and answers. In particular, the deep Neural Network was difficult to tune, and we struggled with problems such as over-fitting, exploding gradients, and dying ReLU. The lack of a training set and the time constraints made fine-tuning our hyperparameters even more challenging.
Accomplishments that we're proud of
We were able to incorporate teammates of different computer science backgrounds. Each teammate was able to create something useful for the team whether it was their first hackathon or their twentieth.
What we learned
We learned about using voice to text API and about loading pre-trained models using Pytorch.
What's next for T-Support
We would like to scale our application to a much wider variety of question types and potential inputs. Some significant problems that we may run into the future include generalization to actual conversations and the classification of each conversation into question and answer categories. While we do have some idea of architectures that could combat these problems, without substantial training time and computing power, it is not realistic to implement these ideas.

Log in or sign up for Devpost to join the conversation.