-
-

MuzTrade Header
-
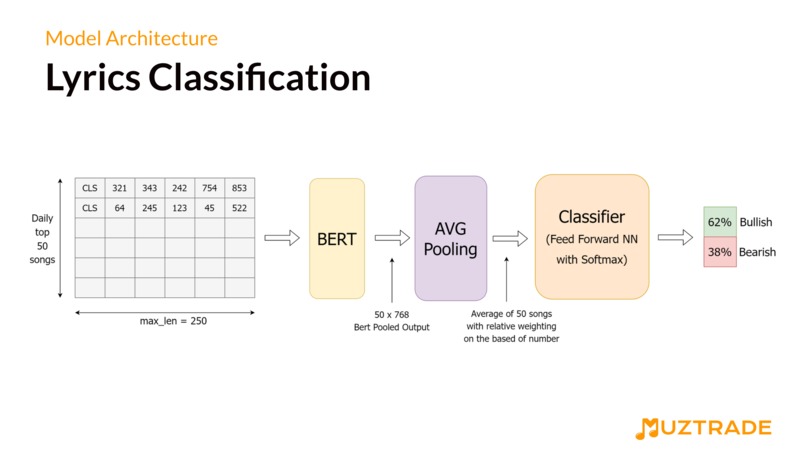
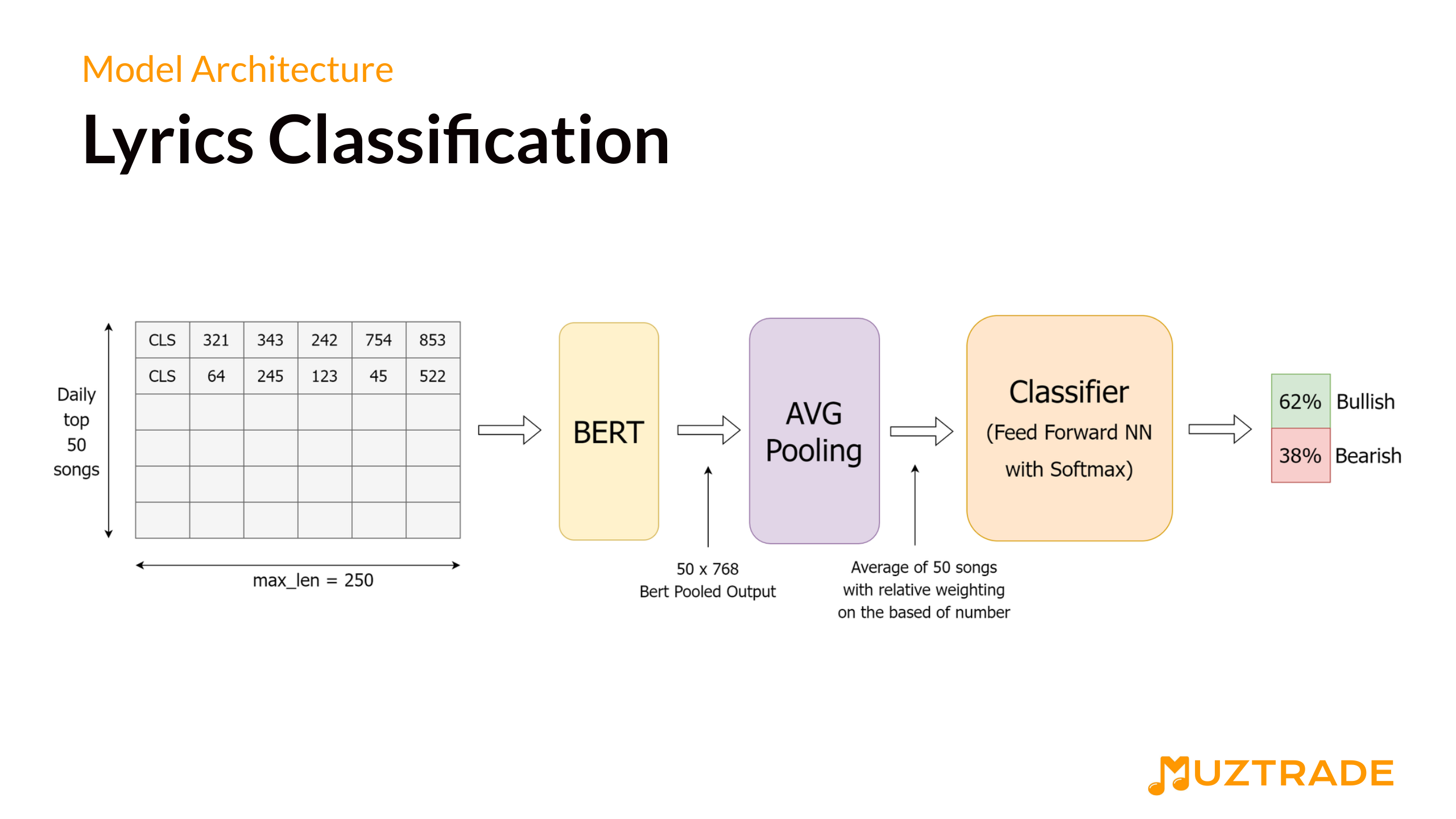
Lyrics Classifier
-

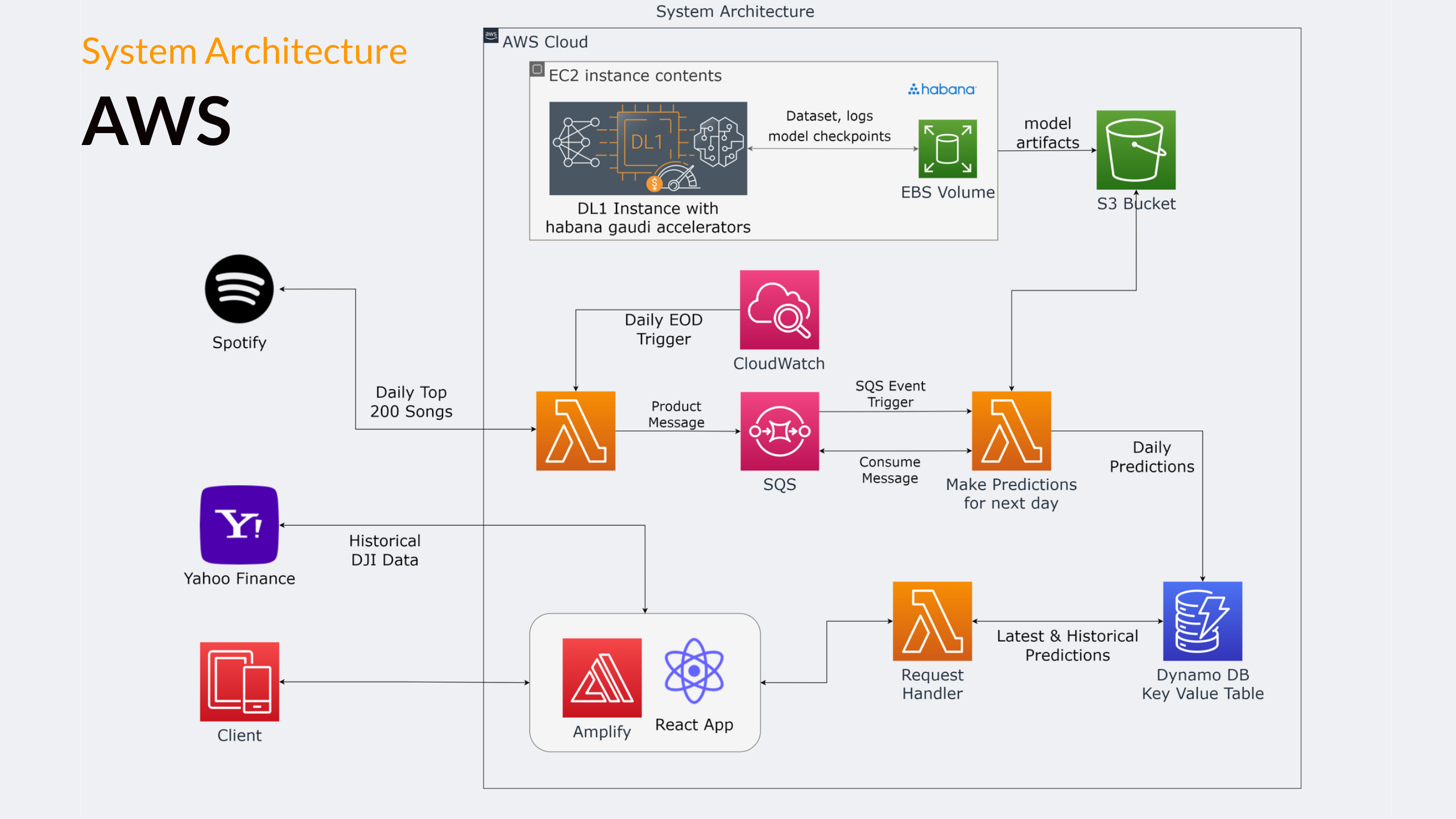
Deployment Diagram
-

Team
-
abc



Inspiration
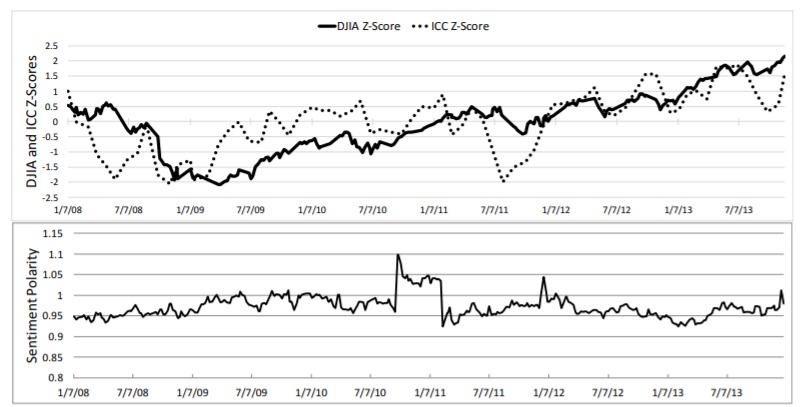
Would you be surprised if you get to know that the investor sentiment is backed up by music sentiment? We surely were surprised and conducted research and found that there are studies going on that aim to measure investor sentiment and study its impact on the stock returns. How cool would it be if we could predict tomorrow’s stock market direction based on the top songs that people listen to today? Many would agree that the success of top songs is due to a complicated mix of marketing, popularity, and blockbuster theory in which companies invest big money into a few products. Yet, we hypothesised that the lyrical sentiment of top songs can be viewed as transient, but a genuine snapshot of the public mood. There is a plethora of research that unequivocally confirms both the influence of mood on music choice and the influence of music on mood and even the buying behaviour of the investor (Areni and Kim, 1993; Bruner, 1990; Chen et al., 2007; R McCraty, 1998). While researchers in past have attempted to model public opinion indices and the stock market via sentiment analysis of news articles, microblogging, and social media sites, no research has taken this correlation-seeking approach using popular song lyrics until this research (Hit Songs' Sentiments Harness Public Mood & Predict Stock Market) was published back in 2016. In this paper, the authors explored the Billboard Hot 100 songs lyrics sentiment with the indicative of the public mood. They measured this by comparison to correlations with the Michigan Consumer Confidence Index (ICC). Moreover, they investigated whether the public mood measure is causally related to both the ICC and the Dow Jones Industrial Average (DJIA). They analysed lyrics based on positive and negative sentiment polarity. Visual analyses of trend plots showed a notable correlation between song lyrics sentiment and societal indicators.
!(https://devpost.com/0663dd84-20b6-4ff2-95ce-87c6532de9f6)[abc]
Therefore, in our project MuzTrade, we backed this research and tried to make predictions of the next day for the DJIA Index by exploiting the power of machine learning. Instead of using billboard top 100 lyrics, we thought of using the daily Top 200 Spotify chart data. Spotify is the world’s biggest music streaming platform by the number of subscribers and free listeners. Users of the service simply need to register to have access to one of the largest collections of music in history, plus podcasts and other audio content. Nevertheless, no one will argue that the Spotify charts will justify the near true mood of the public.
What it does
Using the power of the state of the art pre-trained BERT Model, MuzTrade helps investors to anticipate how the stock market will perform the next day based on the sentiments of the top 200 most streamed songs for the day. The core heart of MuzTrade is the ML model that helps it make the prediction of the direction of the DJIA Index. Furthermore, it has a react based web app that shows the daily & historical predictions from the model along with the actual historical movement of the DJIA Index. Our system daily fetches the top 200 songs from spotify and their lyrics from Genius.com and makes predictions out of it. These predictions persist in the DynamoDB in AWS cloud. Users can visit the web app anytime to see the quick results. Our application follows the microservice architecture and each and every functionality works independent of each other.
How we built it
Dataset We got the Spotify daily top 200 songs data from Kaggle from January 2017 till July 2021 and we further scraped top 200 songs for each day from August 2021 till Feb 2022 from the Spotify charts. And, their lyrics were scraped from genius.com. The lyrics were pre-processed and cleaned. Then top 50 songs for each day are considered in the final dataset. This is because the daily top 200 songs might repeat if their rank shuffles within 200 and we won’t get a lot of variety. For example - a song whose rank is 22 today might have a rank of 134 tomorrow and for both days it’ll be in the top 200 list. But if we consider the top 50 songs this will not happen. Therefore, the uniqueness of data increases if we consider the top 50 songs of the day. The dataset consists of the song name, artist, streams - number of times songs streamed(which decides the rank of the song), lyrics, date of the top 50 songs, genre and label(target) - where 1 indicates market is bullish and -1 indicates bearish based on the value of DJIA index for the previous date because today’s songs will influence tomorrow’s index. The value of the label is calculated from DJIA Index value obtained from Yahoo Finance.
Model The pre-trained model used is the BERT model from transformers library - NLP library by hugging face. The lyrics from the dataset are used to predict the Dow Jones Industrial Average Index (DJIA Index) for the next day. We split the songs data for each date into train and test data. Each lyric is fed to the Bert Model tokenizer that pre-processes the lyrics and this pre-processed text is passed to the BERT model for fine-tuning. Our Lyrics Sentiment Classifier uses the BERT model and a special mapping layer at the end of the model that maps bert output 768 (bert base model) to 1213 (number of unique days since we predict the index for each day). Then the linear classifier layer classifies this text into 1 or 0, where 1 indicates the market will be bullish and 0 indicates the market will be bearish.
Deployment The model is trained using powerful Amazon EC2 DL1 instances powered by Gaudi accelerators from Habana Labs that provide up to 40% better price performance for training deep learning models compared to current generation GPU-based EC2 instances. After that, the trained model is stored in the S3 bucket for making further predictions. To make the daily predictions we have incorporated the AWS Cloudwatch which triggers the Lambda Functions to scrape the top 200 songs from daily Spotify charts and their corresponding lyrics from Genius.com. Then this Lambda produces a message to the AWS SQS which invokes another Lambda function to make the predictions out of the fetched data. This Lambda function utilises the data and weights of the trained model from the S3 bucket to predict the direction of the DJIA index for the next day. This predicted value (as previously predicted values) gets stored in the DynamoDB. We have utilised the Lambda functions in our architecture for their serverless functioning that provides automatic scaling & cost effective solution. The react app will then display a comparison chart of predicted DJIA Index versus actual DJIA index until the previous day. The DJIA Index data is fetched from Yahoo Finance.
Challenges we ran into
- Dataset for daily top 200 songs by Spotify was available from January 2017 till July 2021 which was very small. So we had a hard time scraping the daily top songs from August 2021 till February 2022 to increase our dataset.
- There were no Spotify APIs available to get song lyrics, so we had to scrape lyrics from another website - genius.com using the song name and artist name derived from Spotify.
- We lost $60 in setting up the DL1 instance. Really had a hard time setting up the instance with Habana AMI since there is no proper documentation regarding setting the instances with Habana drivers.
- We both are working professionals, so we went out of our way beyond working hours to complete this project.
Accomplishments that we're proud of
- There were ready-made python libraries to scrape song lyrics, but none of them worked for us. So we wrote our own lyrics scrapper.
- The BERT model was a new concept for us. We understood the architecture of the model and were able to fine-tune the model for our use case.
- This was the first project where we used an AWS DL1 instance to train our model & pretty satisfied with the end results.
What we learned
- It was the first time that we worked with a transformer-based bi-directional model whose language model learns the context of the word in both forward and backward directions unlike directional models that follow reading text sequentially in a single direction like left-to-right or right-to-left.
- We fine-tuned this BERT model for our use case and learnt how to map the BERT output to predict the direction of the DJIA.
What's next for MuzTrade - Hit Songs Sentiment & Stock Market Prediction
- Language Support - Some songs in the list of the top songs were not English, but other languages like Spanish, French. So non-English songs need to be translated to English to achieve better accuracy.
- Augmenting dataset - to train the model using new songs periodically for better prediction. Additionally, include daily tweets and news articles for making the model more robust.
- Expand predictions - predict stock market indices of global markets.
- Notify daily predictions - provide a feature to get the daily predictions over email.
- Improvising the model training - train the model to accommodate negations and modifiers around the sentiment word to determine the correct sentiment of the song. For instance, ‘I am not happy’ is a negative sentiment because of the negation ‘not’ before the sentiment ‘happy’.








Log in or sign up for Devpost to join the conversation.