-
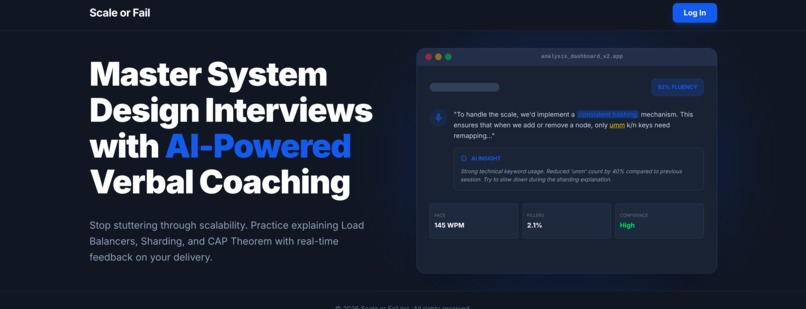
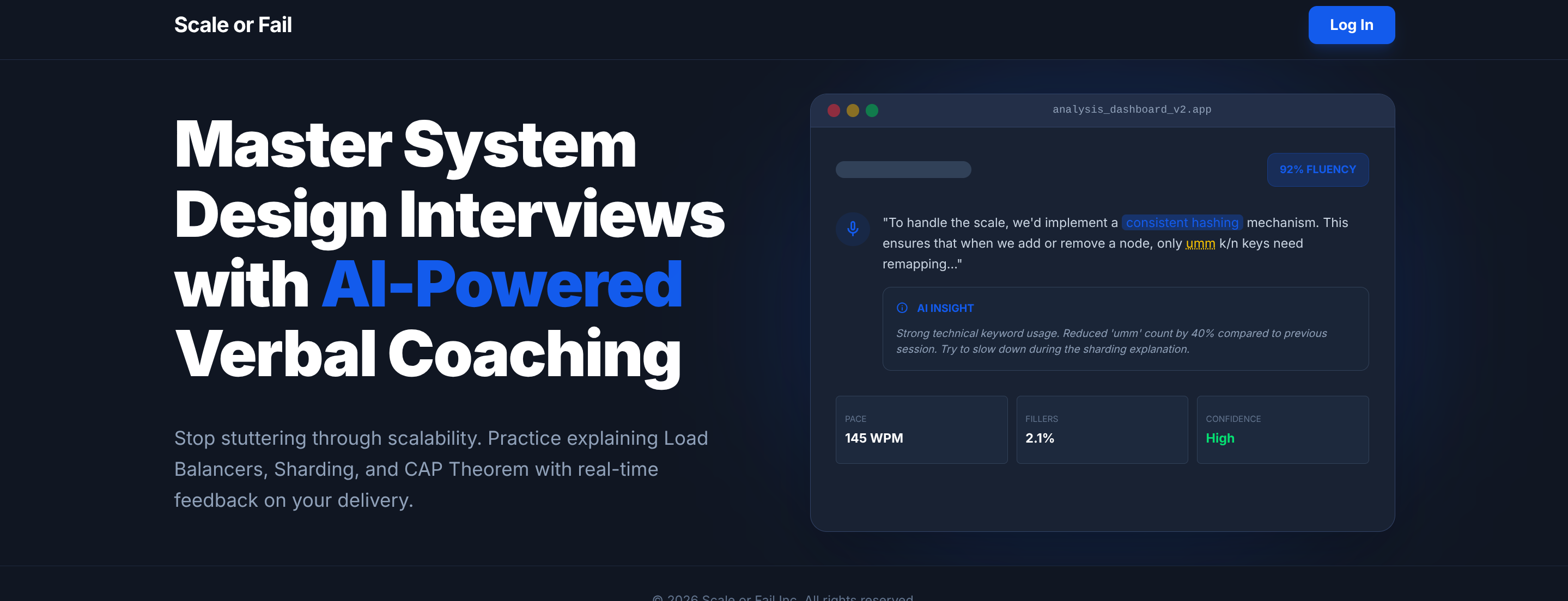
Home page
-
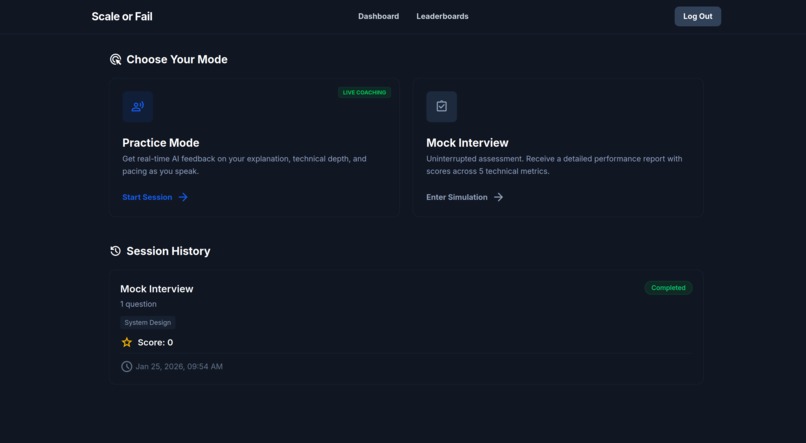
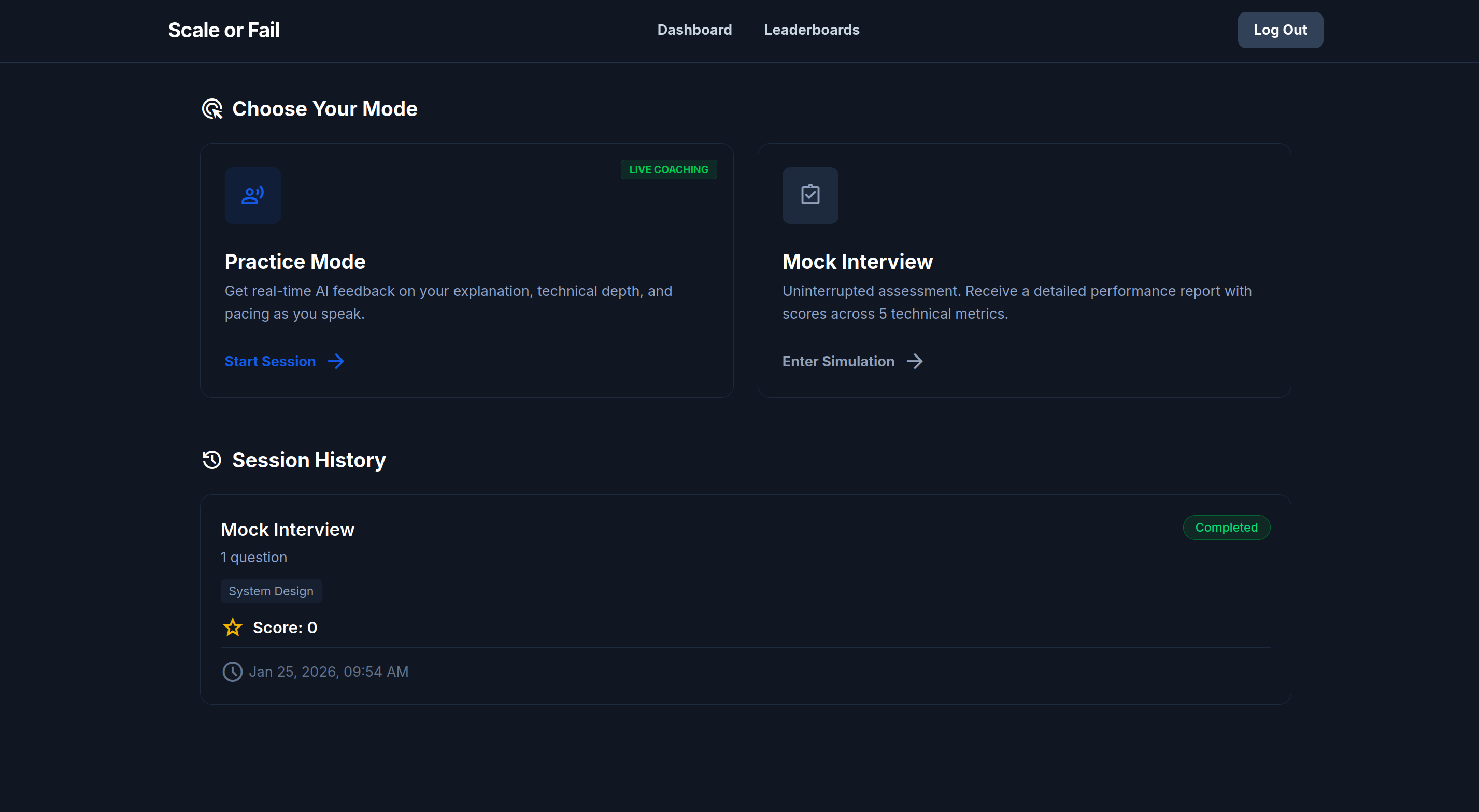
Dashboard
-
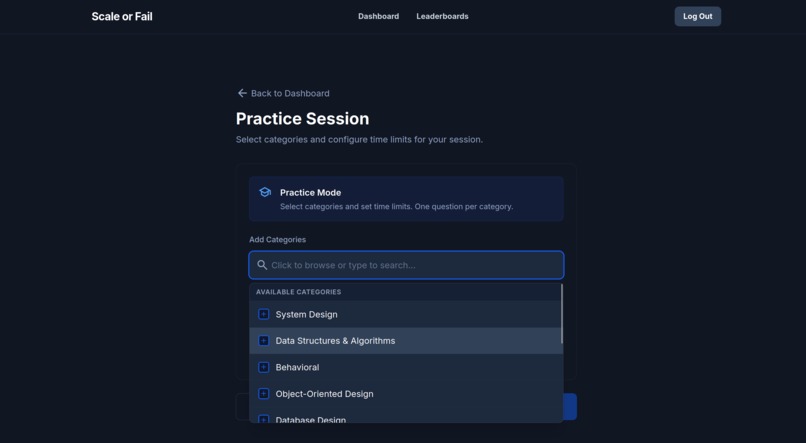
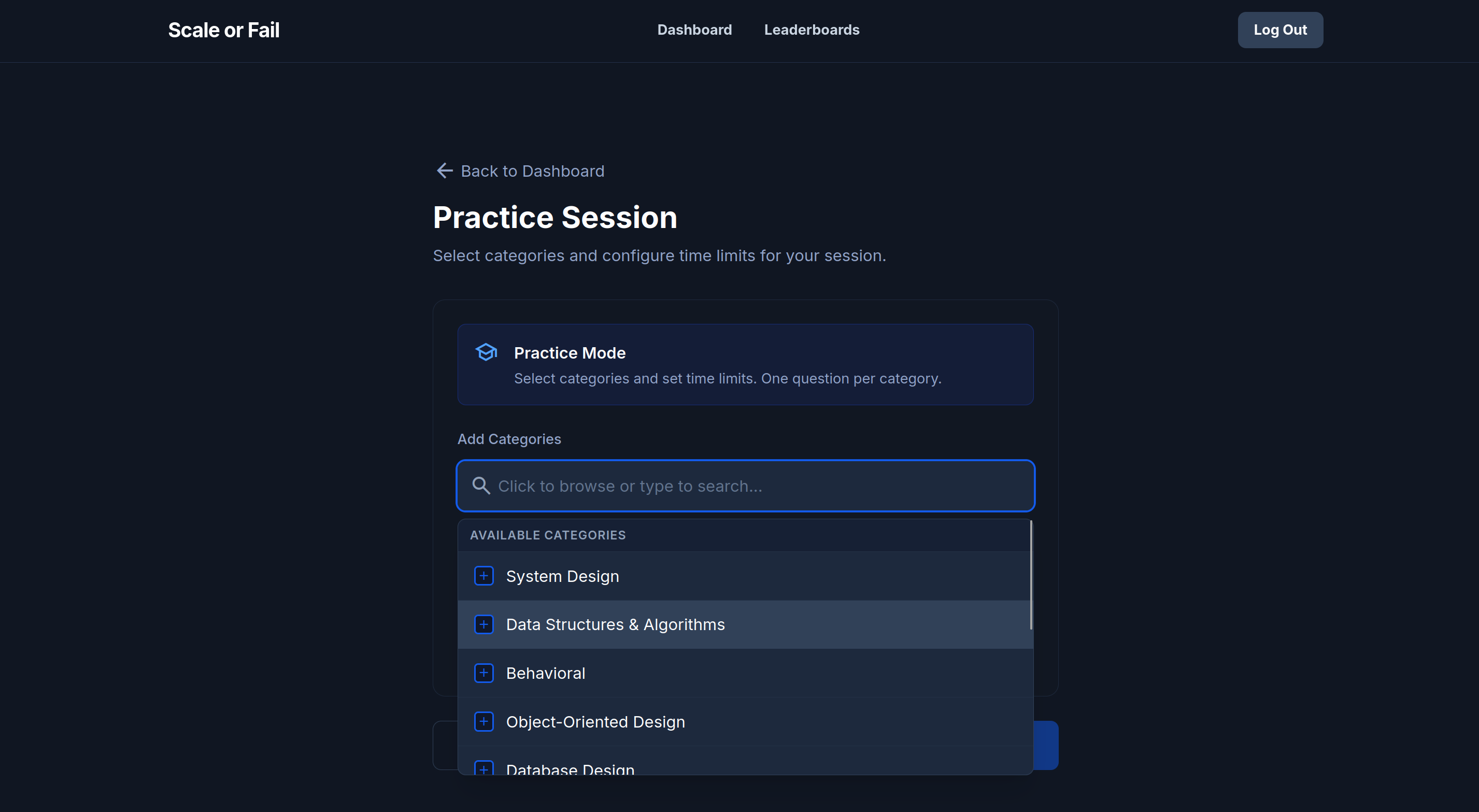
Practice Session
-
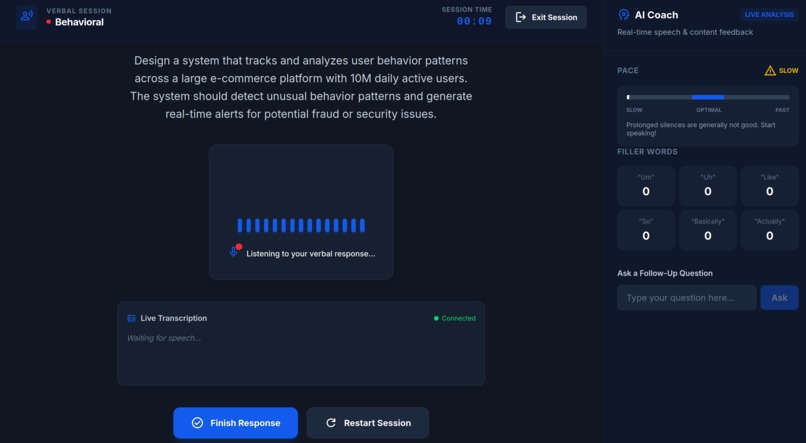
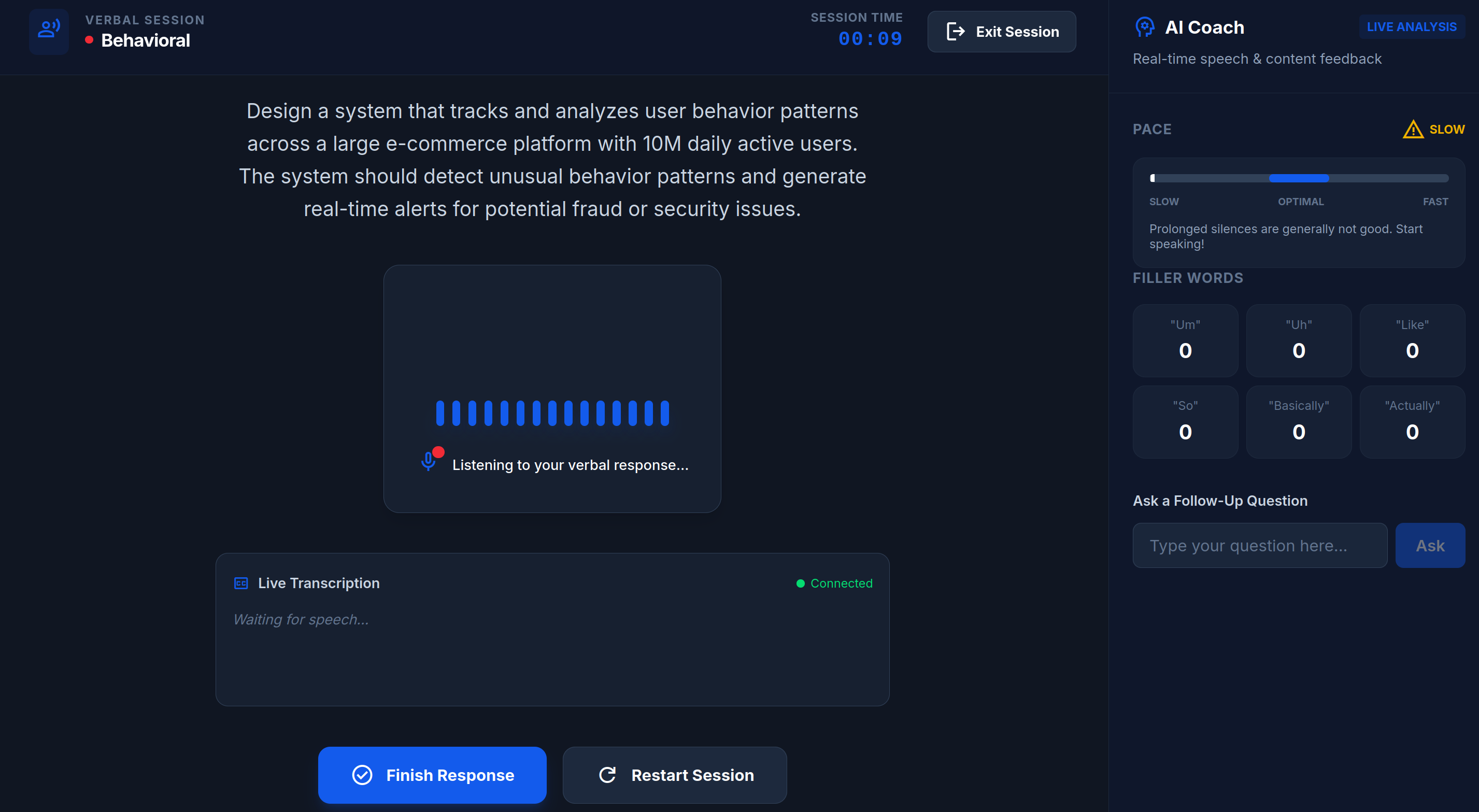
During session
Inspiration
In the past couple of years with the boom of AI System design interview invitations have gone up by more than 100 percent since 2024 according to (hackerrank)[https://www.hackerrank.com/blog/why-system-design-is-surging-in-the-age-of-ai/]. While there are many resources online to help technical professionals brush up on their design patterns, finding resources that adequately prepare you by simulating high-pressure, verbal interview environments is nearly impossible. We wanted to build a tool that moves beyond static reading and into active, vocal practice.
What it does
Scale Or Fail is a voice-first interview preparation platform. Users are presented with complex architectural problems and must explain their solutions out loud. The system transcribes the audio in real-time, uses specialized AI agents to analyze the logic, and provides a comprehensive grade based on industry-standard rubrics. It's the difference between knowing a concept and being able to defend it under pressure.
How we built it
Frontend (Angular & TypeScript)
We built a interactive dashboard using Angular and TypeScript to manage the user’s interview session and visualize the feedback loops. We prioritized a clean UI that doesn't distract the user during the "hot seat" simulation.
Backend (C# .net Core 10.0)
The engine of the application is a C# .NET 10 API. It acts as the central orchestrator, managing user sessions, state, follow-up questions, and secure communication with Snowflake’s stored procedures to trigger the AI grading logic.
Authentication (Auth0)
Security and user identity are handled by Auth0. We implemented a robust OAuth2 flow to secure our API endpoints and manage user profiles, ensuring that interview history and performance metrics remain private and persistent.
STT (Speech to Text) & TTS (Text to Speech) Runner (Python & C#)
To handle the "voice" of the interview, we utilized Python with the Azure Voice Speech services API to handle our speech to text. For our Text to Speech we used two different providers allowing us to take the quickest response from our providers to give our users the best experience. We used Speech to Text from Eleven Labs and we deployed a Vultr Serverless Inference instance to enable GPU enabled text to speech capabilities.
AI Tasks (Snowflake)
We leveraged Snowflake not just for data, but as our AI execution environment. We developed a RAG (Retrieval-Augmented Generation) pipeline and 6 distinct agent procedures that evaluate transcripts, check for architectural bottlenecks, and determine if the user successfully "scaled" their design or "failed" the prompt.
CI/CD & Deployment (Vultr, GitHub Actions, & Watchtower)
The infrastructure is fully containerized and hosted on Vultr. We implemented a modern, automated CI/CD pipeline:
Build: Every push to the main branch triggers a GitHub Action that builds 3 Docker images (API, Frontend, and Python Runner).
Registry: These images are pushed to the Vultr Container Registry.
Auto-Update: On our Vultr VM, we deployed Watchtower. It monitors our image tags in the registry and, upon detecting a new push, automatically pulls the latest images and swaps out the containers. This ensures our hosted services are always running the latest code without manual intervention.
Deployment (Vultr)
The entire infrastructure is hosted on Vultr, utilizing their high-performance compute instances to ensure the transcription and AI processing remain as low-latency as possible. We also took advantage of Vultr's Object Storage to store the pdf system design documents that we found online to build our system design knowledge base in Snowflake to run a RAG pipeline running cosine similarity then used to create a strict grading scheme for the LLM allowing it to accurately grade and constructively critique users responses.
Challenges we ran into
Agent Orchestration: Creating autonomous agents within SQL and Python-based procedures in Snowflake required a deep dive into Snowflake's specialized environment.
The "Black Box" Debugging: Debugging Snowflake was a significant hurdle; without a traditional step-through debugger, we had to get creative with logging to identify where procedures were breaking.
Networking Infrastructure: Configuring SSL for a .tech domain and establishing secure, stable connections between our Vultr-hosted services and the Snowflake data cloud.
Latency Management: Minimizing the "dead air" between a user finishing their sentence and the AI agent providing a follow-up question.
Accomplishments that we're proud of
Successfully getting 6 distinct agent procedures up and running within Snowflake to handle complex grading logic.
The RAG Pipeline: Creating a robust RAG pipeline that allows the AI to reference specific system design best practices when critiquing a user’s answer.
Seamless Integration: Bridging the gap between a modern C# .NET 10 backend and specialized Python STT runners.
What we learned
Snowflake is more than a Data Warehouse: We learned how to treat Snowflake as a powerful compute engine for AI tasks, despite the unique debugging challenges.
Architectural Trade-offs: Building an app about system design forced us to make our own system design decisions regarding latency vs. accuracy in transcription.
DevOps Resilience: Deploying on Vultr and managing custom SSL configurations provided hands-on experience in the "last mile" of software delivery.
What's next for system design
We want to improve our connections to our AI agents and further reduce response latency to make the conversation feel even more natural. We also plan to deploy on GPUs within a VPC to speed up our Whisper transcription and move toward a fully real-time, multi-modal interview experience.
Built With
- angular.js
- c#
- docker
- mongodb
- python
- snowflake
- vultr





Log in or sign up for Devpost to join the conversation.