Inspiration
System calls form the bridge between user-space programs and the Linux kernel. Each syscall involves privilege-level switching, stack changes, and bookkeeping that contribute to latency.
Traditional tools like strace and perf introduce additional context switches and overhead that distort measurements, and they require users to know the exact tracepoint names.
A major challenge for developers is that library functions internally invoke many system calls that users are unaware of. For example, standard I/O, networking, and threading functions make hidden syscalls whose latency directly affects performance.
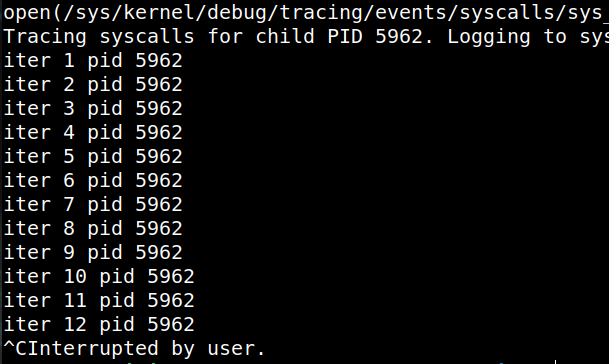
Our goal was to build a beginner-friendly eBPF-based tracer that precisely measures syscall latency directly inside the kernel — even when the user does not know which syscalls are being invoked — and automatically discovers and attaches the correct tracepoints without requiring kernel-level knowledge.
The result is Syscall Latency eLiteTrace, a low-overhead, two-phase tracing framework that not only identifies which syscalls are being made by any binary or library function but also measures their latency with nanosecond precision.
What it does
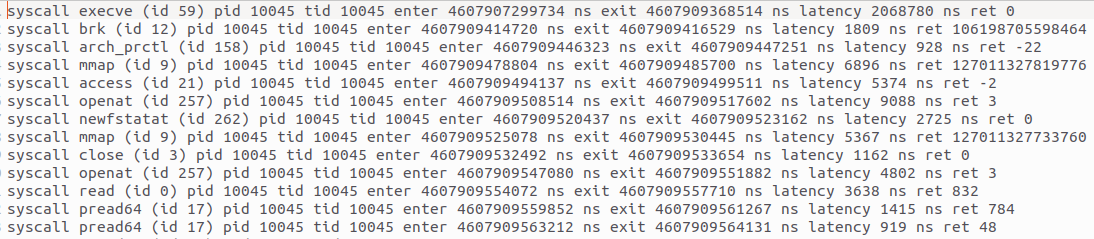
Syscall Latency eLiteTrace measures and reports how long each system call spends inside the kernel with nanosecond precision.
It is designed so users do not need to know which syscalls their program (or its libraries) actually invokes — the tool discovers them automatically and instruments only the relevant ones.
It operates in two phases:
Discovery phase:
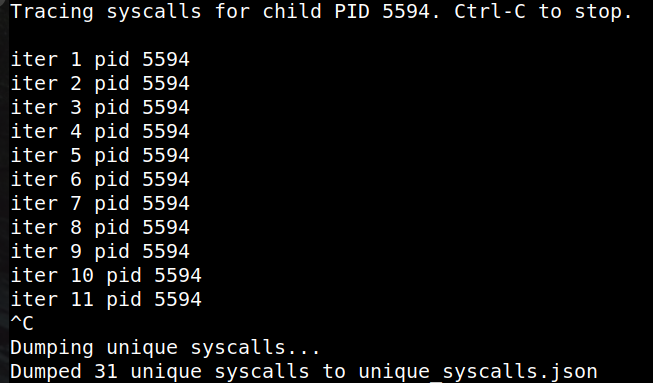
Uses the earliest syscall tracepoint (raw_syscalls:sys_enter) to automatically identify every unique syscall the target process invokes — including syscalls made implicitly by library functions.
This eliminates the need to attach to all ~700 syscall tracepoints in the kernel, avoiding massive overhead.Latency phase:
Automatically attaches to the specificsys_enterandsys_exittracepoints corresponding to just the discovered syscalls and captures kernel-local entry and exit timestamps.
A critical part of the design is parent–child synchronization using a UNIX pipe.
After fork(), the child process blocks until the parent writes its PID into the BPF map. Only then is the child allowed to exec the target program.
This ensures no early syscalls are missed, and the tracer captures the very first syscall made by the target binary.
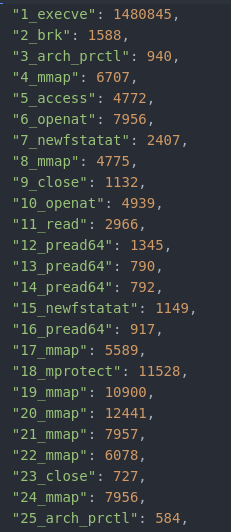
The final output is a structured JSON/CSV report that lists syscall names, IDs, latency per invocation, and aggregated statistics.
This makes the tool especially useful for understanding hidden syscalls invoked by libraries and for pinpointing where applications spend time inside the kernel.
How we built it
- Implemented in Python using the BCC (BPF Compiler Collection) framework to load and manage eBPF programs.
- eBPF programs were written in C and attached to kernel tracepoints for syscall entry and exit.
- BPF maps were used as shared kernel–user structures for PID filtering, syscall discovery, and timestamp storage.
- Used
bpf_ktime_get_ns()to obtain kernel-local nanosecond timestamps without user-space scheduling noise. - Added an automatic tracepoint attachment mechanism that tries syscall name variants and falls back to generic handlers when needed, removing all manual effort from users.
- Implemented parent–child synchronization using a UNIX pipe: immediately after
fork(), the child blocks on aread(), the parent writes the child PID into the BPF map, and only then unblocks the child toexec.
This ensures tracing starts only after PID registration, guaranteeing that no initial syscalls are missed. - Designed the system to transparently handle syscalls invoked indirectly by library functions, giving full visibility into program-to-kernel interactions without requiring expert knowledge.
Challenges we ran into
- Handling kernel version differences and syscall naming inconsistencies across distributions.
- Preventing lost syscalls when a child process executes before being registered in the BPF PID map.
- Staying within eBPF verifier constraints (bounded loops, limited stack size).
- Managing BPF map memory efficiently for long-running or high-frequency workloads.
- Achieving nanosecond-level precision under multi-threaded workloads while keeping overhead minimal.
Accomplishments that we're proud of
- Built a kernel-level latency tracer achieving nanosecond precision with negligible overhead.
- Created a two-phase automated workflow that avoids attaching to hundreds of unnecessary tracepoints.
- Implemented deterministic startup synchronization using UNIX pipes to prevent early syscall loss.
- Validated tracer accuracy and low overhead compared to traditional tools like
strace. - Delivered a beginner-friendly command-line tool that exposes hidden syscall behavior from user libraries while hiding kernel complexity.
What we learned
- How the eBPF verifier enforces safety and termination guarantees inside the kernel.
- The detailed lifecycle of a syscall and how kernel tracepoints reflect different execution stages.
- Designing efficient BPF maps and synchronization to avoid race conditions and data loss.
- The advantage of performing in-kernel measurement to eliminate user-space timing noise.
- The importance of startup synchronization between parent and child to guarantee complete and reproducible traces.
What's next for Syscall Latency eLiteTrace
- Extend automatic discovery to network stack, page-fault, and interrupt latency tracing, maintaining the same low-overhead design.
- Add real-time visualization of syscall latency trends using Grafana or a web dashboard.
- Support multithreaded and containerized workloads, providing per-thread and per-container latency statistics.
- Integrate machine learning–based anomaly detection to identify irregular syscall latency patterns automatically.
- Incorporate eBPF LSM (Linux Security Module) hooks to move beyond passive tracing — enabling the framework to perform actions in response to system events, such as:
- Logging or throttling processes that repeatedly exceed latency thresholds.
- Dynamically adjusting syscall priorities or enforcing lightweight runtime policies.
- Logging or throttling processes that repeatedly exceed latency thresholds.
- Package the framework as a modular, open-source observability and control toolkit for developers and system engineers.
Mathematical Definition of Syscall Latency
The latency of a syscall is defined as the difference between its exit and entry timestamps:
$$ L_{\text{syscall}} = T_{\text{exit}} - T_{\text{enter}} $$
The average latency across ( N ) syscalls is given by:
$$ \bar{L} = \frac{1}{N} \sum_{i=1}^{N} L_i $$
Both timestamps are recorded inside the kernel using bpf_ktime_get_ns() for nanosecond precision.

Log in or sign up for Devpost to join the conversation.