-

The finished prototype
-

The team rocking the very fashionable Synviz glasses
-
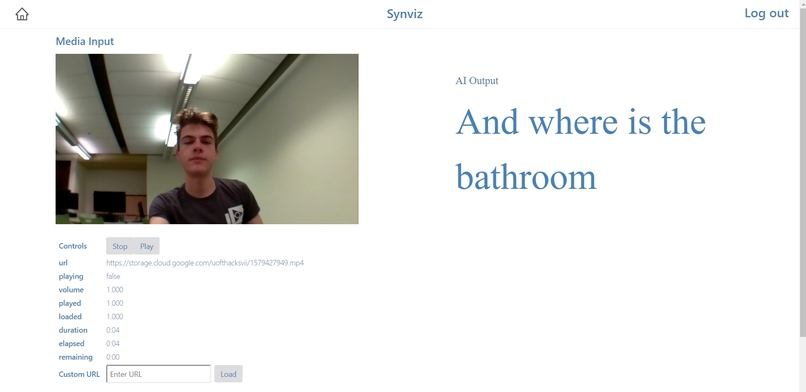
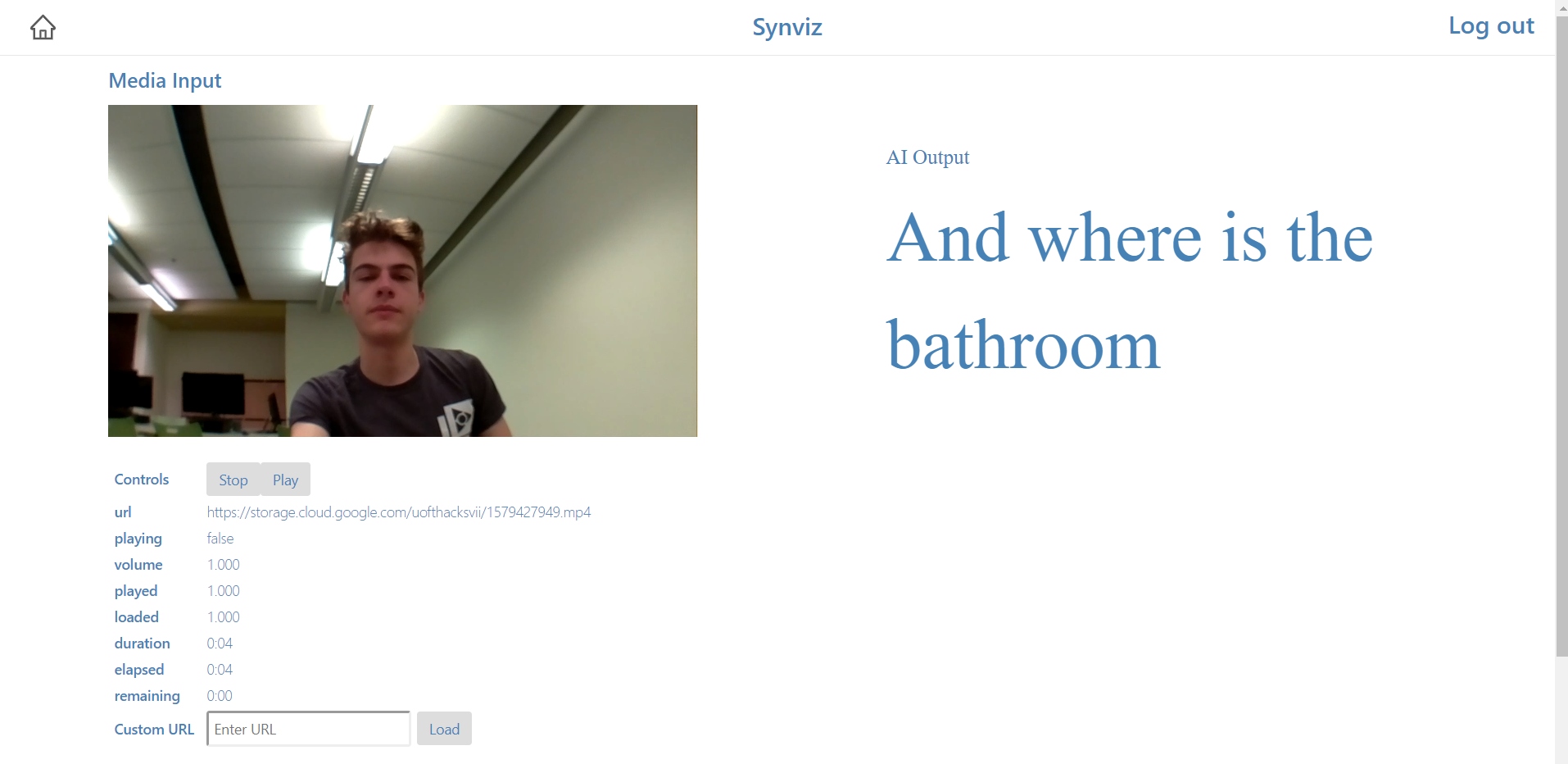
Web dashboard, which supports playback of video clips, and displays the predicted text
-
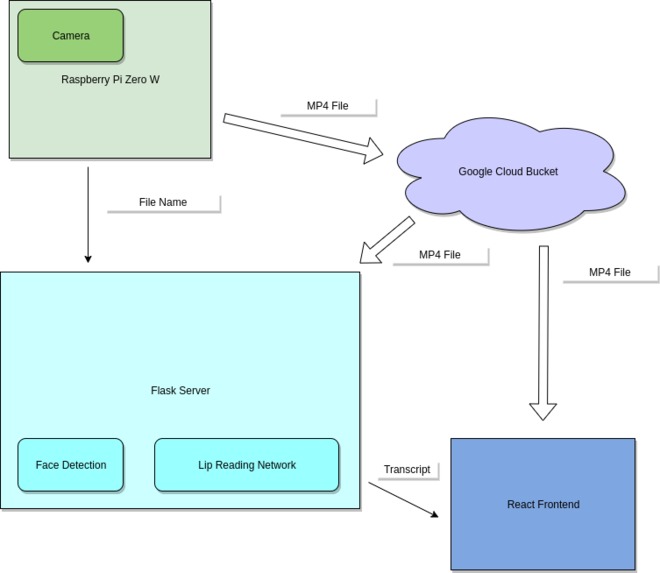
Pipeline
-

Team logo and motto




Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found here. The repo for the model used as a base template can be found here.
The second source of inspiration is an existing product on the market, Focals by North. Focals are smart glasses that aim to put the important parts of your life right in front of you through a projected heads up display. We thought it would be a great idea to build onto a platform like this through adding a camera and using artificial intelligence to gain valuable insights about what you see, which in our case, is deciphering speech from visual input. This has applications in aiding individuals who are deaf or hard-of-hearing, noisy environments where automatic speech recognition is difficult, and in conjunction with speech recognition for ultra-accurate, real-time transcripts.
What it does
The user presses a button on the side of the glasses, which begins recording, and upon pressing the button again, recording ends. The camera is connected to a raspberry pi, which is a web enabled device. The raspberry pi uploads the recording to google cloud, and submits a post to a web server along with the file name uploaded. The web server downloads the video from google cloud, runs facial detection through a haar cascade classifier, and feeds that into a transformer network which transcribes the video. Upon finished, a front-end web application is notified through socket communication, and this results in the front-end streaming the video from google cloud as well as displaying the transcription output from the back-end server.
How we built it
The hardware platform is a raspberry pi zero interfaced with a pi camera. A python script is run on the raspberry pi to listen for GPIO, record video, upload to google cloud, and post to the back-end server. The back-end server is implemented using Flask, a web framework in Python. The back-end server runs the processing pipeline, which utilizes TensorFlow and OpenCV. The front-end is implemented using React in JavaScript.
Challenges we ran into
- TensorFlow proved to be difficult to integrate with the back-end server due to dependency and driver compatibility issues, forcing us to run it on CPU only, which does not yield maximum performance
- It was difficult to establish a network connection on the Raspberry Pi, which we worked around through USB-tethering with a mobile device
Accomplishments that we're proud of
- Establishing a multi-step pipeline that features hardware, cloud storage, a back-end server, and a front-end web application
- Design of the glasses prototype
What we learned
- How to setup a back-end web server using Flask
- How to facilitate socket communication between Flask and React
- How to setup a web server through local host tunneling using ngrok
- How to convert a video into a text prediction through 3D spatio-temporal convolutions and transformer networks
- How to interface with Google Cloud for data storage between various components such as hardware, back-end, and front-end
What's next for Synviz
- With stronger on-board battery, 5G network connection, and a computationally stronger compute server, we believe it will be possible to achieve near real-time transcription from a video feed that can be implemented on an existing platform like North's Focals to deliver a promising business appeal
Built With
- flask
- google-cloud
- javascript
- ngrok
- opencv
- python
- raspberry-pi
- react
- tensorflow

Log in or sign up for Devpost to join the conversation.