
Inspiration
Modern AI systems require massive amounts of labeled data, but real-world datasets introduce serious privacy risks, regulatory challenges, and security concerns.
I wanted to explore a way to build and test AI systems without ever exposing sensitive real-world data.
What it does
SynthShield is a privacy-first synthetic data pipeline that generates realistic scenes and automatically produces labeled training data for computer vision systems.
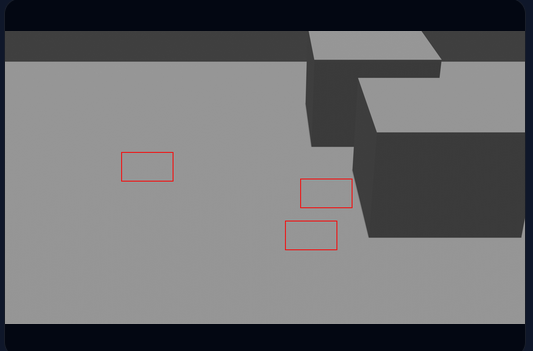
Instead of relying on real images, the system creates fully synthetic environments and outputs:
High-quality generated images YOLO-style bounding box annotations Visual validation of labeled data
This allows developers to safely train and test AI models without risking data exposure.
How I built it
I built SynthShield as an end-to-end pipeline:
Scene Generation: Procedurally generated environments using randomized object placement Annotation Engine: Automatically generates bounding boxes directly from scene metadata Visualization Layer: Web interface to display raw vs labeled outputs for validation Frontend + Backend: Lightweight web app to trigger generation and view results
The system simulates real-world variability while maintaining full control over the data.
Challenges I ran into
Designing a pipeline that keeps annotations perfectly aligned with generated scenes Balancing realism with generation speed during a 24-hour hackathon Building a clean, interactive demo under time constraints Ensuring outputs look meaningful despite being synthetic
Accomplishments that I'm proud of
Built a fully working synthetic data pipeline in under 24 hours Achieved automatic labeling without manual annotation Created a visual demo that clearly shows real-world applicability Delivered a privacy-preserving alternative to sensitive datasets
What I learned
How synthetic data can replace real datasets in sensitive domains Tradeoffs between realism, speed, and scalability Rapid prototyping under hackathon pressure End-to-end AI pipeline design
What's next for SynthShield
Expand scene complexity and realism Add support for more annotation formats (COCO, segmentation) Integrate directly with ML training pipelines Deploy at scale for enterprise and research use

Log in or sign up for Devpost to join the conversation.