-
-

cover for synthify
-
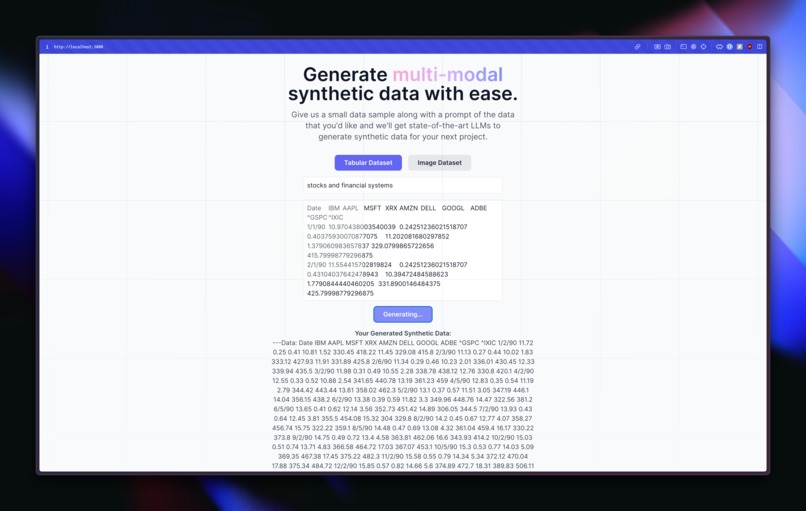
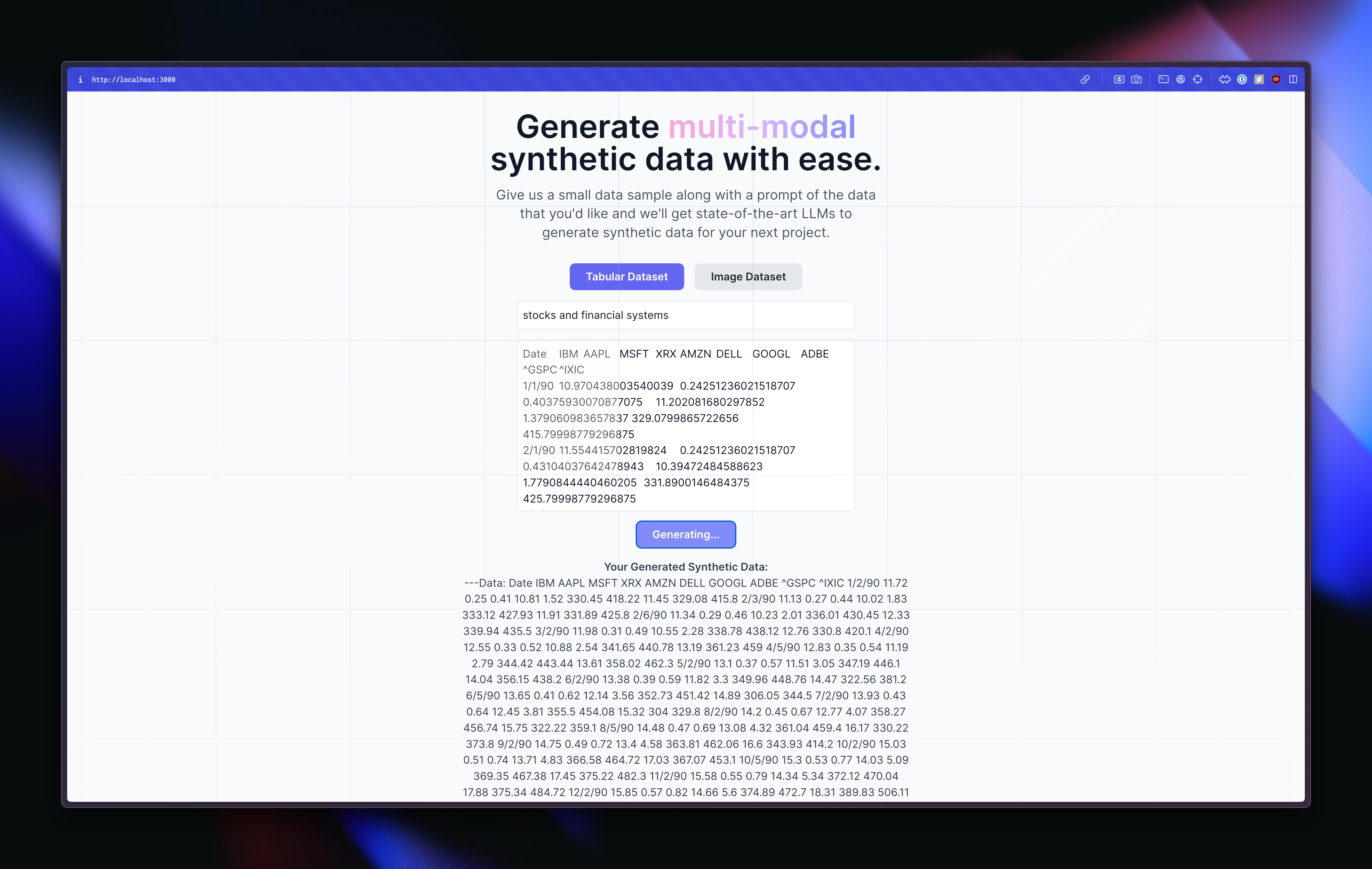
synthetic data generation for tabular data
-
landing page
-
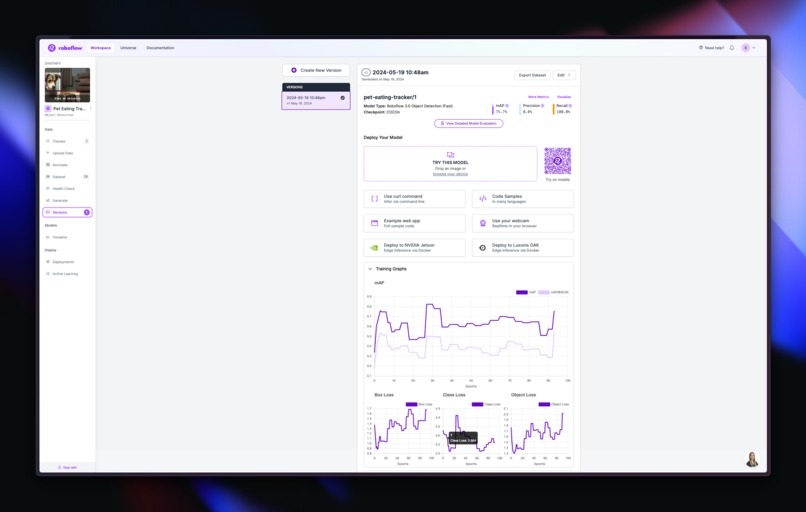
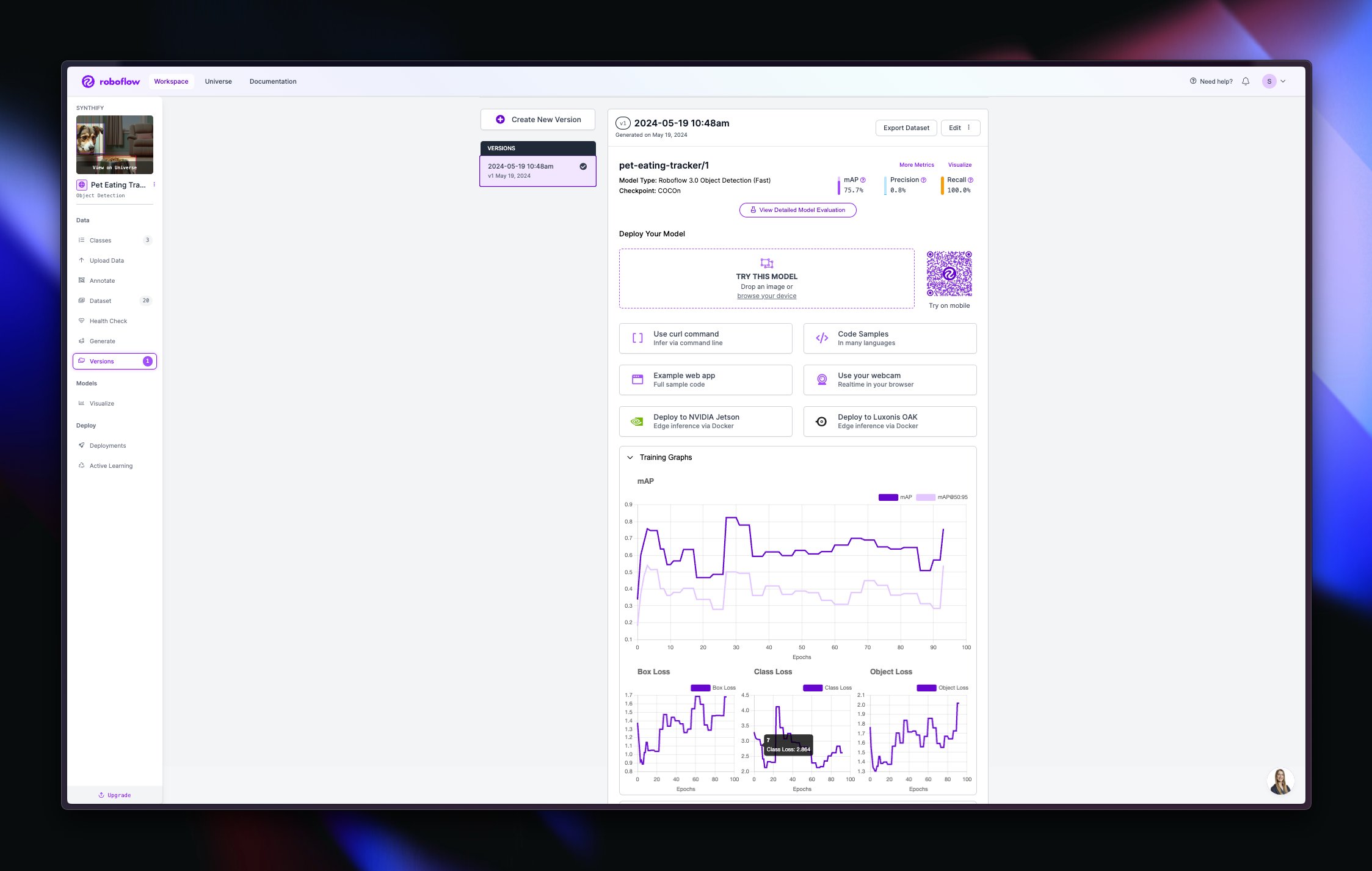
roboflow model & its performance over training (14 training:4 validation:2 testing)

Inspiration
Synthetic data generation is an incredibly important research question and holds much power when it comes to developing power machine learning models without spending a massive amount of money on data collection. I wanted to explore synthetic data generation through generative AI, specifically with the top-of-the-line LLMs, Gemini 1.5 and GPT-4o (to see which one performed better). If these LLMs are able to make significant advances in generating synthetic data, then many fields (especially the medical field) can be advanced at a faster pace, which would be revolutionary. Currently, there are some problems with LLMs (https://arxiv.org/html/2403.04190v1) within synthetic data generation, given that there are issues in correctness and hallucinations with these models that can lead to some errors when it comes to synthetic data generation. However, as these models develop, it's important to explore their performance in data generation and see whether or not LLMs have high potential in aiding in this technical space.
The challenge was specifically to compare and distinguish between Gemini 1.5 and GPT-4o. Given that both of these models are multi-modal, I had intentions of making this project tailored towards multiple modalities and testing how performance was within each of the domains. I was specifically looking at testing the text/image -> image pipeline that these models have in order to train a Roboflow model with a produced "synthetic dataset" and see how it performed with real-life scenarios. There are thousands of scenarios where it would be drastically beneficial to have synthetic image generation, and if it's able to perform at similar levels to the real deal, then it's definitely worth exploring further. One area that I was specifically interested in—as a pet owner—was tracking whether your pet has eaten while you are out. There are many companies who have ridiculous cameras with a subscription service, but what if this could all be DIY through Roboflow's integration with Raspberry Pi (and a camera module). Given training on synthetic data, would the Roboflow model be able to determine whether a dog/cat has eaten their food and alert their owner via text? This is a real use-case scenario for synthetic data and model generation.
What it does
Simply put, given some prompt and prior data, Synthify will generate synthetic data for any specific problem that you may have. While there are many different domains (which the original goal was to cover), i.e. text, audio, visuals, currently Synthify is only able to process tabular data and visual data (i.e. images). Once given a prompt of what is needed as well as some prior data to see how it should analyze the characteristics of the data, it is able to produce (based on Gemini 1.5 and GPT-4o) synthetic data. It was intended to be verified by a state-of-the-art synthetic data generator (https://gretel.ai) as well as by rigorous statistics and PCA analysis, but unfortunately there was not enough time to implement either of these ideas. Given the output from the Dalle-3 model (since neither Gemini 1.5 nor GPT-4o are able to produce image outputs yet) was put into Roboflow and annotated for dog objects, empty food bowls, and full food bowls. The main purpose here was to be able to use synthetic data to create scenarios that are difficult to find real-data for and make sure that within a real scenario, it should be able to scan whether or not this pet has eaten their food. This can be helpful for homeowners that have left the house for the night and want to check on their dog through some sort of a household camera. If the cat/dog has eaten their food, then this DIY kit could alert the owner via text and their night may not have to be as stressful (or they might not have to come back early in fear that their pet is not doing okay). This could help them ease off and overall contributes to better quality of life for a petowner. Also, this model can be used for many other scenarios when it comes to pet care, which could drastically help petowners reduce their own anxiety and stress, as well as implement a DIY approach (refusing to pay a subscription-service from many companies who over "pet" cameras). The overall approach here is all powered by these synthetic data given that AI is able to imagine scenarios that we may not actually have real-data for (i.e., I'm not taking photos of my dog with empty food bowls and full food bowls, but if AI can do it for me and it can be accurate in the real-world, then it's incredibly helpful). There are numerous applications beyond just pet ownership, some of which can be directly lifesaving — i.e. natural disaster recognition, etc.
How we built it
Next.js + API calls (OpenAI/Gemini for AI and Edgestore for storing the photos temporarily) + Python for working with Roboflow and testing out AI APIs (easier in Colab)
Challenges we ran into
While Gemini 1.5 and GPT-4o are multi-modal, they do not actually have image outputs (at least not yet), which is devastating for this project, given that I wanted to test how a Roboflow model trained on these images and then was applied to real non-LLM generated images. There were also challenges with creating a robust pipeline for both GPT-4o and Gemini 1.5 since they both utilize different API calls and it made the entire process quite time-intensive, as I'd be reading the docs quite deeply. I also had a challenge when it came to be able to verify the strength of the generated synthetic data, given that I was not able to compare to the gretel api and I was not able to implement statistical analyses or a PCA analysis. This means that while you can see a decent trend with the data, it could just be a dud. Further, I think that there could be adversarial data generation, which is something that could be a research exploration in the future.
Accomplishments that we're proud of
- This is my first hackathon. I came at 11:30 PM last night and pulled an all-nighter and was able to get all of this, even though I've never worked with AI JavaScript/Node.js SDK's before in my life (and barely read the docs). So, I'm largely proud of all my work. Developing a web app is difficult, and if this was just a Jupyter Notebook, this would be a completely different story.
- I'm proud that the prompt engineering on the synthetic data generation was able to work accurately and worked pretty well, producing pretty damning results. This took multiple iterations (like 10 iterations to figure out a prompt that worked pretty well, but I am interested in exploring prompt-engineering for this project at a deeper level).
- I'm also proud that there were two models being deployed simultaneously that both worked, given that was a technical feat I've never accomplished whenever I've explored AI in colab notebooks (I usually would just work with one model at a time).
- The Roboflow model that was trained from 20 images generated through Dalle-3 seemed to have decent performance with: 75.7% mAP, 0.8% precision, and 100.0% recall. However, in the future, I hope to test this with better photos of dogs and see if it's able to maintain its performance. Overall, I think this was a great proof-of-concept for an idea that I envisioned (using synthetic data for larger real-life tasks). I'm sure that this has already been thought of, but applying it to specific scenarios like pet-ownership, I do not believe has been done before (to the best of my knowledge).
The long-term goal here was to be able to train on synthetic data (since there isn't a lot of real data about this specific prompt), and I think this model, while definitely showing signs of over-fitting, shows some proof-of-concept for this idea. This means it could warrant future research.
What we learned
Throughout this process, I learned a great deal about the complexities and potential of synthetic data generation using powerful LLMs. My initial inspiration stemmed from the recognition of synthetic data's power in advancing machine learning without incurring high data collection costs, especially in fields like medicine, and I really wanted to explore the powers of Gemini 1.5 and GPT-4o, despite the known issues of correctness and hallucinations in LLMs. The journey of creating Synthify taught me the importance of prompt engineering, as I iterated multiple times to achieve accurate results. Despite the challenges, such as the lack of direct image outputs from the models and the time-intensive process of handling different API calls, I was able to develop a functioning web app that integrated Next.js, Python, and various AI APIs. Further, this project highlighted the potential real-world applications of synthetic data, particularly in pet care, and showed me how AI can be used to create data for scenarios that are difficult to capture in real life. Overall, this hackathon was a super valuable learning experience (and a fun all-nighter experience), that showed me the current limitations with synthetic data generation, but also the promising future that it has.
I also learned a lot about Roboflow throughout this entire process. From the beginning, I was really interested in exploring Roboflow, because I was deeply curious how synthetic/artificial data would affect their model development. Given that, I watched a ton of their tutorials, and overall, this website feels like the HuggingFace of computer vision, and I think that's extremely impressive (I think HF is amazing). I want to explore computer vision a lot more, and I'd be excited to (potentially) help build out Roboflow and develop more features! Regardless, can't wait to explore it more!
What's next for Synthify: Multi-modal Synthetic Data Generation
- Building out all the ideas listed above! For a specific plan: from what I found online, there does seem to be a way to generate images with Gemini and Vertex AI (but I'm not sure if this is 1.5). I would really like to compare Gemini's image generation and OpenAI's image generation. I would also like to create different scenarios and see how the performance for these models are in different situations. Second, I want to figure out a benchmark (if possible) to rate/rank synthetic data generation. What makes it good? I don't think there is an agreed-upon benchmark (each startup has their own benchmark) and I'd like to explore this idea mathematically and see if there's a specific benchmark that can be set up. This would be complementary to rigorous visual analysis of the data (i.e. PCA and other statistical analyses that would help me understand the data better). I would then like to explore Roboflow more deeply and actually test out these models on real-life situations, as opposed to AI-generated images. Understanding how the Roboflow model is training would be incredibly insightful, so I plan on reading through their object detection papers/blogs. Lastly, I think there's ample precedent here to explore synthetic data generation through LLMs into a deeper research endeavor, and I hope to connect with one of my professors at Princeton to assist me in exploring this further.

Log in or sign up for Devpost to join the conversation.