-
-
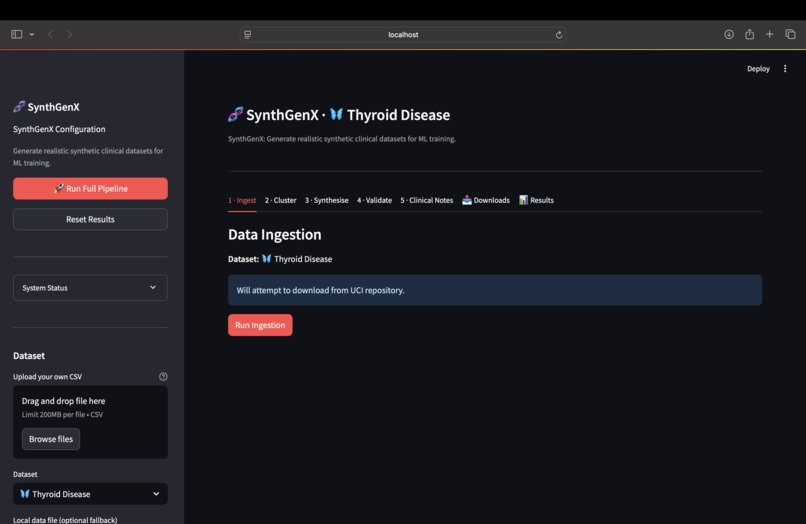
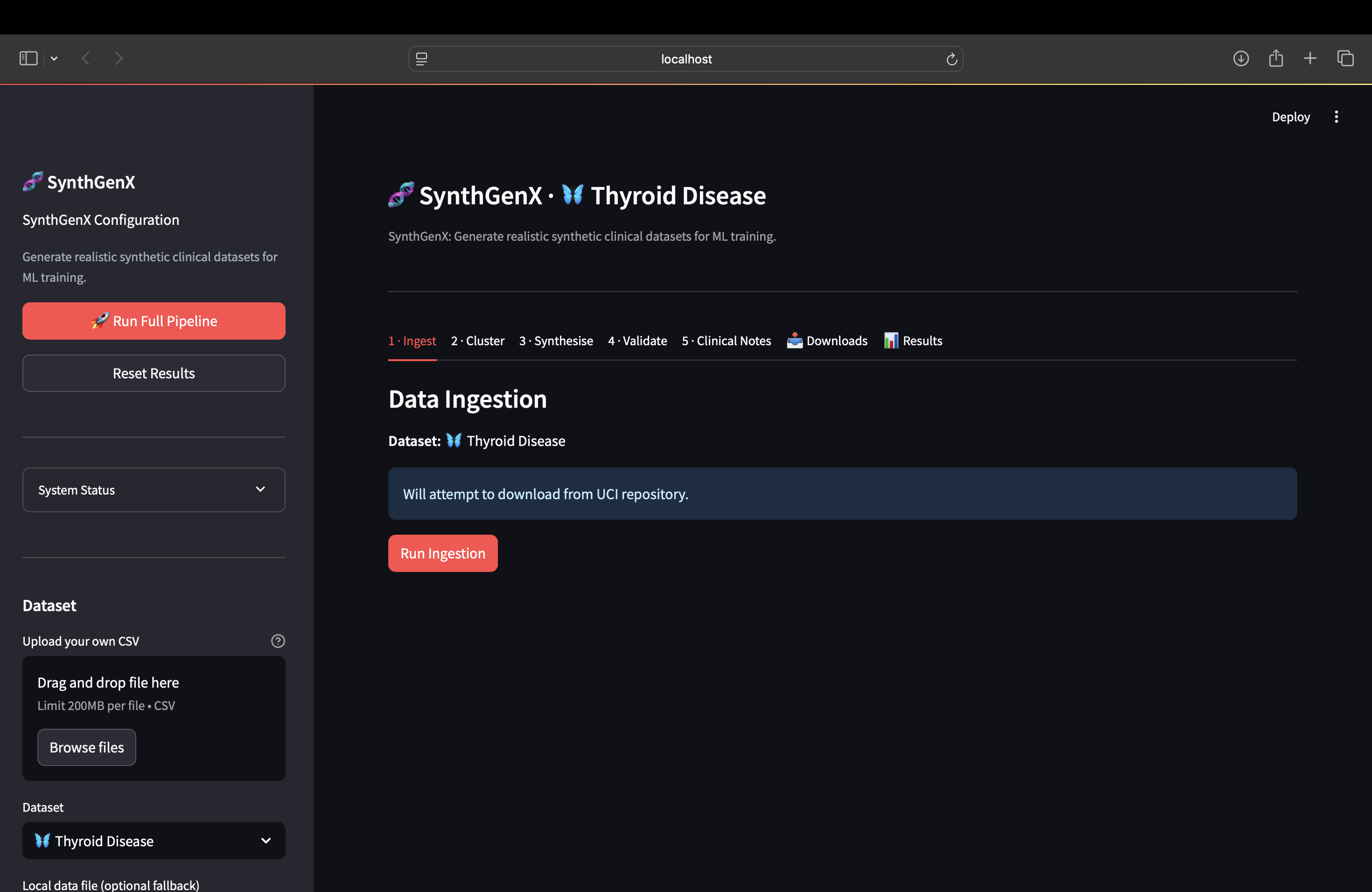
Initial Screen
-
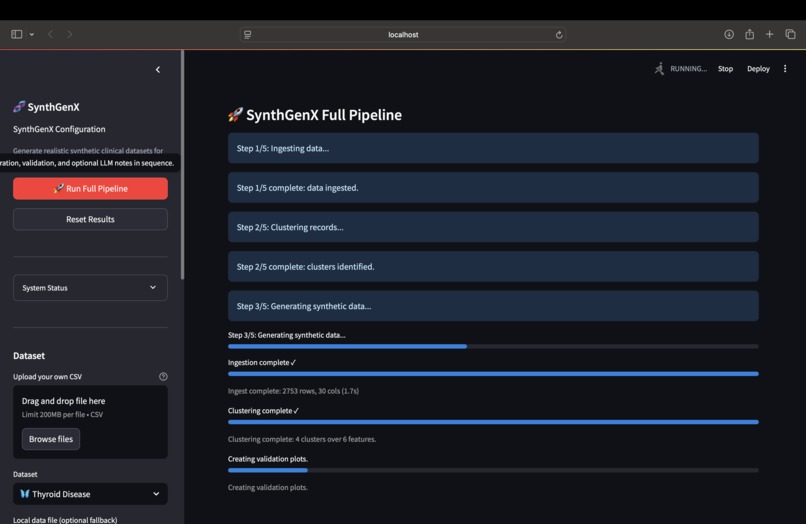
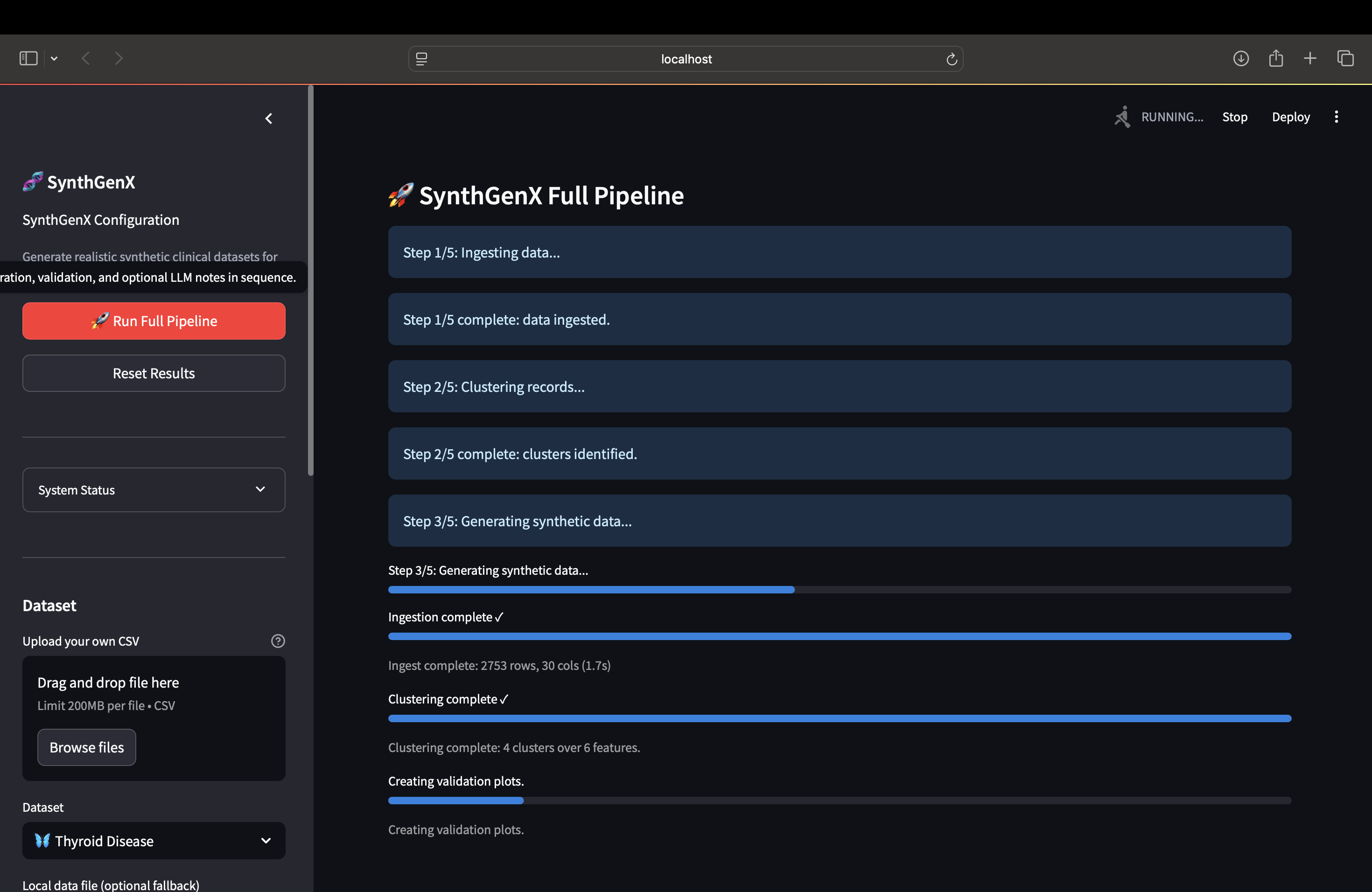
Pipeline Running as a whole
-
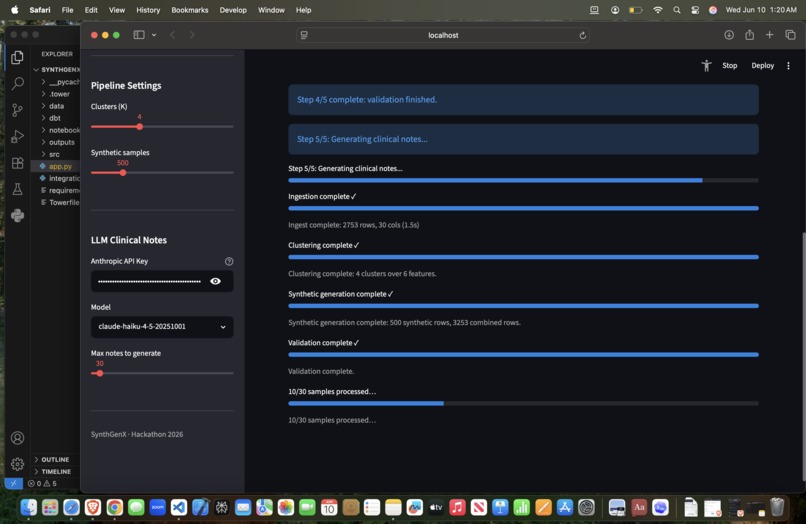
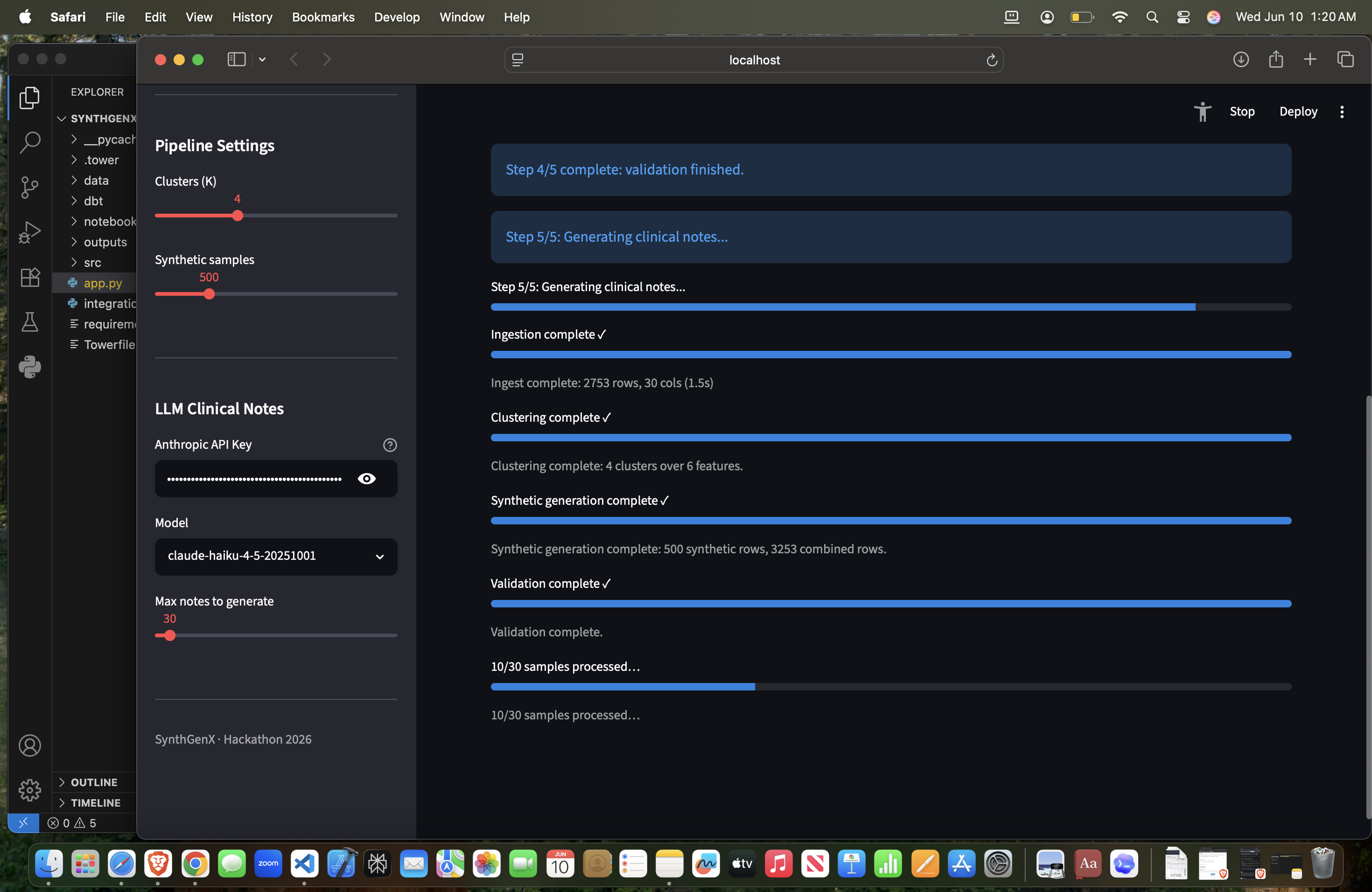
Pipeline near completion
-
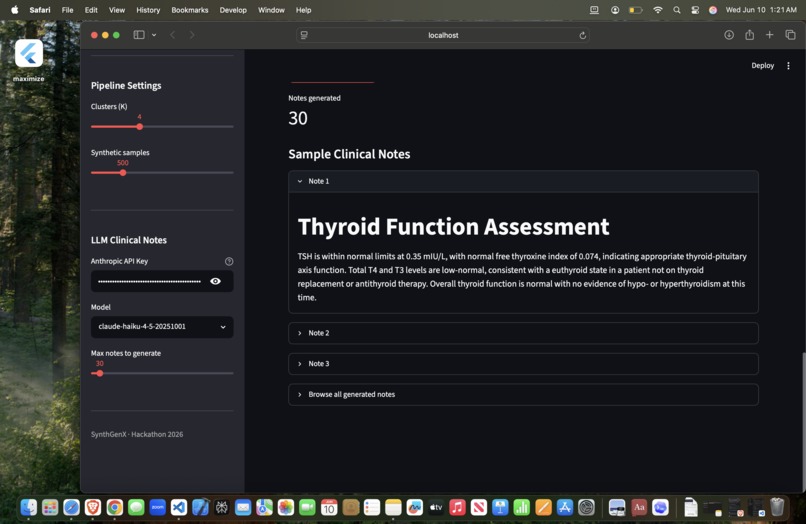
Clinical Notes through use of Claude
-
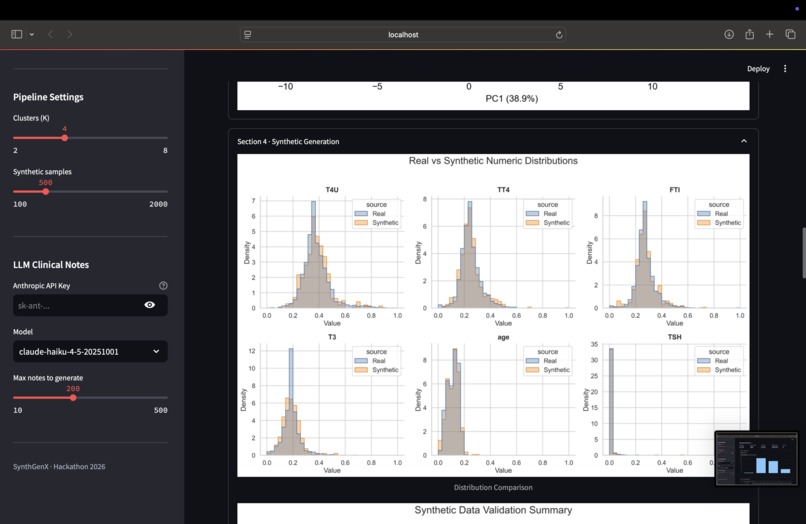
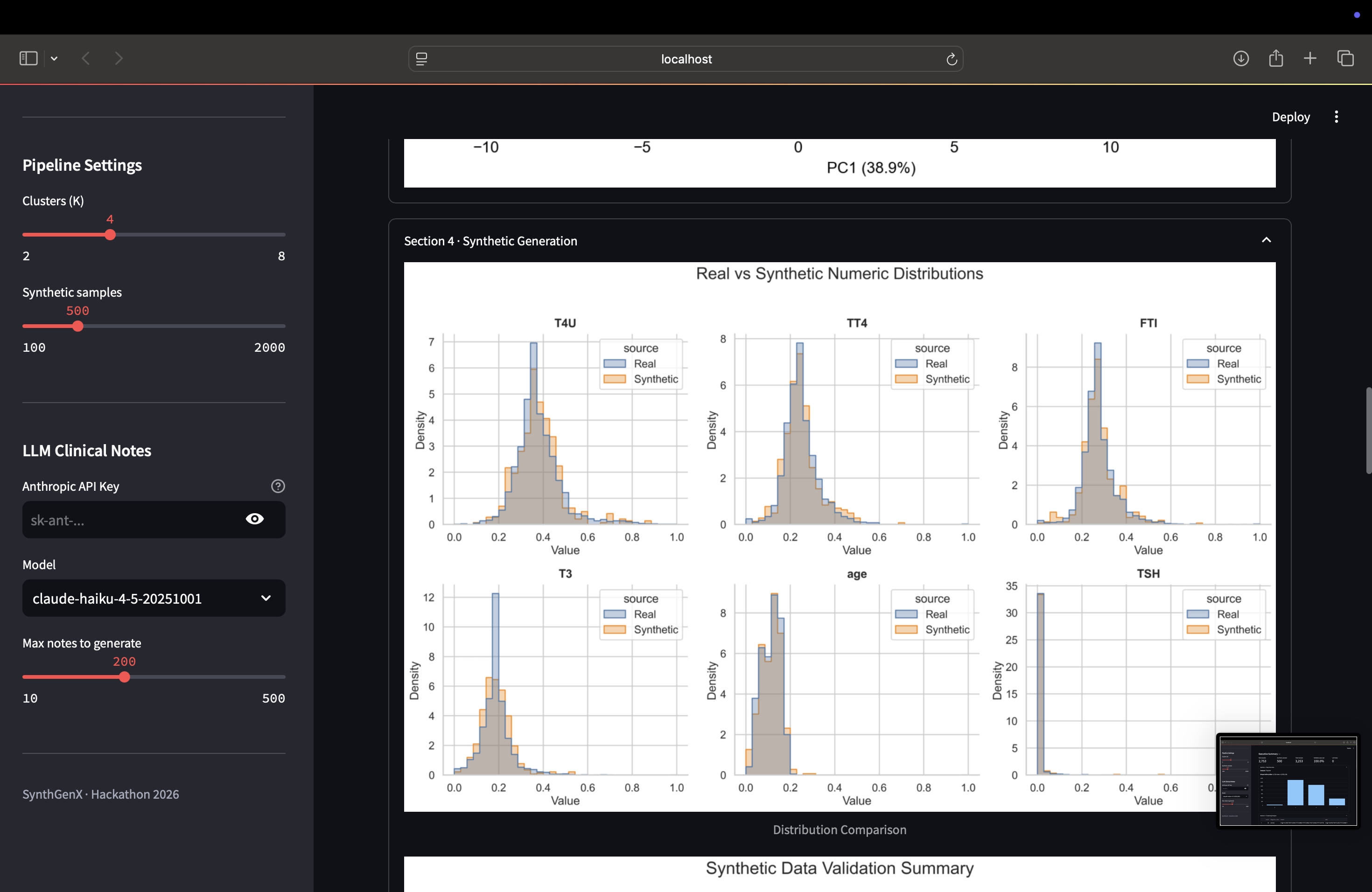
Figures seen at the end
SynthGenX: From Manual Process to Automated Platform So here's the thing: I actually did this whole synthetic data generation process manually for a different medical research project before. It was clustering data, generating synthetic samples, validating distributions. The whole thing took weeks and was super tedious and error-prone. Then I was exploring Tower's orchestration capabilities, and it hit me: why not automate this entire workflow? I kept noticing that medical researchers constantly face the same problem. They have fragmented datasets that don't directly apply to their research targets. They need to validate their ML approaches before they commit to expensive lab work, before they apply for grants, before they pivot their entire research direction. That's when SynthGenX clicked. This could transform that painful manual process into a 5-step automated pipeline that runs in minutes.
The Problem Researchers with incomplete or fragmented datasets are stuck in this gap:
It's too risky to invest in lab work without some kind of proof-of-concept It's too expensive to collect comprehensive real-world data first It's way too slow to manually validate ML approaches
SynthGenX solves this by generating statistically-validated synthetic datasets. Now researchers can:
Validate their ML approaches before committing to lab work Build proof-of-concepts for grant applications Identify promising research directions with actual confidence Move faster from hypothesis to translational research
How We Built It The architecture is pretty straightforward: Data Ingestion → Clustering → Synthetic Generation → Validation → Optional LLM Integration And it's all orchestrated with Tower and transformed with dbt. Tech stack: Python (pandas, numpy, scikit-learn), Streamlit for the UI, Tower for orchestration, dbt for data transformation, and Anthropic Claude API for optional clinical narratives. The actual pipeline works like this: First, data ingestion. We clean, standardize, and prepare the raw clinical data. Then clustering analysis. We identify patterns using KMeans and visualize it with PCA. Third, synthetic generation. We create realistic samples using Gaussian Mixture Models with moment calibration to make sure the synthetic data matches the real data. Fourth, statistical validation. We prove the synthetic data actually matches the real data using Kolmogorov-Smirnov tests. And finally, optional AI enhancement. We can generate clinical narratives using Claude API if the user provides an API key. The cool thing is it works across different clinical datasets: Thyroid, Heart Disease, custom CSVs. You click one button "Run Full Pipeline" and it shows real-time progress as everything runs.
What I Learned The biggest lesson? Different medical domains require different calculation modifications. Thyroid diagnostics involves hormone levels like TSH, T3, T4, FTI—they have specific normal ranges. Cardiology is completely different—blood pressure, cholesterol, heart rate, different distributions entirely. And custom datasets? They could have completely different feature spaces. So clustering parameters, GMM configurations, validation thresholds—they all depend on domain-specific knowledge. You can't just use one approach for everything. Domain understanding is actually critical. I also learned that statistical validation is non-negotiable. By comparing real vs synthetic distributions using KS tests, you can actually prove that your synthetic data is statistically sound. That gives researchers real confidence to use synthetic data for proof-of-concept work. And building with Tower and dbt wasn't overkill at all. The ability to schedule pipelines, version-control transformations, scale to larger datasets, and deploy reproducibly—that made the difference between a hackathon prototype and an actual production system.
The Challenges Honestly, the biggest challenge was getting all the pipeline modules to work together properly. Module loading was a nightmare. Different src files had incompatible return structures. I had to standardize everything on a consistent format: success flag, data, error message. That took time to figure out. Streamlit had its own issues. Duplicate element keys kept crashing the app. I had to manage session state carefully and generate unique keys for everything. And type mismatches between functions—different ones expected different input formats. Had to add defensive validation in each function. The UI was harder than I expected. Headers were taking up way too much space. I switched from st.header() to st.markdown() for compact design. Real-time progress tracking required figuring out st.progress(), st.status(), and session state callbacks. And download buttons? Creating multiple downloads with unique IDs to avoid Streamlit's duplicate detection—that was surprisingly tricky. Multi-dataset support was complex too. I couldn't hardcode column names. Built logic to auto-detect numeric vs categorical features. Different datasets need different clustering parameters, validation thresholds, LLM prompts. And supporting custom user CSVs required robust error handling and validation. The LLM integration added more complexity. Rate limiting—had to implement 0.1 second delays to avoid hitting API limits. Progress tracking on 200+ API calls required careful callback management. And API failures needed graceful fallbacks so if the LLM step fails, you can still use the rest of the pipeline.
Key Takeaways Manual processes are actually research opportunities. If you're doing something tedious repeatedly, it's worth automating. Domain expertise matters. A good system understands the domain it serves. Validation builds confidence. Proof through statistics beats intuition every time. Production thinking wins. Tower and dbt architecture made this a real platform, not just a Python script.
What's Next SynthGenX is positioned as a Contract Research Organization (CRO) platform that specializes in synthetic data generation and validation for medical and clinical research. Our service model: We work directly with research teams, biotech companies, and academic institutions to develop and operationalize custom synthetic data pipelines. We handle the end-to-end process—from understanding your fragmented datasets to building validated synthetic cohorts ready for ML model development and proof-of-concept validation. The platform can extend to any domain with structured data—finance, genomics, proteomics, industrial systems. The core methodology is universal, making SynthGenX adaptable across industries while maintaining statistical rigor. Our CRO Value Proposition:
Researchers bring their incomplete/fragmented data We build and validate synthetic datasets tailored to their research targets They get statistically-validated synthetic cohorts for proof-of-concept work Reduces time from hypothesis to validated ML model from months to weeks De-risks research direction before committing to expensive lab work or grant proposals
Built with enterprise-grade infrastructure: Python, Streamlit, scikit-learn, Tower, dbt, and Anthropic Claude API—ensuring reproducibility, scalability, and production-readiness for real research environments.
Built With
- claude
- dbt
- python
- streamlit
- tower

Log in or sign up for Devpost to join the conversation.