-
-
landing
-
gallery
-
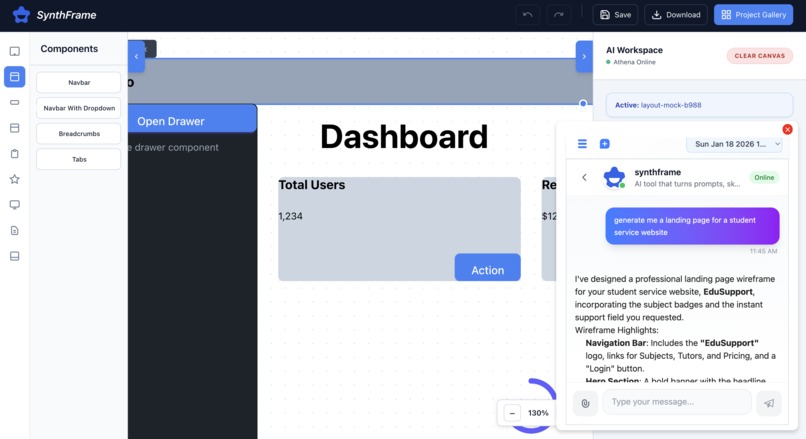
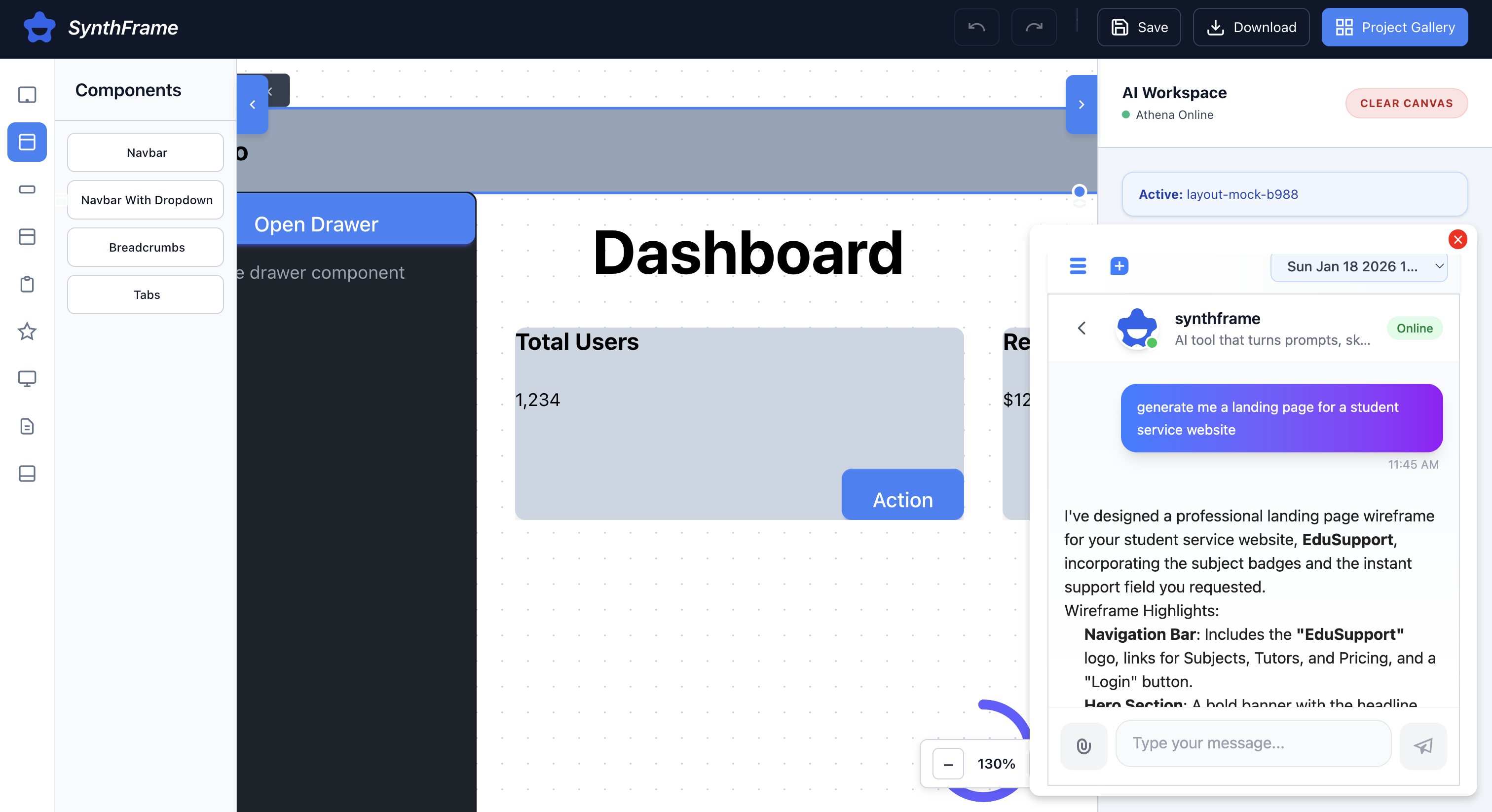
athena ai chatbot
-
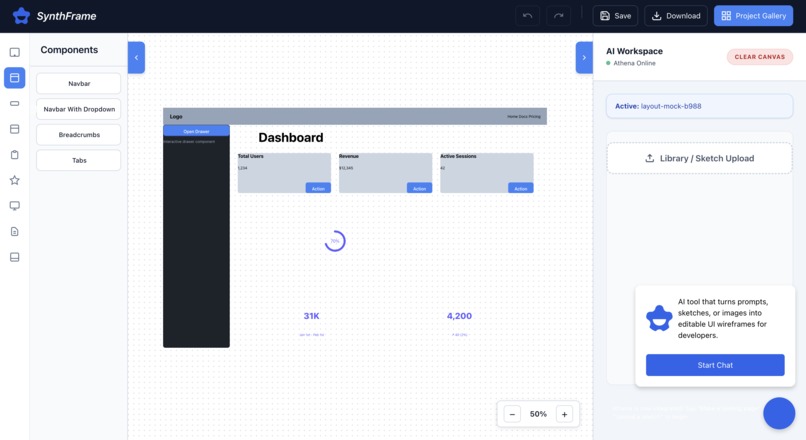
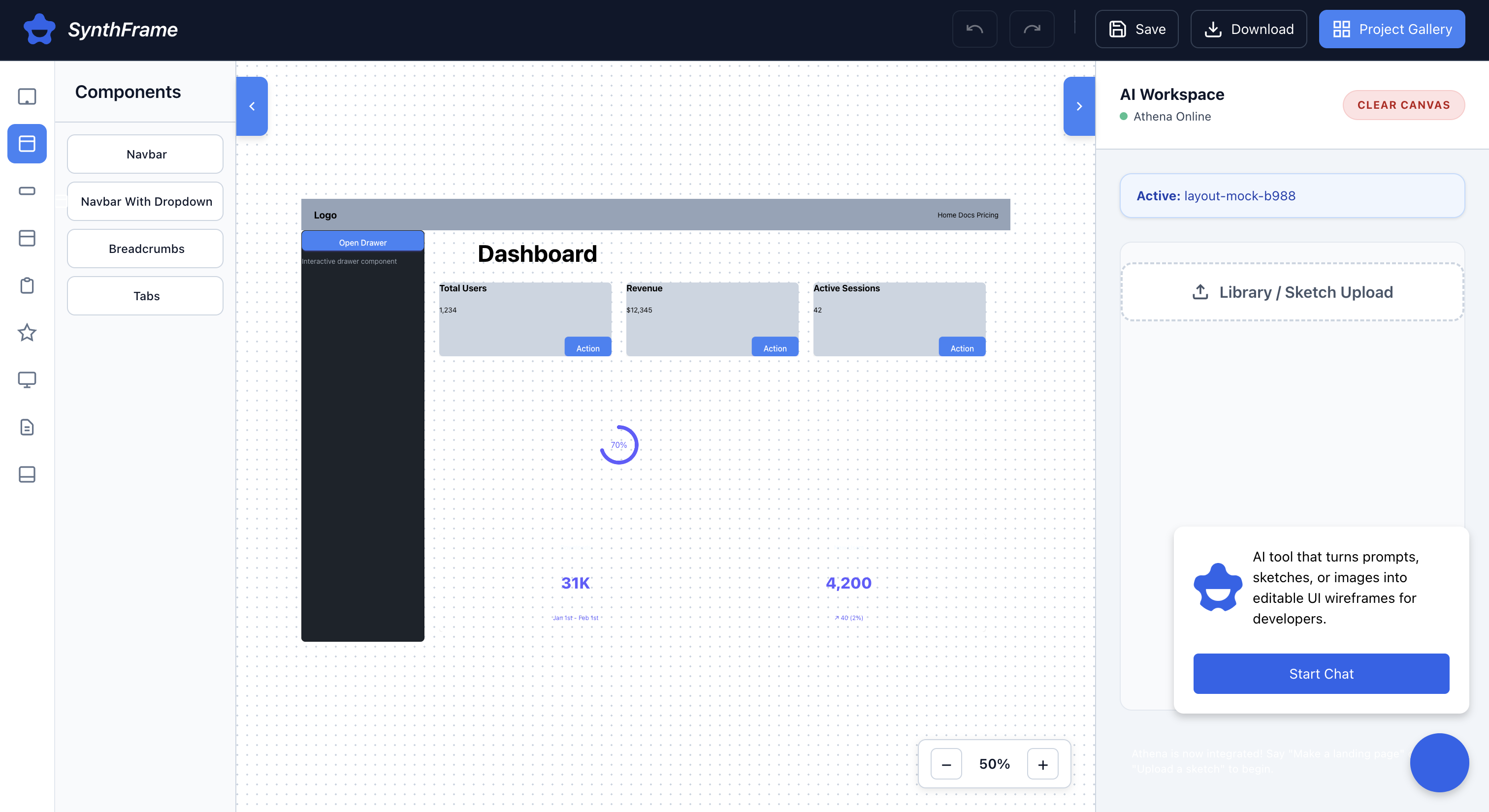
sketchpad
Inspiration
In the current development cycle, the path from an idea to a functional app is a slow, fragmented game of telephone.
Designers sketch brilliant ideas on paper, then spend hours manually recreating them in digital tools.
Developers wait for polished mockups before they can even touch the backend, creating a massive bottleneck.
The "Spatial Gap": Most AI tools offer text-to-UI, but they ignore the spatial reasoning that only comes when you draw. You can tell an AI you want a "login page," but it won't know exactly where you want the button—unless you show it.
We’re building in a line when we should be building in parallel. The creative vision is often lost in translation, and the "waiting game" kills momentum.
What it does
Synthframe is a multimodal wireframe generation system that converts sketches, text, or both into precise, structured UI layouts.
By piping OpenCV-based contour detection into Google's Gemini models, we turn static pixels into intelligent components.
Sketch it: Our computer vision pipeline scans your hand-drawn diagrams, identifying distinct UI elements, calculating their bounding boxes, and mapping them to a digital canvas.
Describe it: Natural language prompts are translated into pixel-perfect structures using standard device footprints (iPhone, MacBook, etc.).
Do both: In hybrid mode, we merge the spatial truth of your drawing with the semantic intent of your text for the most accurate result.
The design process doesn't stop at generation. Integrated as a core tool for Athena AI, Synthframe allows for conversational iteration. You can chat with your design to "make the navbar taller" or "add a footer," and the system updates the underlying machine-readable JSON instantly—giving you a living, editable specification rather than a static image.
Key features
👁️ Smart sketch interpretation—Synthframe detects basic shapes, classifies them as UI elements (navbar, cards, sidebar, footer, etc.), and maps them onto a structured digital canvas.
🤖 LLM-powered layout generation—Natural language descriptions are transformed into structured JSON layouts with minimal manual prompt engineering.
🎨 Hybrid image and text understanding—Computer vision determines where components belong, while Gemini understands what they represent. Together, they produce richer, more accurate layouts than either input alone.
🛡️ Reliable four-level fallback system—If one approach fails, Synthframe automatically tries another: Hybrid → Vision-only → Text-only → Device default. This guarantees a valid wireframe instead of breaking.
✏️ Natural language editing—Designers can refine layouts using simple instructions like “make the navbar taller” or “add a search bar to the sidebar,” and Synthframe updates the existing design accordingly.
📱 Device-aware design—Layouts automatically adapt between desktop (1440×900) and mobile (393×852). For example, a desktop sidebar can intelligently transform into a mobile bottom navigation bar.
How we built it
Backend: FastAPI with modular route architecture (/generate, /vision/analyze, /hybrid, /edit)
CV Pipeline: OpenCV + NumPy for image preprocessing, contour detection, and shape classification. Position-based heuristics map rectangles to component types.
LLM Integration: Google Gemini 2.5 Flash with carefully engineered prompts that output valid JSON. Robust JSON repair handles malformed responses.
Hybrid Merging: A refinement prompt feeds CV-detected components + user text to Gemini, which reclassifies types and enriches props while preserving spatial layout.
Schema Unification: Both pipelines output the same WireframeLayout schema (pixel-based x, y, width, height), so the frontend doesn't care where the wireframe came from.
Testing: Comprehensive test suite covering all pipelines, device configurations, and fallback scenarios.
Accomplishments that we're proud of
We built a system where you can draw on paper, take a photo, type “make this a dashboard with analytics,” and get a production-ready wireframe in seconds.
We combined two very different pipelines, computer vision and an LLM, into one unified schema. The frontend treats every result the same, whether it came from a sketch, a sentence, or both.
And honestly, the hybrid mode still feels a little magical. Seeing the precise layout from a quick sketch seamlessly merge with the meaning from natural language is genuinely satisfying to watch.
What's next for Synthframe
🖼️ Visual wireframe editor—React/Next.js frontend to drag, resize, and refine generated layouts in real-time.
🧠 AI design critique—After generating a layout, the model provides structured feedback on usability, hierarchy, spacing, consistency, and interaction flow.
🎯 Accessibility scoring—Flag layouts with touch targets too small, contrast too low, or navigation too complex.
🌐 Web scraper context—Feed in a competitor's URL and generate "a layout like this, but with our brand."
📐 More device presets—iPad, Android tablets, desktop monitors, custom dimensions.
🧩 Component library export—Output to Figma, React components, or Tailwind classes.
Built With
- athena
- figma
- geminiapi
- javascript
- mongodb
- python
 Wang")










Log in or sign up for Devpost to join the conversation.