-
-
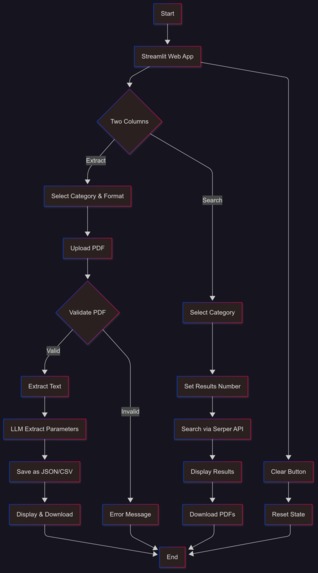
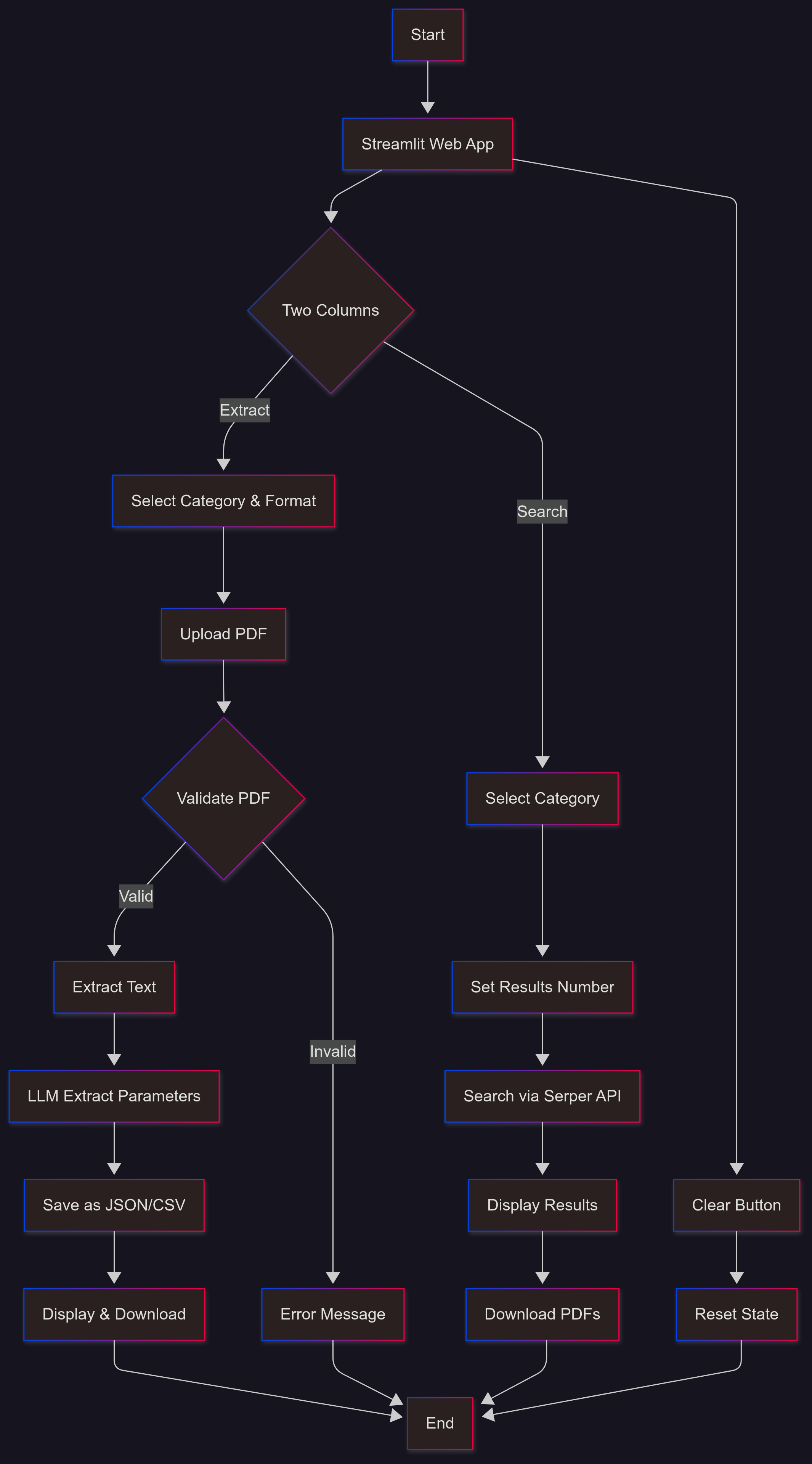
Flowchart showing the Synthex pipeline
Inspiration
I’ve always been fascinated by the potential of nanomaterials to revolutionize fields like medicine, energy, and electronics. However, diving into the research side of material science, I quickly realized how time consuming and error-prone it is to manually extract synthesis parameters from scientific papers. Sifting through a lot of PDFs to find specific details like temperature, pressure, or precursor concentrations often felt like searching for a needle in a haystack. Sometimes, I’d miss critical information buried in a paragraph, which could set back experiments or analysis. The use of AI in material science isn’t as advanced as it could be, and I saw an opportunity to bridge that gap. I wanted to create a tool that could automate this process, making research faster, more accurate, and accessible to scientists. That’s what inspired me to build Synthex, a tool to streamline nanomaterial research using AI.
What it does
Synthex is a tool designed to simplify nanomaterial research by automating the extraction of synthesis parameters from PDF documents and enabling online searches for relevant papers. It processes scientific PDFs to identify key parameters like temperature, pH, or molar concentrations and organizes them into structured JSON or CSV files for easy analysis. Users can select a nanomaterial category, such as metal oxides or carbon based materials, and choose their preferred output format and can also download this extracted parameters in their desired format. Beyond extraction, Synthex offers a search feature powered by the Serper Google Search API, allowing users to find and download relevant papers based on the nanomaterial category. The tool provides both a command-line interface (CLI) for quick processing and a Streamlit web app with an intuitive interface, featuring parameter extraction, and paper search capabilities.
How we built it
The core extraction logic uses pypdf and langchain-google-genai to process PDF text and convert it into documents format that can be fed into the gemini-1.5-flash LLM. Vector embeddings are also created using Google Generative AI Embedding to give the LLM examples of how it should give its response so as to improve accuracy. These embeddings are indexed with FAISS and loaded when extracting synthesis parameters . A script handles special characters like ° or ⋅ via UTF-8 encoding to ensure accuracy for scientific notation.
For the search functionality, I integrated the Serper Google Search API allowing users to query papers by nanomaterial category and retrieve titles, URLs, and downloadable PDFs. The CLI, implemented processes a single PDF and saves results as JSON or CSV. To make Synthex accessible to non-technical users, I developed a Streamlit web interface which has two columns: one for uploading a PDF, selecting a category, and extracting parameters, and another for searching papers online. Results are displayed as a JSON text box or CSV table, with download buttons respectively. The project structure is modular, with separate scripts for extraction, search, and PDF processing, plus RAG rag for prompt templates and sample embeddings.. Logging also helped track errors during development.
Challenges we ran into
One major challenge was dealing with the inconsistent formatting of scientific PDFs. Parameters might appear in tables, footnotes, making it hard to extract them reliably. I iterated on the extraction script to handle these variations, especially for equations like ( \text{[CuSO}_4] = 0.1 , \text{M} ) or symbols like °C, which sometimes broke due to encoding issues. Tuning the NLP pipeline to recognize context-specific parameters, like distinguishing synthesis conditions from experimental results, required extensive testing with sample papers.
The Streamlit interface posed its own difficulties. Designing a layout that clearly separated extraction and search while remaining user-friendly took multiple redesigns. State management was tricky, ensuring the “Clear” button reset both sides without causing UI glitches required careful coding. The Serper API integration needed robust error handling for rate limits and malformed responses, which I addressed with retries and fallback messages. Ensuring consistent UTF-8 encoding across all components was a persistent issue, as some libraries handled special characters differently.
Accomplishments that we're proud of
I am thrilled to have created a tool that tackles a real pain point in material science research. Successfully extracting structured parameters from messy, unstructured PDFs feels like a big win, especially when it handles complex scientific notation. The Streamlit interface is another highlight, it’s intuitive, responsive, and makes Synthex accessible to researchers without coding expertise. Integrating real-time paper search with downloadable PDFs makes it easier to check for papers online, turning Synthex into a one-stop shop for nanomaterial research. I am also proud of the modular codebase, which is easy to maintain and extend. Most of all, I am excited that Synthex can save researchers hours of manual work, letting them focus on innovation rather than data collection.
What we learned
This project was a crash course in blending AI with scientific research. I learned how to use LLMs and embeddings to extract meaningful data from unstructured text, which opened my eyes to the power of NLP in specialized domains. Working with FAISS taught me how to optimize similarity searches for performance, while handling PDFs showed me the importance of robust text processing. Building the Streamlit app made me gain a new appreciation for user experience design. Integrating external APIs like Serper gave me insights into real-time data retrieval and error handling. On a broader level, I learned how to manage a complex project end-to-end, from ideation to deployment, while juggling technical challenges and user needs.
What's next for Synthex: A Nanomaterial Synthesis Parameter Extractor
I will expand the range of nanomaterial categories and parameters it can extract, incorporating more complex synthesis conditions like multi-step reaction pathways. I am exploring ways to integrate with databases like PubMed or arXiv to enhance the search functionality. Adding support for batch PDF processing in the CLI and web app would make Synthex more scalable for large research projects. I also plan to improve the NLP model by fine-tuning it on a larger dataset of nanomaterial papers, increasing accuracy for edge cases. On the UI side, I am considering features like parameter visualization (e.g., plots of temperature vs. yield) and user accounts to save extraction history.
Built With
- faiss-(1.8.0)
- faiss-cpu==1.8.0
- langchain-community
- langchain-google-genai==1.0.10
- langchain==0.2.16
- pypdf==4.3.1
- python-dotenv==1.0.1
- python==3.12.2
- requests
- requests==2.32.3
- serper
- streamlit-(1.38.0)
- streamlit==1.38.0

Log in or sign up for Devpost to join the conversation.