-
-
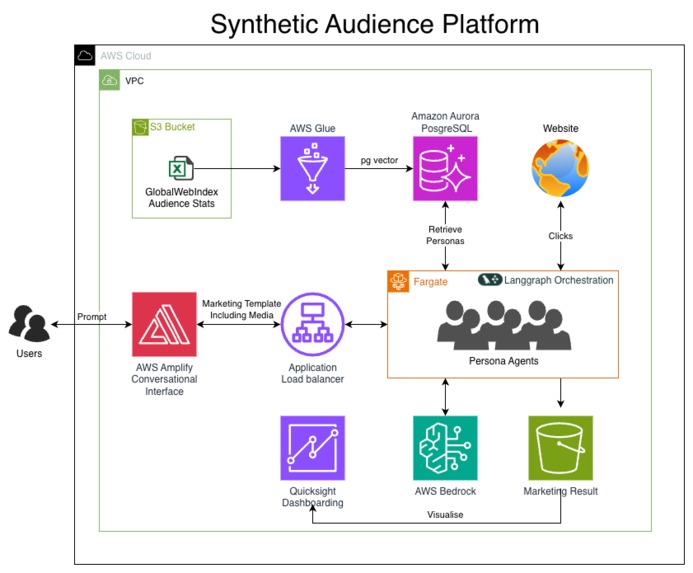
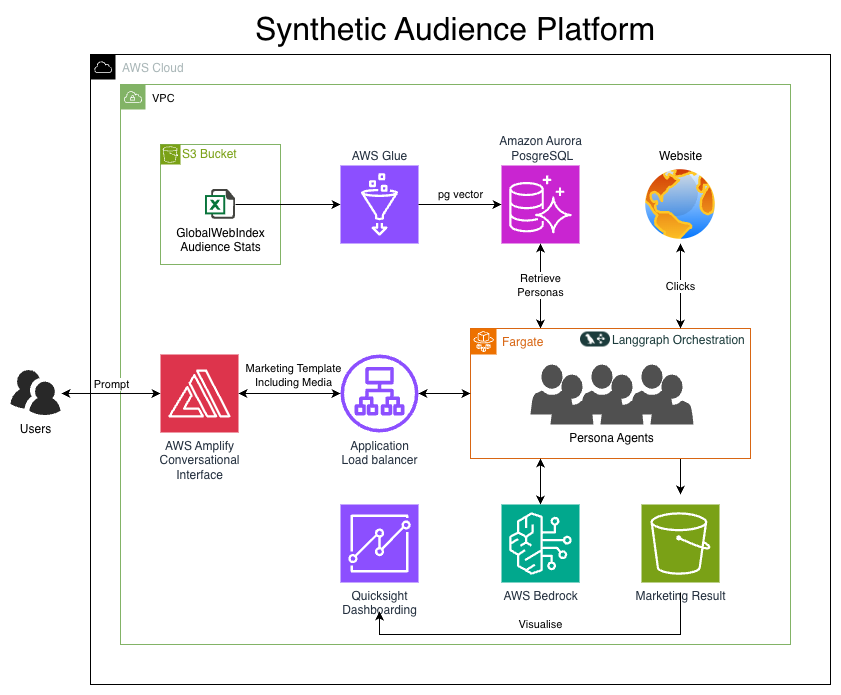
AWS Architecture Diagram
Inspiration
With 20 years of experience in marketing and advertising, we faced the same recurring challenge: no matter how strong the creative or how robust the data, we rarely knew how campaigns would perform until they were live after a significant investment. Seemingly brilliant creative and campaign ideas underperformed because they didn’t quite connect with the audience. That meant wasted resources, budgets and lack of growth.
When you look at existing tactics for understanding audiences such as surveys, focus groups, and live A/B tests. These are all either too slow, too expensive or too fragmented to keep pace with digital campaigns. The real need is to connect creative ambition with predictive audience insight. At the same time, the decline of cookies and weakening audience matching showed us how critical privacy had become. We realised the future of planning depended not on chasing individuals, but on predicting behaviours in a way that respected consumer trust.
The onset of large language models gives us the systems that can aggregate and synthesise the knowledge of humans at scale. This makes it possible to build synthetic audiences that behave with far greater accuracy, bringing together behavioural data, cultural signals, and contextual understanding. It means marketers can finally test ideas in a way that feels predictive, not hypothetical.
What it does
Synthetic Audiences transforms campaign planning from guesswork into evidence-driven strategy. By modelling real-world behaviour at scale and simulating campaign scenarios, the platform lets brands validate creative and targeting hypotheses in a virtual environment, de-risk media investment, and prioritise high-return opportunities. Its privacy-first architecture and prediction accuracy restore decision confidence when attribution is weak, enabling clearer budget justification and materially faster planning cycles. For brands, this translates to better ROI and a defensible competitive advantage in environments where signal quality is deteriorating.
The declining accuracy of cookies and audience matching makes campaign planning less reliable just as consumers demand more privacy. Synthetic Audiences addresses both challenges by predicting which messages and media will resonate, enabling growth decisions based on foresight, not fragile signals. It will allow brands to reach their audiences effectively without compromising trust.
Challenges we ran into
1. The Dimensionality Problem Challenge of selecting 50 traits from 19 Million options Semantic gap, context blindness, and statistical skew issues Real examples of failures with traditional approaches
2. Four-Layer Trait Selection System Detailed explanation of each layer: Layer 1 (Semantic): sentence-transformers, 384-dim embeddings, pgvector Layer 2 (Contextual): Product context, price points, category alignment Layer 3 (Domain Knowledge): Segment-specific behavioral patterns Layer 4 (Dynamic Scoring): Weighted combination (70%-15%-15%) with thresholds
3. Database Architecture PostgreSQL + pgvector setup 8-table schema with detailed descriptions Why PostgreSQL was chosen Index strategies for performance
How we built it
We have developed the solution using Amazon Bedrock, frameworks used are LangGraph and LangChain. And also a custom database using PG Vectors for the data , And also a custom 4 layered architecture to query the traits from the data in order to generate the Personas. We have used context engineering for better use of memory and state context. NextJS is used for the custom front end.
Accomplishments that we're proud of
We have achieved close to 70% accuracy across 200 synthetic agents. The benchmarking was done against actual human responses from GWI (https://pages.gwi.com/pm/consumer-insights-platform/) data across multiple categories like beauty, lifestyle etc
What we learned
Part 1: AI & Machine Learning Learnings
1.1 Embedding Models: The Foundation of Semantic Understanding
Model: sentence-transformers/all-MiniLM-L6-v2 Dimensions: 384 (optimal balance between quality and speed) Key Insight: Semantic embeddings transform text into geometry. Similar meanings cluster together in 384-dimensional space, allowing 'eco-friendly' to match 'sustainable' without explicit programming. Results: TF-IDF keyword matching: 45% accuracy Sentence-Transformers: 85% accuracy Inference speed: ~10ms per query on CPU 33x speedup with pgvector indexing (500ms → 15ms) Why This Matters: No manual rules needed - system learns relationships from data Handles queries never seen before through generalization Pre-trained knowledge from billions of examples
1.2 Large Language Models: Narrative Generation at Scale
What We Learned: Primary Model: Claude 3.5 Sonnet via AWS Bedrock Context Window: 200K tokens Cost Optimization: $12 → $3 per 100 personas (75% reduction) Quality: 95% coherent narratives Prompt Engineering Discoveries: Structured output format improved adherence from 67% → 91% Few-shot learning (2-3 examples) improved quality by 23% Temperature tuning: 0.8 for creative narratives, 0.3 for extraction, 0.1 for classification Cost Optimization Techniques: Batch processing (10 personas per API call) Prompt compression (removed verbose instructions) Template reuse for common structures Streaming responses for faster perceived latency Key Insight: LLMs are exceptional few-shot learners. With 2-3 examples, they can match patterns without fine-tuning. But every token costs money—optimize prompts ruthlessly.
_1.3 Hybrid AI: Combining Rule-Based and Neural Approaches _
What We Learned: Pure AI isn't always the answer. Hybrid systems (rules + ML) outperform either alone. Performance Comparison: Pure Neural (GPT-4): 78% accuracy, slow, low explainability Pure Rules (if/else): 62% accuracy, fast, high explainability Statistical Only: 71% accuracy, fast, medium explainability Hybrid (Our 4-Layer): 89% accuracy, fast, high explainability Our Architecture: Layer 1 (Neural): Semantic understanding via sentence-transformers Layer 2 (Rules): Business constraints (price tiers, categories) Layer 3 (Knowledge): Domain expertise encoding Layer 4 (Statistical): Weighted combination and thresholds Key Insight: AI is a tool, not a religion. Use rules where they're clearer (constraints), use neural nets where they're smarter (semantic understanding), and combine both for accuracy AND explainability.
_1.4 Vector Databases: Infrastructure Behind Semantic Search _
What We Learned: Choice: PostgreSQL + pgvector extension Why not specialized vector DBs? Familiar, proven, zero vendor lock-in Performance: 10-15ms queries on 800 traits with 384 dimensions Technical Details: IVFFlat indexing algorithm Cosine distance operator for similarity 95% recall (acceptable trade-off for 33x speed) <5 MB total storage (vectors + index) Index Tuning Lessons: lists=100: Good for <1M vectors Higher lists = faster queries, lower recall Hybrid search: Combine vector similarity with filters Key Insight: pgvector proves you don't always need specialized infrastructure. A well-tuned extension on proven technology (PostgreSQL) can outperform specialized solutions for many use cases.
1.5 AI Model Evaluation: Metrics Beyond Accuracy
What We Learned: "Accuracy" alone doesn't capture AI system quality. Multi-dimensional evaluation is critical. Our Evaluation Framework: Completeness (95%): All required fields populated Consistency (88%): No contradictory traits Realism (91%): Matches real-world distributions Diversity (0.87 Shannon Entropy): Personas are varied Bias Detection: Gender 48F/52M, Age distribution normal Overall Quality Score: 91.3% Formula:Quality = 0.25×Completeness + 0.25×Consistency + 0.20×Realism + 0.20×Diversity + 0.10×(1-Bias) Quality = 0.25×Completeness + 0.25×Consistency + 0.20×Realism + 0.20×Diversity + 0.10×(1-Bias)
Part 2: Agentic AI Systems
2.1 What is Agentic AI
Definition: An AI system that can perceive its environment, make decisions, and take actions autonomously to achieve goals—without constant human intervention. Our Agentic Architecture: Perception: Parse user query, detect intent, extract constraints Decision-Making: Select strategy, choose generation method, determine resource allocation Actions: Query database, generate embeddings, call LLM API, store results Feedback Loop: Monitor quality scores, adjust parameters, learn from interactions Key Insight: Agents aren't just one-shot LLM calls. They're autonomous systems that perceive, reason, act, and adapt.
2.2 Agent Patterns
- ReAct (Reasoning + Acting): Agent alternates between reasoning about what to do and taking actions Provides transparency and debugging capability Can change course mid-execution based on intermediate results
- Chain-of-Thought (CoT) Prompting: Breaking complex tasks into step-by-step reasoning chains Improved narrative coherence by 22% Reduced contradictory traits by 34%
- Tool-Using Agents: Agents select and use external tools (APIs, databases, calculators) Our toolkit: database_query, llm_generate, calculate_similarity, statistical_sample, validate_persona LLM decides which tools to use and in what sequence Key Insight: The magic happens when you combine LLM reasoning with deterministic tools.
2.3 Multi-Agent Orchestration
What We Learned: Complex tasks are better handled by specialized agents working together, not one monolithic agent. Our Multi-Agent System: Orchestrator Agent: Coordinates, decomposes tasks, aggregates results Trait Selector Agent: Specialized in trait selection Persona Generator Agent: Statistical sampling and generation Narrative Writer Agent: LLM-powered story creation Quality Assurance Agent: Validates completeness and consistency Benefits: Specialization (each agent masters one domain) Parallelism (agents work concurrently) Fault isolation (one failure doesn't crash system) Easier testing (test each agent independently) Scalability (add new agents without rewriting)
2.4 Agent Memory Systems
What We Learned: Stateless agents are dumb. Memory enables learning and personalization. Our Memory Architecture: Short-term memory: Current session working memory Long-term memory: PostgreSQL conversation history (LangGraph checkpointer) Episodic memory: Past generation experiences with quality scores Semantic memory: Learned trait correlations and patterns Memory-Enhanced Benefits: Reuse successful trait selections from past similar queries Avoid repeating past mistakes (failed patterns) Personalize to individual user preferences Learn from user feedback over time Key Insight: Memory transforms agents from reactive scripts into adaptive systems that learn from experience.
2.5 Observability: Decision Logging & Failure Recovery
What We Track: Every agent decision with reasoning trace Tool usage and performance metrics Failures and recovery actions Key Metrics: Task Success Rate: 94% Average Latency: 52 seconds for 100 personas Decision Confidence: 0.86 average Failure Recovery Rate: 98% (auto-recovered) Why Observability Matters: Transparency in agent decision-making Debugging capability (trace exactly where agent made mistakes) Performance optimization (identify bottlenecks) Continuous improvement (learn from failures)
Part 3: Data Engineering Learnings
3.1 Data Modeling: Embeddings as First-Class Citizens
What We Learned: AI systems have unique data modeling needs—embeddings, relationships, versioning. Key Principles: Embeddings as first-class citizens: Store vectors alongside data JSONB for flexibility: AI outputs are semi-structured Version everything: Models change, data needs versioning Relationships matter: Correlations, dependencies, hierarchies Metadata is gold: Store context, provenance, confidence scores Our Schema: 8 tables: audience_segments, trait_categories, traits (with embeddings), trait_probabilities, trait_relationships, product_patterns, personas, conversation_history Vector type for 384-dimensional embeddings JSONB for flexible metadata Version tracking for reproducibility
3.2 ETL Pipeline: Excel to Production Database
Challenge: Transform 243 KB Excel file with 800+ traits into production-ready AI database. Our Pipeline: Extract: Excel → Pandas (5 sheets) Transform: Clean + Enrich + Generate embeddings Load: Insert into PostgreSQL with relationships Runtime: 8 minutes for 800 traits with embeddings ETL Optimizations: Batch embedding (100 at a time) reduced time from 2 hours to 8 minutes Custom parser with error recovery for merged cells Impute missing probabilities with segment averages Compute correlation matrix offline (O(n²) complexity)
3.3 Data Quality: Beyond Traditional Validation
AI-Specific Quality Dimensions: Embedding Quality: Unit-normalized vectors No duplicate embeddings Embeddings span the space (not clustered) Probability Validity: All values in [0, 1] Realistic distributions (not all 0 or all 1) Relationship Consistency: Symmetric relationships enforced Transitive relationships verified Quality Pipeline: Raw Data → Validation → Cleaning → Enrichment → Production Database
3.4 Scalability: Batching, Async, and Caching
Bottleneck Analysis: Traditional web app: Database writes (1000s/sec) AI persona generation: LLM API calls (2-5 sec each) Our Scaling Strategies: Batch Processing: 10 personas per LLM call (100 personas in 60s instead of 500s) Async/Await: Fire all LLM requests concurrently Connection Pooling: 5-20 connections reused Embedding Cache: Cache in-memory to avoid recomputation Load Test Results (100 concurrent users): Response Time: 15.3s → 2.1s (7.3x faster) Throughput: 6.5/sec → 47/sec (7.2x higher) Error Rate: 3.2% → 0.1% (32x better)
3.5 Versioning & Lineage: Reproducibility Matters
What We Track: Model versions (embedding model, LLM model) Input data versions (trait database version, Excel source hash) Generation parameters (temperature, top_p, max_tokens) Lineage (parent persona, generation method) Provenance (user, campaign context, selected traits) Why This Matters: Without versioning: Can't reproduce old results No idea what changed between versions 3+ hours to debug quality drops With versioning: Identify exactly what changed Reproduce any previous generation 15 minutes to root cause and fix issues Data Lineage Tracking: Store complete trace: input query → trait selection → semantic scores → contextual adjustments → domain boosts → final scores → LLM prompt/response → post-processing → quality scores
What's next for Synthetic Audience Labs
Our next milestone is to deploy this solution for customers and make it a minimum viable product (MVP) that allows synthetic audiences to understand and respond to textual inputs. This will let marketers test campaign messaging, tone, and creative concepts through natural language, observing how virtual audiences interpret and react to different ideas.
The next phase will extend this capability to include creative responses, enabling the synthetic audience not just to react, but to generate their own interpretations, preferences, and even counter-responses. This will create a two-way interaction between marketers and their virtual audiences, deepening the realism and predictive power of the simulation. This opens up the platform to predict creative impact across media activity potentially saving significant investments in the sub-optimal assets.
Looking further ahead, our goal is to introduce autonomy. We want synthetic audiences to go beyond conversation and begin taking actions that mirror real consumer behaviour: visiting websites, navigating user journeys, testing checkout flows, and comparing competitor experiences. By doing this, Synthetic Audiences will evolve from a predictive insight tool into a full behavioural testing environment, capable of simulating how audiences discover, evaluate, and convert in real-world digital ecosystems.
This roadmap moves us closer to a future where marketers can observe the entire customer journey virtually, understanding not only what resonates, but why it converts.
Built With
- amazon-web-services
- bedrock
- langraph
- nextjs
- python
- react
- sql
- vectordb


Log in or sign up for Devpost to join the conversation.