SynThesis
Inspiration
Scientific research moves fast, but the process of starting a study is painfully slow. A graduate student or early-career researcher can spend weeks doing what amounts to structured information synthesis: reading papers, identifying gaps, proposing a testable hypothesis, and mapping out a study design before a single experiment is run.
We wanted to ask: what if that initial synthesis could happen in minutes, not weeks? Not to replace researchers, but to give them a high-quality starting point — a structured, cited, critiqued draft they could actually argue with.
That question became SynThesis.
What It Does
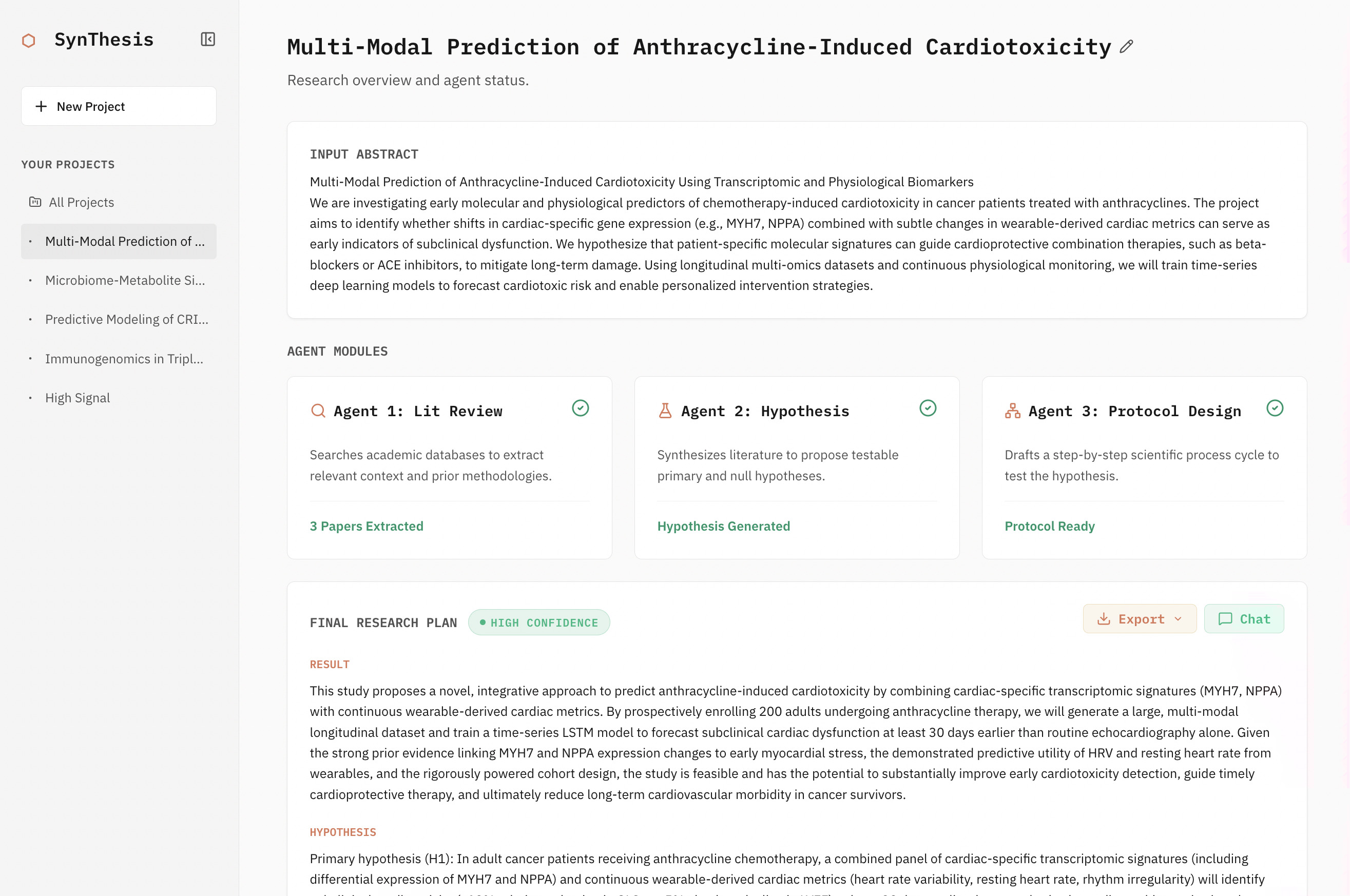
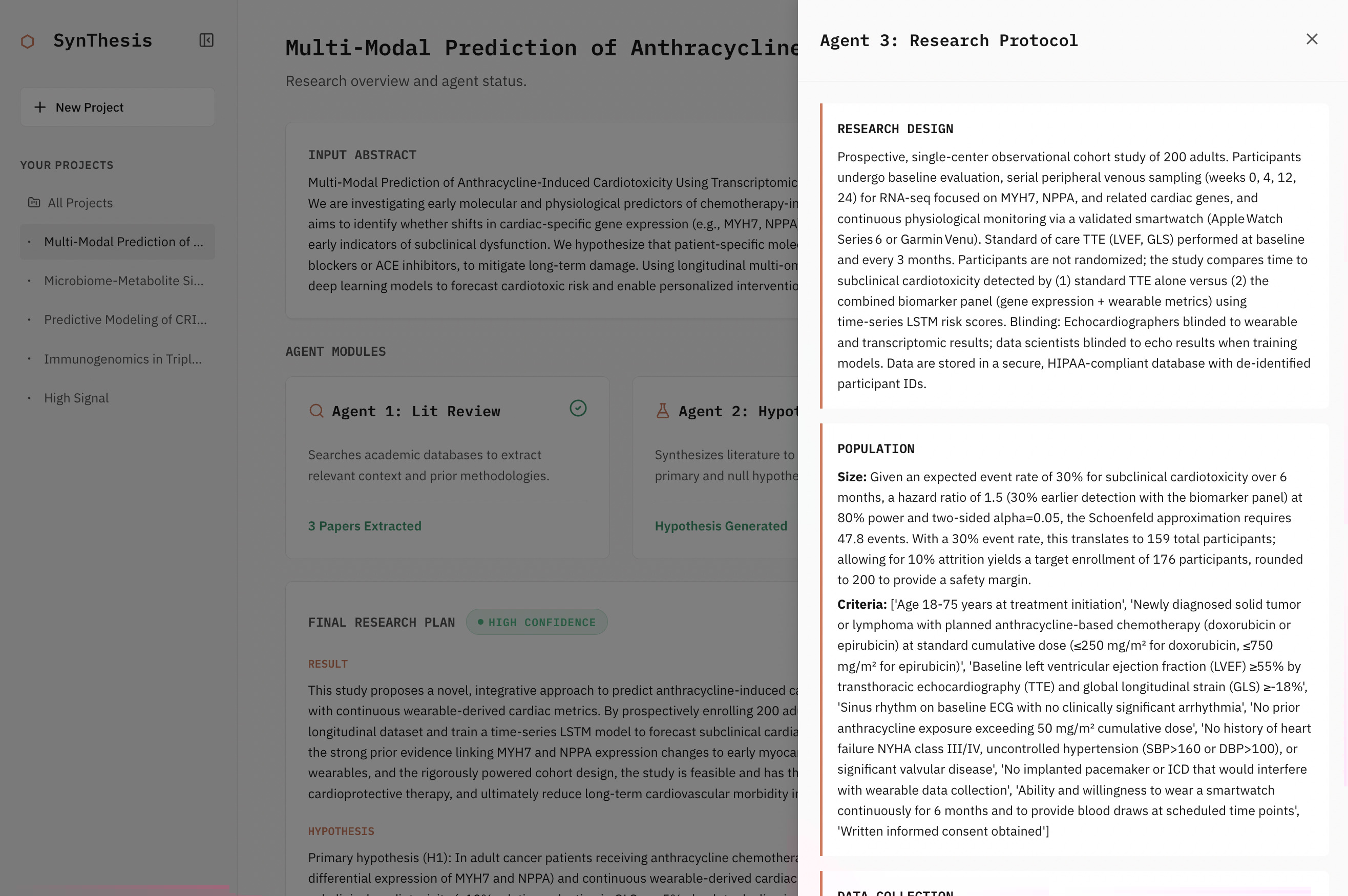
SynThesis takes a single research abstract and produces a complete, structured research plan through a pipeline of specialized AI agents.
A researcher pastes their abstract — for example:
"Does HOX gene expression predict treatment response to menin inhibitors in NPM1-mutant acute myeloid leukemia patients?"
SynThesis then runs four sequential agents:
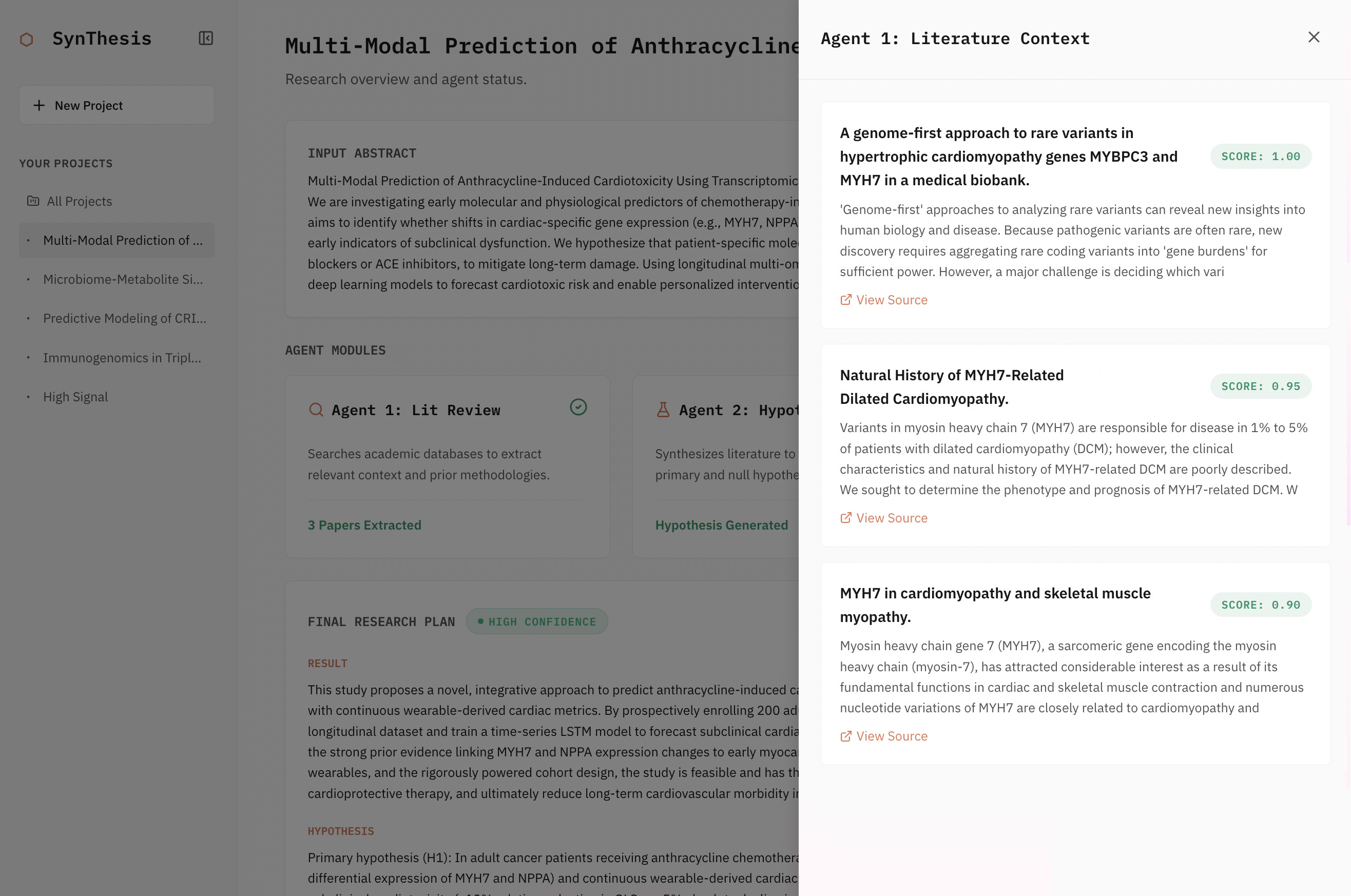
- Literature Review Agent — searches PubMed via the Entrez API, retrieves 5–10 relevant papers, indexes full-text PMC articles into a Ragie.ai RAG store, and synthesizes the current state of the field.
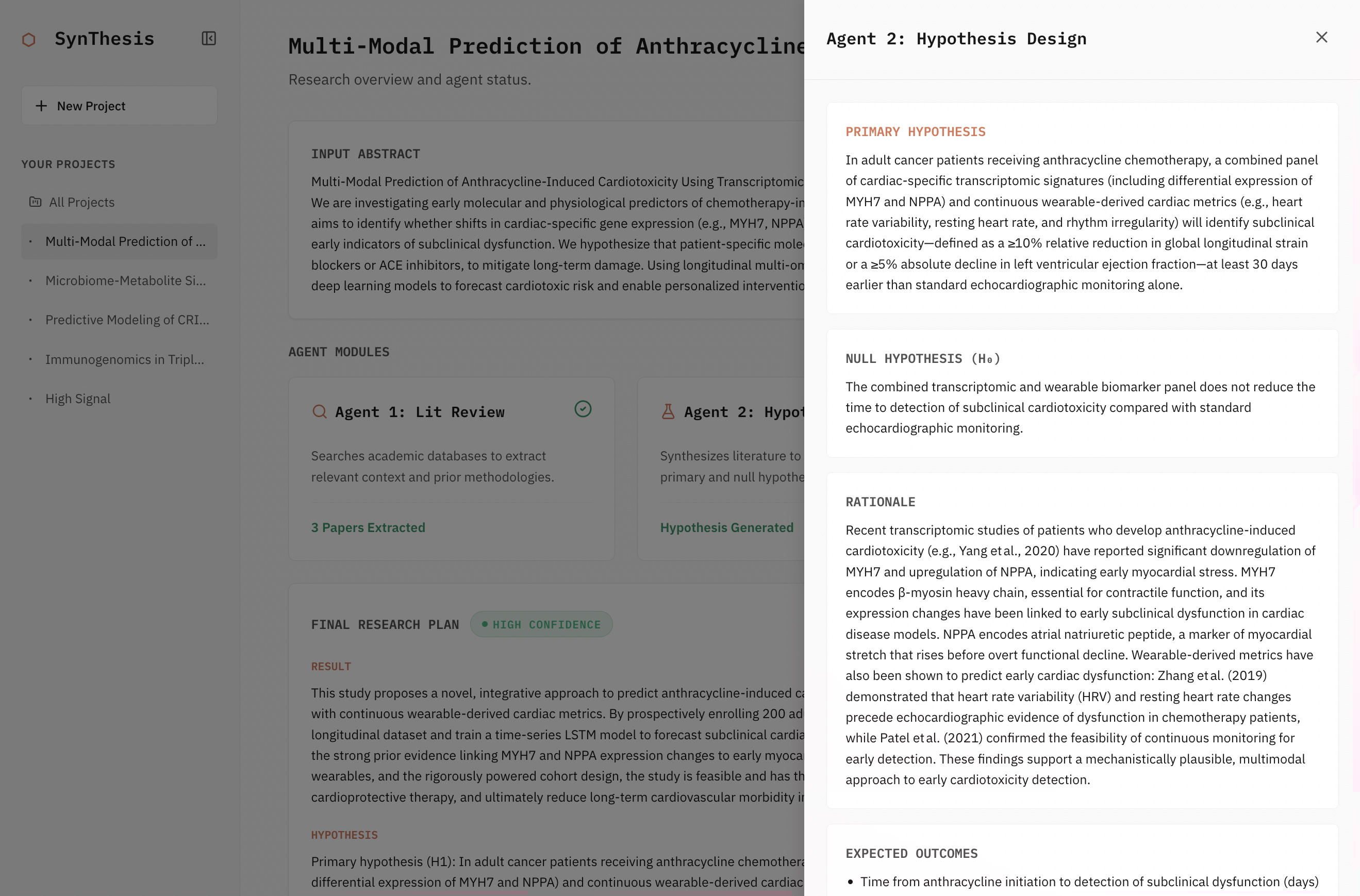
- Hypothesis Design Agent — generates a testable hypothesis ($H_1$) and null hypothesis ($H_0$) grounded in the literature, with an internal self-review loop for quality control.
- Procedure Design Agent — designs the full study: population criteria, sample size, research design, statistical approach, and a realistic timeline.
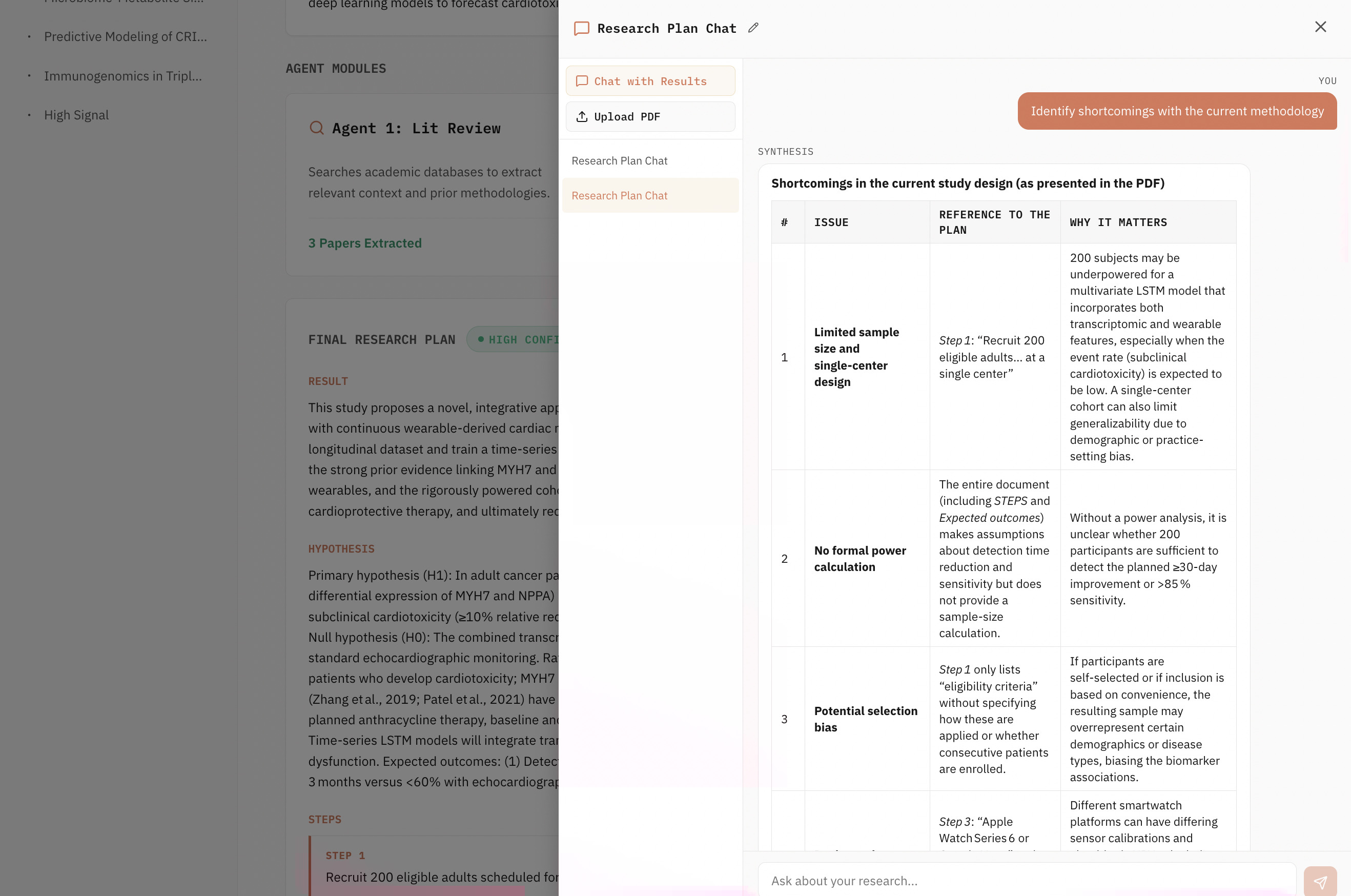
- Orchestrator / Critic — reviews each agent's output against the original abstract and prior literature, triggering revision cycles for any output that doesn't meet quality standards.
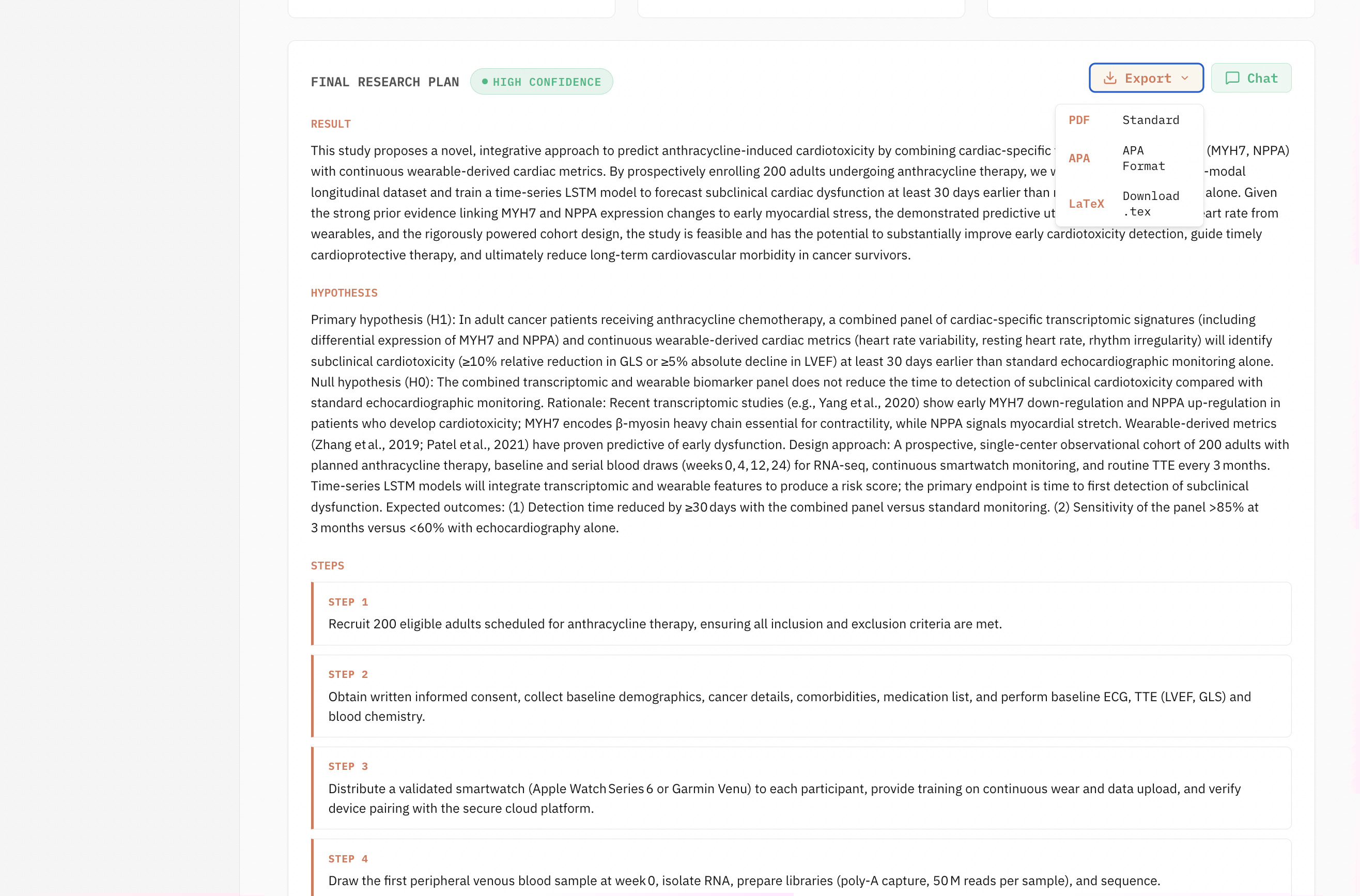
The pipeline concludes with a Final Synthesis: an executive summary, step-by-step action plan, literature citations, a calibrated confidence level (High / Moderate / Low), and explicit caveats.
Results can be exported as a formatted, print-ready PDF directly from the browser — no server-side rendering required.
How We Built It
AI / LLM Layer
Every agent calls openai/gpt-oss-20b via the Groq API, which provides the low-latency inference needed to run a multi-step pipeline in reasonable time. Groq's generous free tier (14,400 requests/day) made it the right choice for a hackathon build. The reasoning model emits <think>...</think> blocks that we strip before parsing, so downstream agents only see clean structured output.
Orchestration
The pipeline is a LangGraph StateGraph — a directed graph of Python nodes where each node is an agent function and edges encode both the happy path and conditional retry loops. All state flows through a single ResearchState TypedDict, so every agent reads exactly what it needs and writes back a well-typed result. This made each node independently testable and kept the graph logic explicit.
Literature Retrieval & RAG
The Literature Agent uses Biopython/Entrez to query PubMed and retrieve paper metadata and PMIDs. Full-text articles are fetched from PMC and uploaded to Ragie.ai, which handles chunking, embedding, and retrieval. This gives the synthesis step access to actual paper content rather than just abstracts.
Backend
A FastAPI server exposes the pipeline over HTTP. The /api/analyze/stream endpoint uses Server-Sent Events (SSE) to push pipeline progress to the frontend in real time — each major stage (literature, hypothesis, procedure, done) emits a JSON event as it completes. Auth is handled via Supabase JWT verification middleware.
Frontend
A React 19 + Vite app with Supabase Auth, row-level security, and a project list / dashboard flow. The pipeline status bar shows live progress as SSE events arrive from the backend. Results are rendered with rich formatting: step cards with accent-coloured borders, clickable citation links, and a colour-coded confidence badge. Includes a client-side PDF export that parses the pipeline's JSON output and renders a formatted HTML report — no extra dependencies required.
Tech Stack Summary
| Layer | Technology |
|---|---|
| LLM | openai/gpt-oss-20b via Groq API |
| Orchestration | LangGraph StateGraph |
| Literature retrieval | PubMed/Entrez (Biopython) |
| RAG | Ragie.ai |
| Backend | FastAPI + SSE streaming |
| Frontend | React 19 + Vite + React Router DOM v7 |
| Persistence & Auth | Supabase (Postgres + RLS + JWT) |
| Language | Python 3.11+ |
Challenges We Ran Into
Structured output from chained agents. Getting gpt-oss-20b to reliably return parseable JSON across long, multi-step prompts — especially when Agent 3 needed to draw on the combined outputs of Agents 1 and 2 — required careful prompt engineering and defensive parsing. We learned that explicit output format constraints in the system prompt, combined with validation before passing state downstream, were essential.
Stripping reasoning traces. The model emits <think>...</think> blocks as part of its chain-of-thought. These are useful for debugging but must be stripped before JSON parsing. Missing this caused silent parse failures early on.
Conditional retry loops. LangGraph's conditional edges made retry logic elegant in theory, but revision count tracking had to be airtight — a missed increment would send the graph into an infinite loop. We added per-agent revision caps and explicit guards in every conditional edge function.
SSE streaming with a synchronous pipeline. Our entire LangGraph pipeline is synchronous — no async/await. Wiring SSE through FastAPI while keeping the pipeline blocking required a generator-based design (run_research_streaming) that yields state after each major stage, which FastAPI flushes to the client incrementally.
SSL on macOS. Biopython's Entrez API calls to PubMed fail silently with certificate errors on macOS due to missing CA bundles. The fix was straightforward (certifi), but diagnosing it cost real time.
Accomplishments That We're Proud Of
- A fully working end-to-end pipeline that turns a one-sentence research question into a structured, cited, critiqued study design in under three minutes.
- The critic loop — having a separate orchestrator agent review and optionally reject each specialist agent's output adds a quality gate that meaningfully improves the final recommendation.
- RAG-backed literature synthesis via Ragie.ai, giving the pipeline access to full paper content rather than metadata alone.
- A PDF export that requires zero server-side rendering — the browser parses pipeline JSON and renders a formatted, printable report with step cards, citation hyperlinks, and a confidence badge.
- Clean RLS-enforced multi-tenancy: every user's analyses are isolated at the database level with no application-layer filtering required.
What We Learned
- Agent specialization beats monolithic prompts. Splitting the task into Literature → Hypothesis → Procedure → Critic → Synthesis, each with a tightly scoped role and output schema, produced far better results than a single large prompt.
- State machines are the right abstraction for multi-agent pipelines. LangGraph's
StateGraphforced us to be explicit about what each node reads and writes, eliminating a whole class of subtle bugs around stale or partially-updated state. - Streaming UX is non-negotiable for long-running AI pipelines. A pipeline that takes 2–3 minutes is unusable without live progress feedback. The SSE endpoint transformed the experience from "did it freeze?" to watching the agents think step by step.
- Groq's model routing (
openai/gpt-oss-20bserved through the Groq API) gave us a capable reasoning model with sub-second time-to-first-token, which made the interactive streaming experience feel responsive.
What's Next for SynThesis
- IRB and ethics check agent — automatically flag study designs that would require additional ethical review (vulnerable populations, invasive procedures, sensitive data).
- Statistical power calculator — integrate a formal power analysis step that recommends sample size given an expected effect size and desired $\beta$, grounded in the papers the system already read.
- Journal-specific procedure templates — tailor the procedure design agent to output in the format required by specific journals (CONSORT for RCTs, STROBE for observational studies, PRISMA for systematic reviews).
- Collaborative workspaces — let multiple researchers share, comment on, and branch from the same analysis session in real time.
- Institutional corpus support — allow labs to upload their own preprints and unpublished data so the literature agent can search internal knowledge alongside PubMed.
Built With
- biopython
- fastapi
- groq
- javascript
- langchain
- langgraph
- postgresql
- python
- react
- supabase
- vite



Log in or sign up for Devpost to join the conversation.