Inspiration
We were thinking of ideas, and looked at the Y Combinator Wishlist for Spring 2026. One of the ideas on there was regarding a cursor for product management, and we thought this is a prevalent problem that we could solve.
What it does
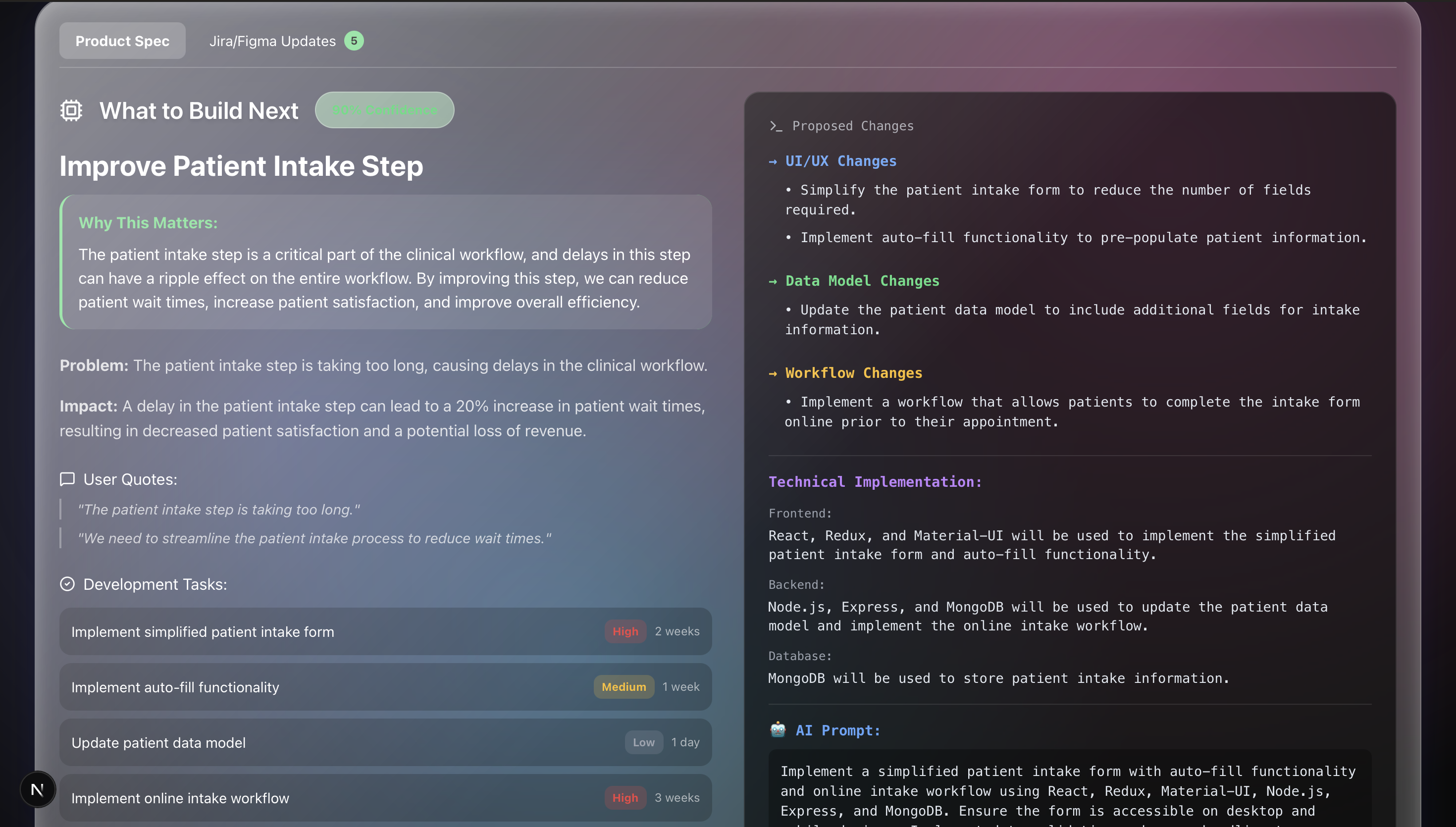
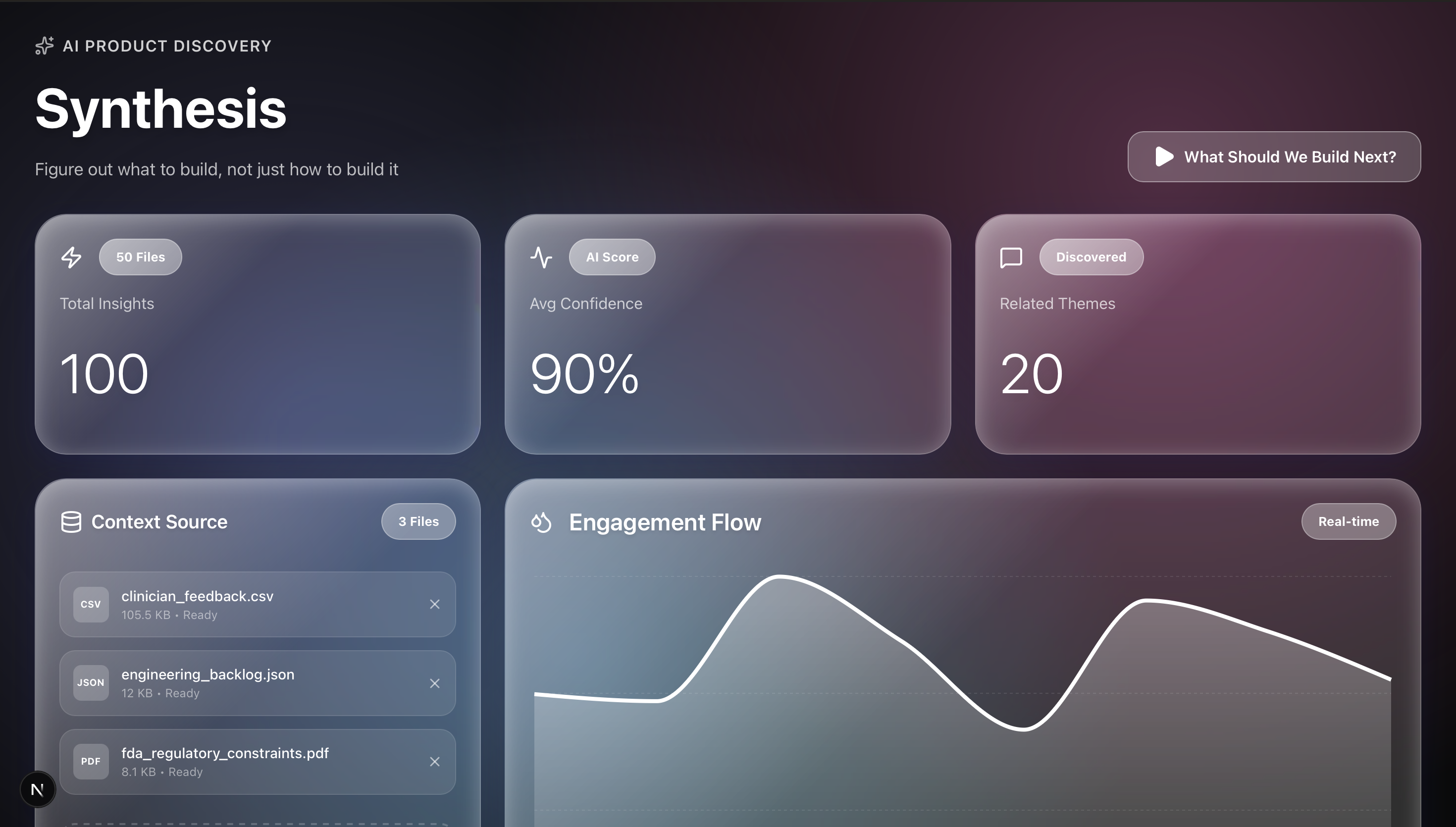
Synthesis assists companies and their engineers come up with ideas for future products and improving new products by being fed information about user reviews/concerns about existing products, legal regulations related to the company, and engineering backlogs. Instead of a Product Manager analyzing all of these individually, Synthesis is able to review these all at once and provide feedback regarding future product ideas, and unfixable issues with existing products.
How we built it
Our product was built on a modern Next.js and TypeScript stack, ensuring rapid development and a polished user experience. We leveraged Featherless.ai to run Meta's Llama 3.1 70B model, taking full advantage of its powerful reasoning capabilities and large context window. Instead of a complex RAG pipeline, we architected a system for real-time context injection, allowing our AI to process disparate file formats (CSV, JSON, PDF) simultaneously and with high fidelity. This approach ensures the model has direct access to raw user feedback and regulatory documents without losing nuance in vector embeddings.
Challenges we ran into
One of the biggest challenges was Data Heterogeneity. We had to build a system that could parse and align a "latency" complaint in a CSV file directly alongside a "Refactor API" ticket from a JSON file, all while respecting strict "SaMD" constraints found in uploaded PDFs. Formatting these diverse schemas into a cohesive narrative for the AI to reason across was a significant hurdle. Additionally, Context Management was critical; we refined our prompt engineering to ensure the AI prioritized uploaded documents over general knowledge, strictly adhering to the provided constraints.
Accomplishments that we're proud of
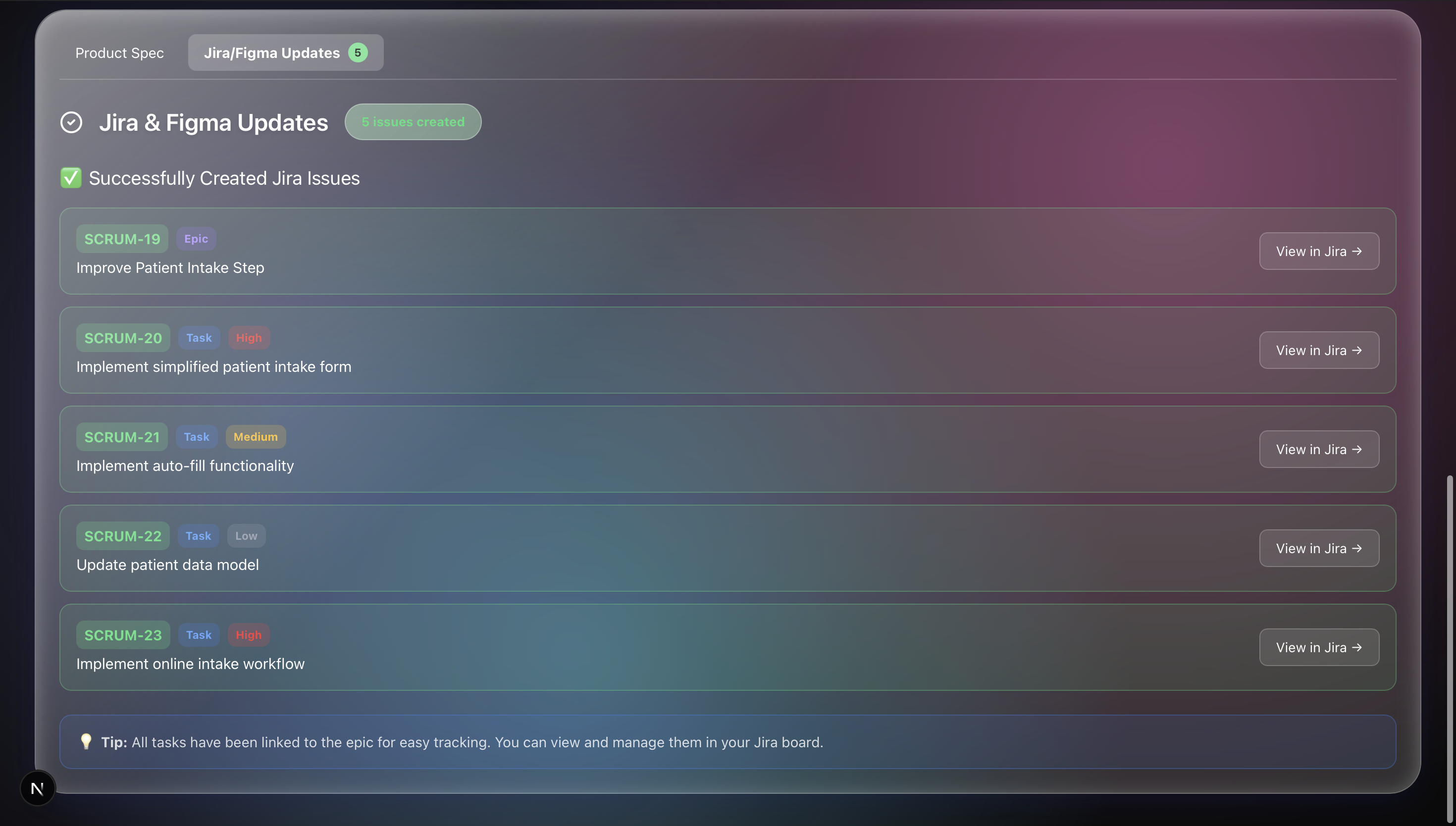
We are proud to have built a project that takes files in different formats and is able to analyze all of them simultaneously to provide coherent feedback. A major milestone for us was successfully integrating both Jira and Figma into our workflow; Synthesis doesn't just suggest ideas, it can cross-reference existing engineering tickets to see if a feature request is already in progress, while simultaneously pulling in live design context from Figma files. Finally, we are also proud to build something that has real world applications and impact. As engineers, our goals include creating technology that solves real-world problems, and this project was a step towards that goal.
What we learned
We learned the importance of Context-Aware AI. Having good data and structuring it correctly for an LLM is extremely helpful in getting high-quality feedback. We discovered that with modern models like Llama 3.1, direct context injection can be incredibly powerful for synthesizing complex documents. We also gained deep experience with the Jira API and how to bridge the gap between product ideation and engineering execution. Furthermore, we learned about Retrieval-Augmented Generation (RAG), and how important it is for our project. Since we wish to make our product applicable to various fields, RAG is important so that Synthesis is always able to give accurate information based on facts.
What's next for Synthesis
We hope to incorporate features that allow a user to manage various products on their account and allow live data to be fed into Synthesis to generate feedback. Live data includes tickets from customer feedback websites, etc.



Log in or sign up for Devpost to join the conversation.