-
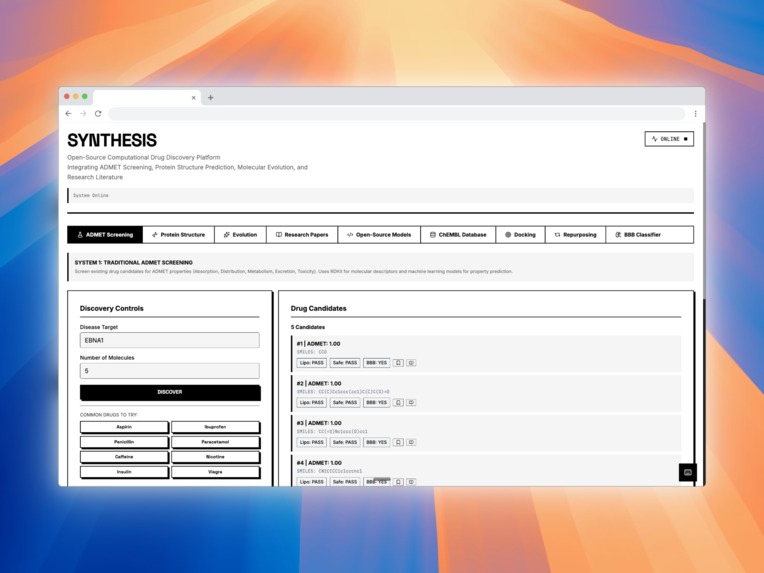
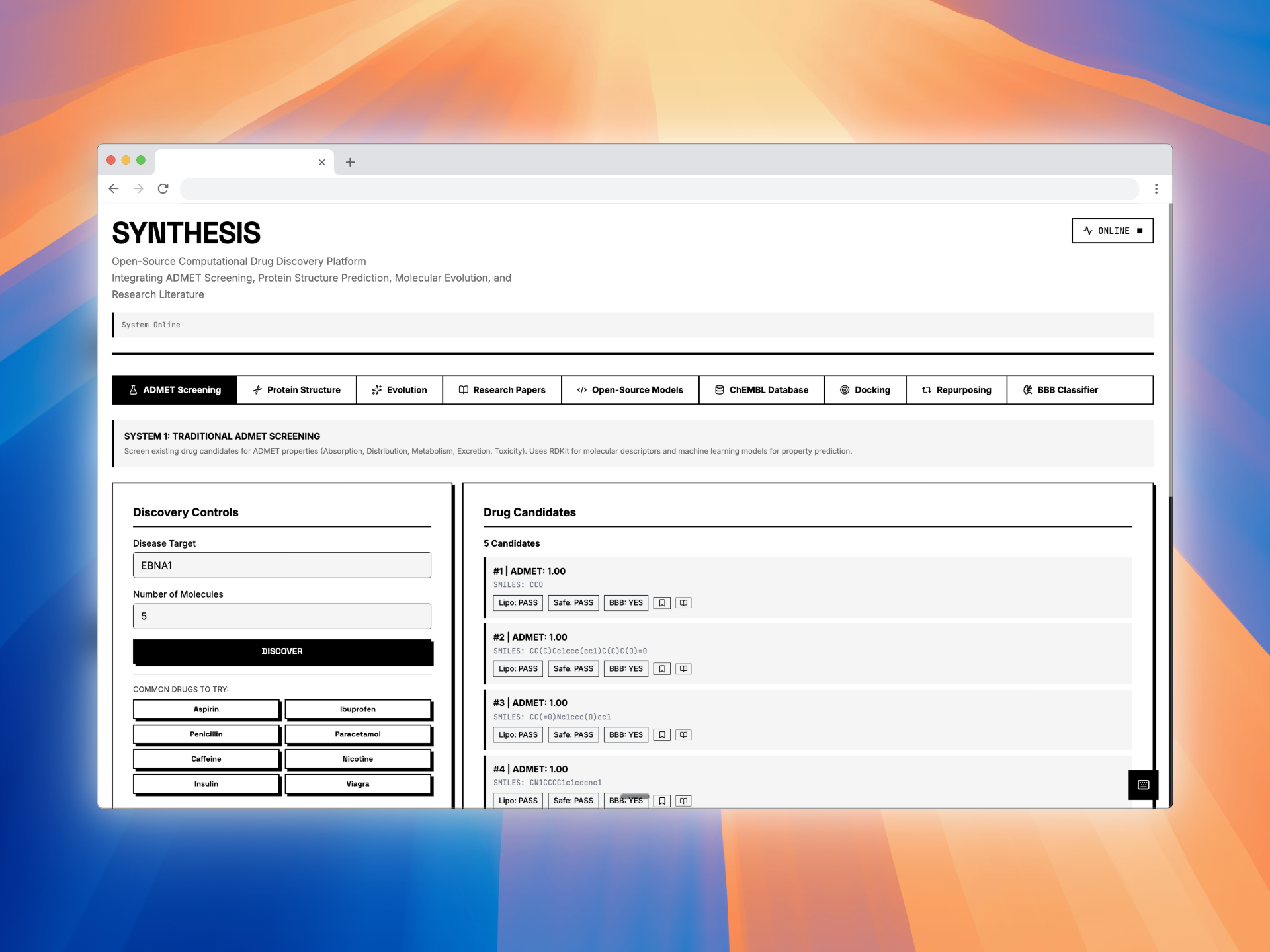
Home page of the Synthesis platform
-
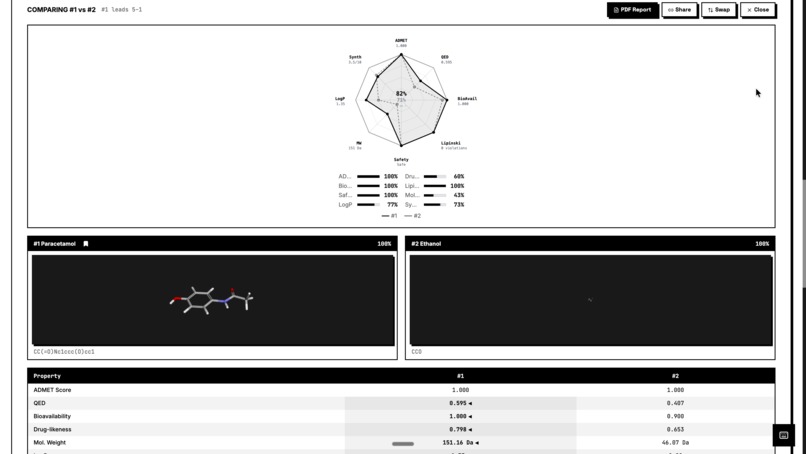
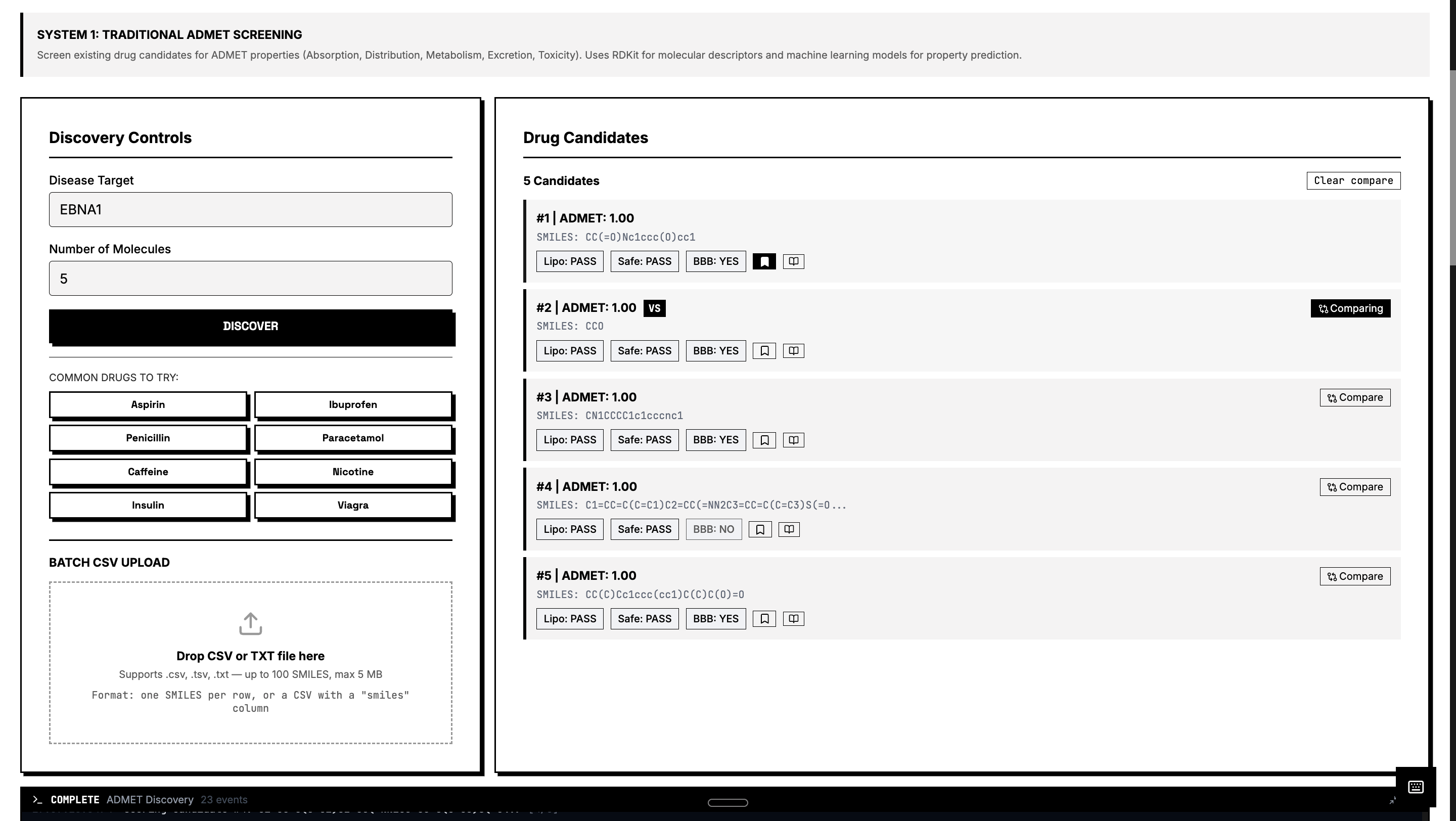
ADMET Screening
-
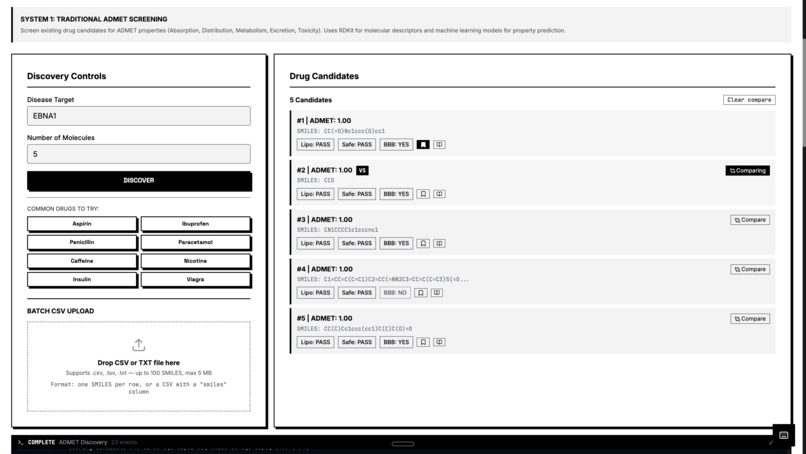
ADMET Screening
-
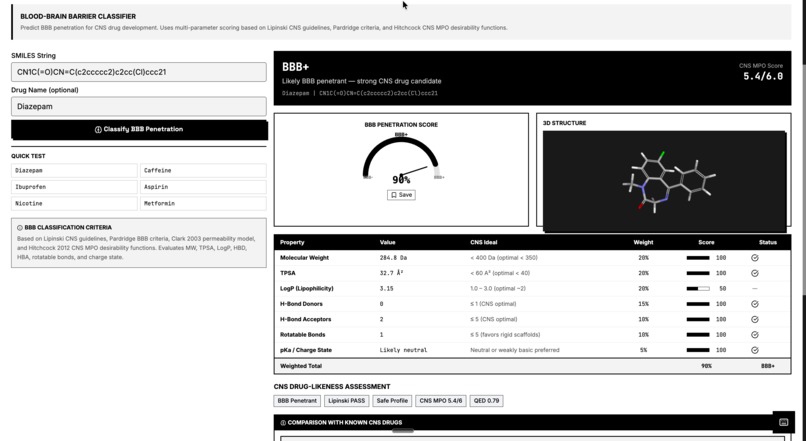
Repurposing
-

Literature
-
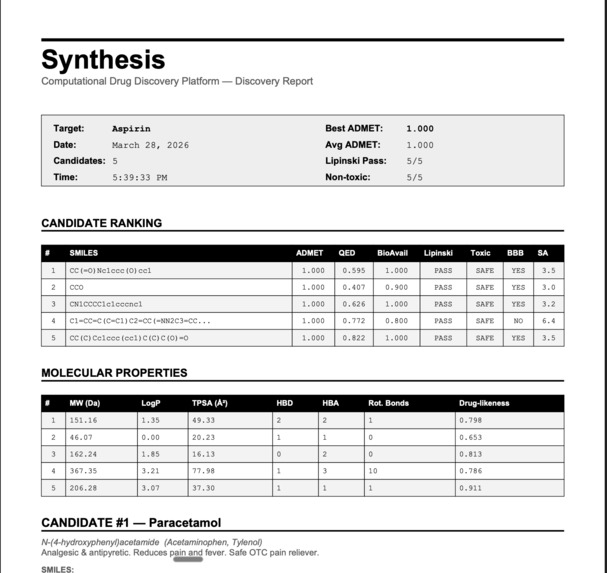
Report
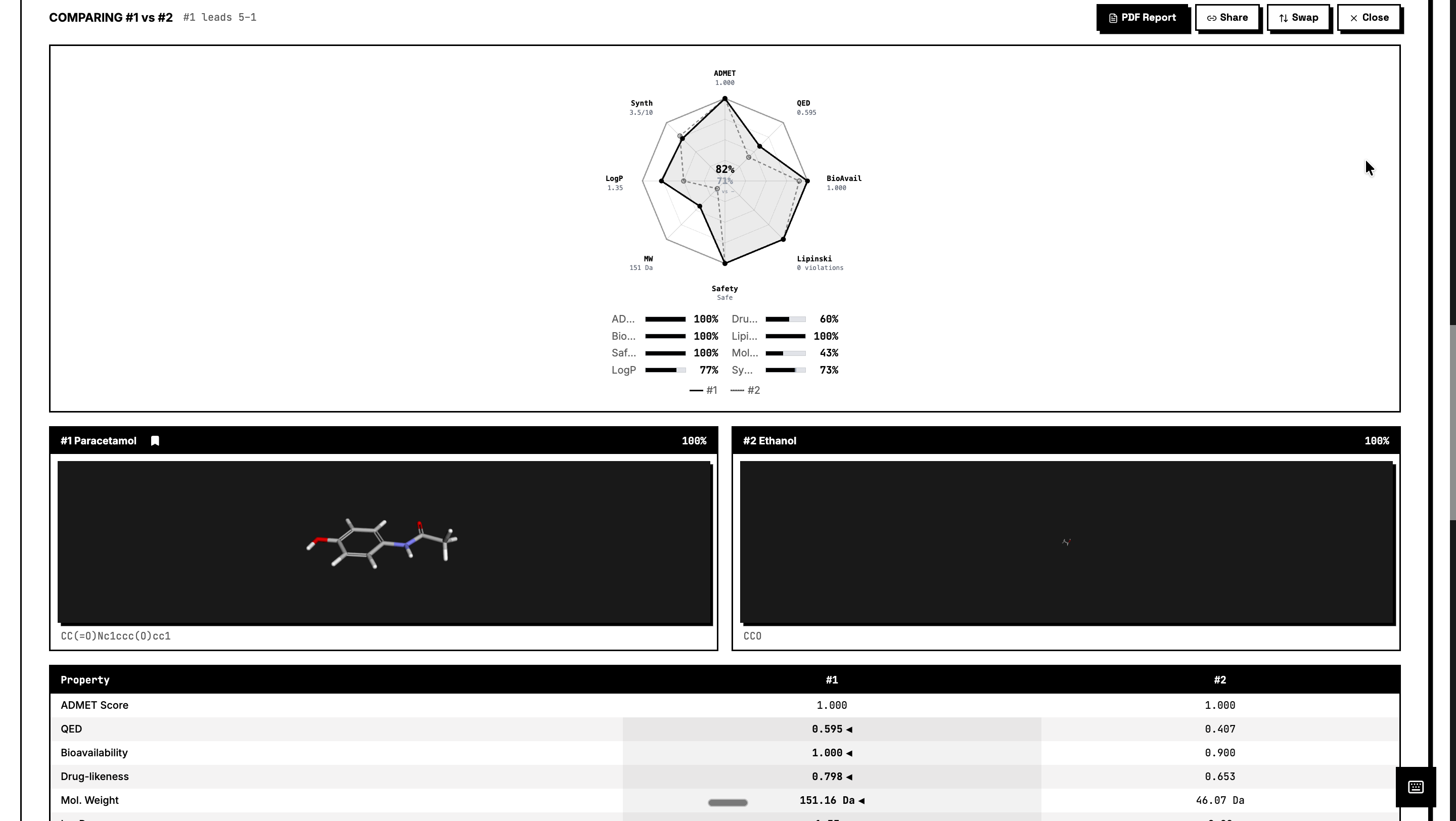

Inspiration
Drug discovery is slow, expensive, and often inaccessible to smaller labs, students, and independent researchers. The traditional pharmaceutical pipeline can take over a decade and billions of dollars to bring a single drug to market.
We wanted to build SYNTHESIS — an open-source computational drug discovery platform that puts powerful bioinformatics, molecular modeling, and AI tools into one unified, accessible system. Instead of researchers juggling disconnected software and datasets, SYNTHESIS integrates everything into a single intelligent workflow.
What it does
SYNTHESIS is a modular, drug discovery platform that integrates:
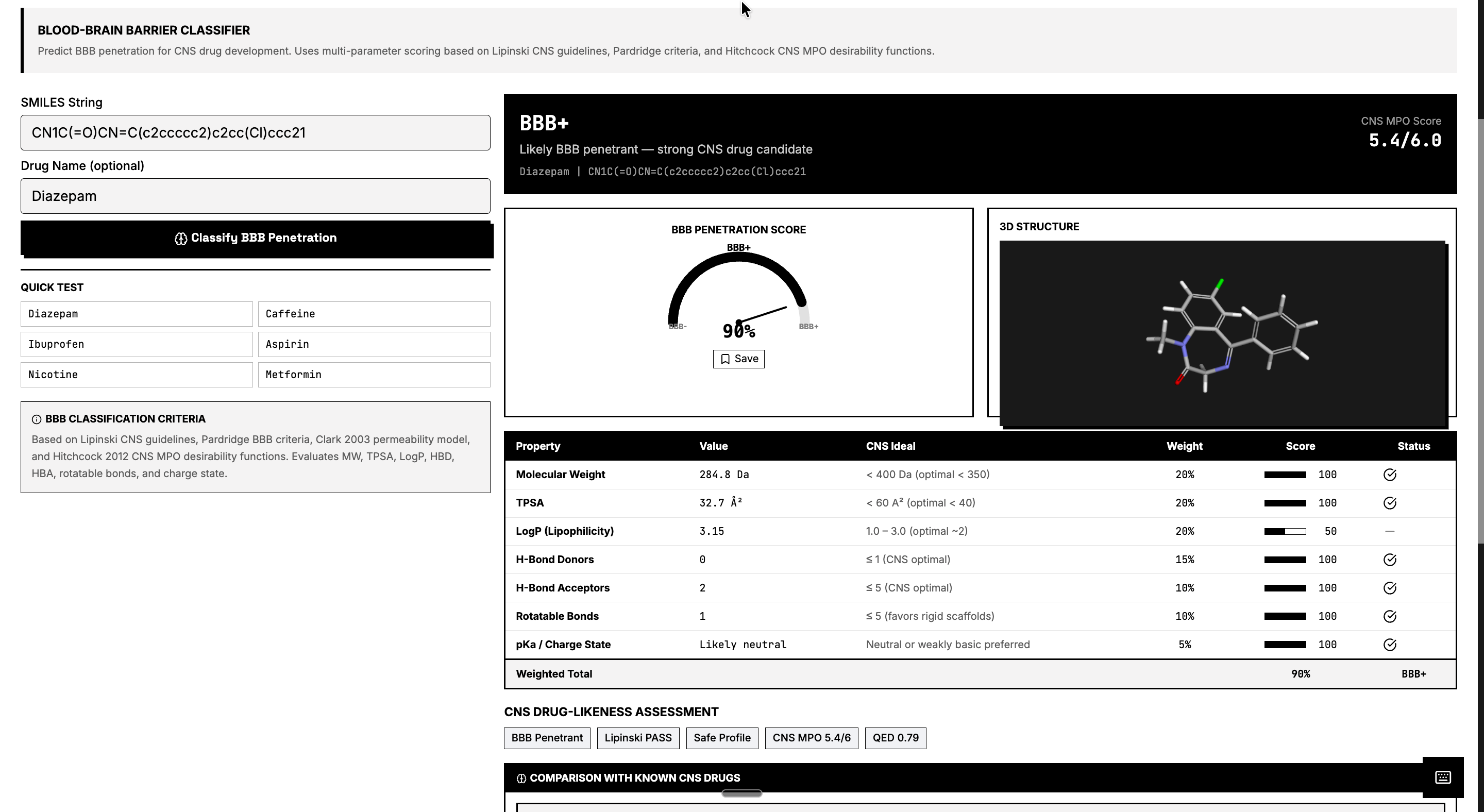
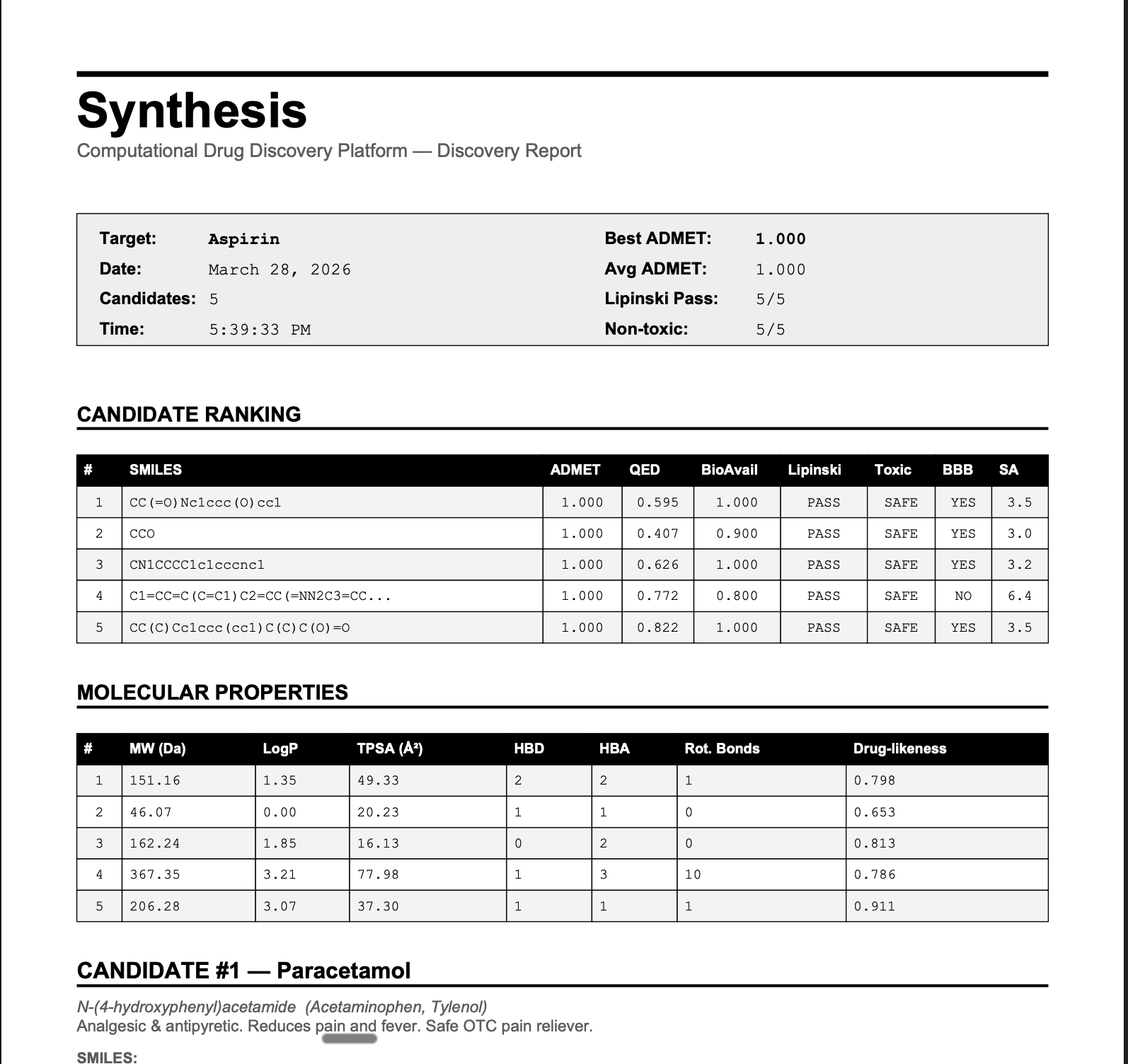
ADMET Screening – Predicts Absorption, Distribution, Metabolism, Excretion, and Toxicity using RDKit molecular descriptors and machine learning models. Protein Structure Prediction – Predicts 3D protein structures using Meta’s ESMFold and retrieves experimental structures from the RCSB PDB when available. Molecular Docking Simulation – Simulates protein-ligand binding using AutoDock Vina principles to estimate binding affinity (kcal/mol). Drug Repurposing Engine – Identifies new therapeutic targets for approved drugs using molecular profiling and explainable AI. Blood-Brain Barrier Classifier – Predicts CNS penetration using Lipinski CNS rules, Pardridge criteria, and Hitchcock CNS MPO scoring. ChEMBL Integration – Searches 2.4M+ bioactive molecules with real-world activity data. PubMed Research Search – Queries 36M+ biomedical publications to connect computational predictions with scientific literature.
How we built it
SYNTHESIS integrates over 40 open-source tools and resources from the computational chemistry community such as:
RDKit for cheminformatics and molecular descriptor calculation MolGAN for generative molecular evolution ESMFold for protein structure prediction AutoDock Vina concepts for docking simulations ChEMBL & PubMed APIs for real-world bioactivity and literature integration SYNTHESIS integrates these open-source tools into a unified platform, enabling users to seamlessly access and combine advanced computational drug discovery methods in one place — making the drug discovery process more efficient, accessible, and collaborative.
Challenges we ran into
Challenges we ran into Model interoperability – Integrating cheminformatics tools, protein structure predictors, generative models, and docking simulations into a seamless pipeline required consistent data formatting and error handling. Network and Deployment - While running our platform, we frequently encountered network issues and 404 errors whenever we tried to access certain open-source tools. This was one of our most frustrating challenges. We solved it by
Accomplishments that we're proud of
We built a fully integrated computational drug discovery pipeline during the hackathon, implementing AI-guided molecular evolution with property-based selection. By resolving data incompatibilities between open-source tools, we combined protein structure prediction, docking simulations, ADMET screening, and literature validation into a single unified system. SYNTHESIS was designed to be open-source, modular, and extensible, creating a platform that mirrors real-world pharmaceutical R&D entirely with freely available tools.
What we learned
The absolute most important thing we learned was biology, chemistry, and drug development is not a scientific challenge, it is an accessibility problem. Integration is harder than implementation – Combining multiple open-source tools revealed challenges in data formats, API inconsistencies, and workflow compatibility. Drug discovery is a multi-objective optimization problem – A molecule must balance binding affinity, ADMET properties, and toxicity; optimizing one metric alone is insufficient. Open-source tools are powerful but require adaptation – Freely available models and databases are robust, but making them work together required creative coding and problem-solving. Explainability matters – AI predictions without mechanistic context are limited; connecting outputs to literature and bioactivity data made results more meaningful. Collaboration across disciplines is essential – Bridging AI, chemistry, and biology accelerated our learning and highlighted the importance of cross-disciplinary thinking
What's next for SYNTHESIS
Deploy a scalable cloud backend for larger docking and protein prediction tasks. Add reinforcement learning for more advanced molecular evolution. Incorporate wet-lab validation partnerships. Expand explainability modules for ADMET and docking predictions. Build a researcher-friendly UI for real-time molecular iteration. Open the platform to community contributions and benchmarking datasets.


Log in or sign up for Devpost to join the conversation.