-
-
Synthease Dashboard
-
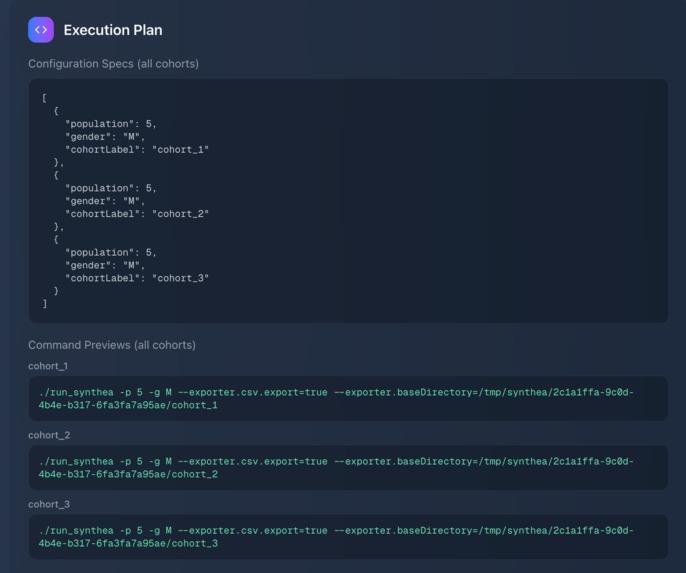
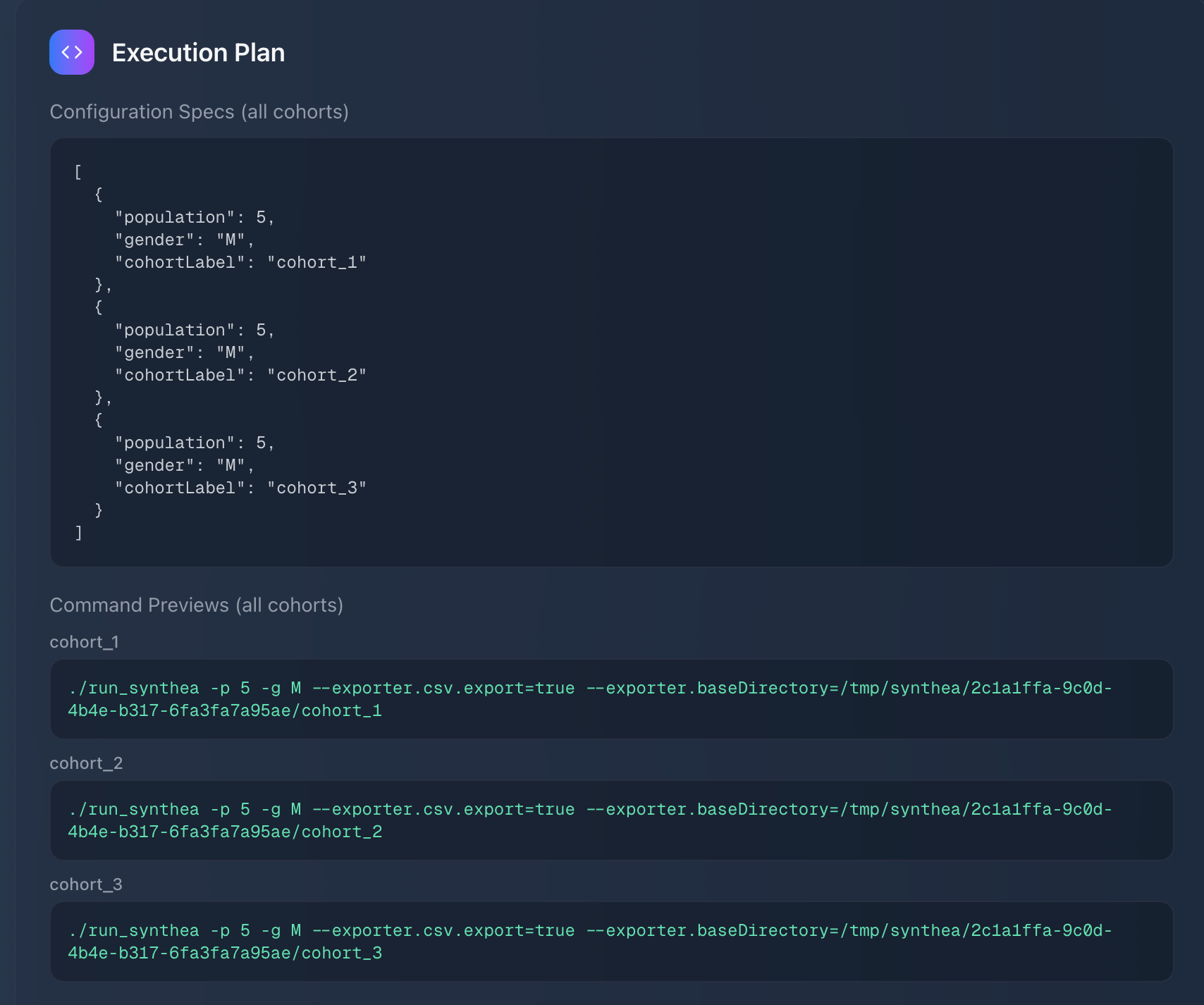
Gemini Synthea Command Planning
-
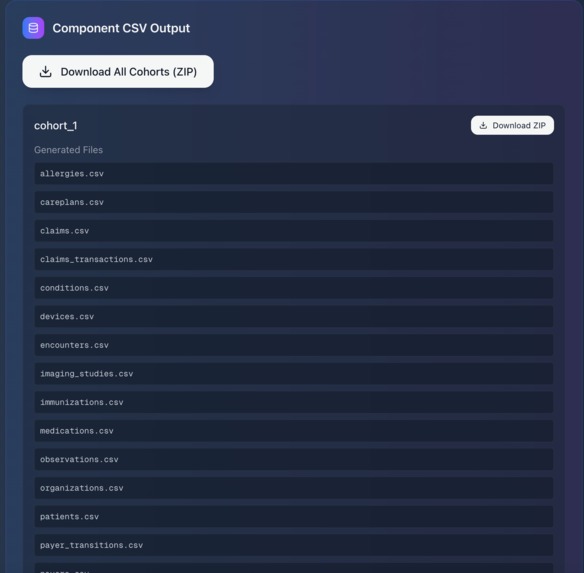
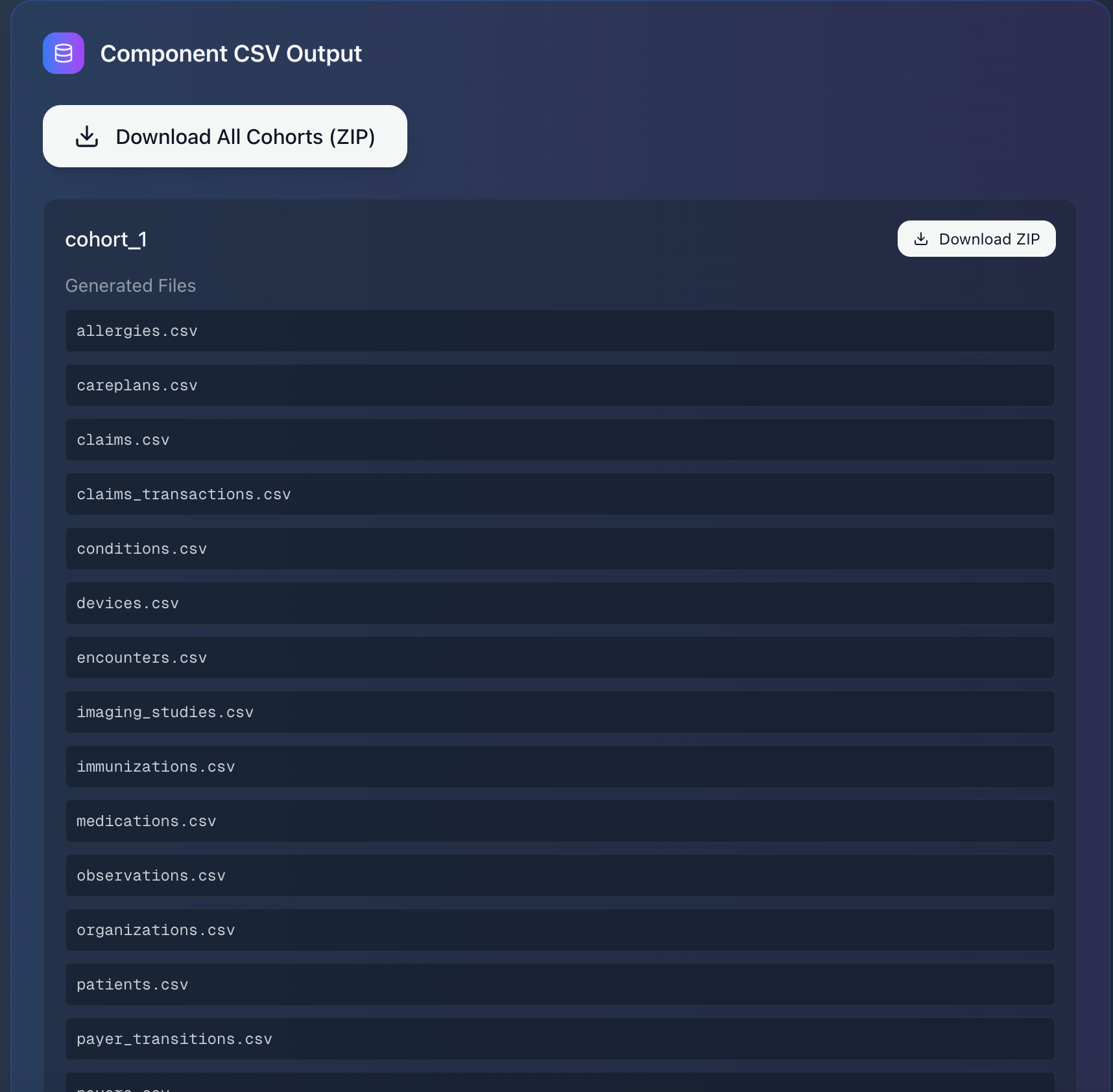
Downloadable CSV Output
Inspiration
We were inspired by AnimalGAN, which generates animal testing data to reduce reliance on live experiments. We asked ourselves: what if researchers could simulate patient populations the same way?
Clinical trials are expensive, slow, and often exclude vulnerable or underrepresented groups like children, seniors, or patients with rare conditions. These limits constrain the evidence base, slow scientific progress, and deepen inequities for communities historically overlooked in research.
With our passion for health and medical research, we built Synthease to close this gap — making it possible to simulate longitudinal studies, stress-test predictive models for risky treatments, and explore scenarios that sampling bias or ethical constraints make nearly impossible.
What it does
Synthease is a plain-language interface for generating synthetic patient datasets using Synthea.
Synthea generates highly realistic synthetic health records that mirror the complexity of real-world electronic health data. Each simulated patient includes a full, birth-to-current age medical history with encounters, diagnoses, medications, labs, procedures, and outcomes, all encoded with standard clinical codes like ICD-10, SNOMED, RxNorm, and LOINC. The underlying modules are evidence-based, built from clinical guidelines and national prevalence statistics to ensure that disease progression, treatment patterns, and outcomes align with real-world medicine. The data spans multiple domains, including chronic and acute conditions, preventive care, treatments, and social determinants, making it both longitudinal and comprehensive.
A researcher types: “Create 3 cohorts of 20 seniors each from Florida”.
Google’s Gemini API interprets the request into structured Synthea commands.
In seconds, Synthease produces realistic, privacy-safe datasets, enabling faster research, teaching opportunities, and fairer representation.
The results are exported into both component-level CSVs (conditions, encounters, medications, etc.) and patient-centric CSVs (all records grouped by individual), making the data immediately usable for analysis, teaching, and exploration.
This directly supports key areas of social impact:
- Knowledge: democratizing access to health data and expanding the evidence base for research.
- Skills & Learning: equipping students, nonprofits, and non-technical users with intuitive research tools.
- Scientific Progress: accelerating discovery without risking patient privacy, harm to vulnerable populations, or wasted resources.
- Stronger Communities: ensuring research reflects and represents every community.
How we built it
- Frontend: Built with Next.js and TailwindCSS to create a modern, accessible UI where users can enter plain-language prompts.
- AI Planning Layer: Used Google’s Gemini API not just as a translator but as a planner. Gemini parses prompts into structured specifications, handling cohort sizes, age ranges, gender splits, and conditions. We designed a schema with validation rules (via Zod) to ensure outputs always align with valid Synthea configurations.
- Simulation Engine: Integrated Synthea, an open-source synthetic patient simulator. Each run produces detailed longitudinal patient records, including conditions, encounters, medications, and procedures, reflecting the complexity of real-world clinical data.
- Data Handling & Transformation: Exported results into both component-level CSVs (segmented by encounters, diagnoses, labs, etc.) and patient-centric CSVs (all records grouped by individual). This mirrors how datasets are prepared for downstream tasks like survival analysis, predictive modeling, or fairness auditing.
- Reproducibility: Each execution plan is logged with cohort specs, random seeds, and exact Synthea commands. This ensures that experiments can be repeated, verified, and compared, which is a cornerstone of credible research workflows.
- Scalability & Research Readiness: Designed the backend to organize outputs into labeled cohort directories, making multi-cohort studies possible.
Challenges we ran into
- Teaching Gemini to correctly split multi-cohort prompts.
- Balancing technical flexibility with an intuitive design for non-technical users.
Accomplishments that we're proud of
- Built a working MVP that can generate complete synthetic datasets from natural-language prompts.
- Extended Gemini AI beyond simple translation — it now parses multi-cohort, nuanced research requests and orchestrates valid Synthea simulations.
- Created an intuitive UX that lowers the barrier for students, nonprofits, and researchers.
- Showcased how AI can empower stronger communities by making data inclusive and accessible.
What we learned
- Synthetic data is a powerful tool to accelerate reproducible research, enable testing of new methods, and expand studies where real patient data is limited or inaccessible.
- AI planning can unlock knowledge by translating human intent into precise technical actions.
- Tools for social good need to be usable by everyone, not just experts.
- Ethical AI can directly drive scientific progress while protecting vulnerable communities.
What's next for Synthease
- Introduce user accounts and personal dashboards so individuals can sign in, store their generated CSVs, revisit past runs, and interact with their datasets over time.
- Expand into team accounts and shared workspaces, enabling labs, nonprofits, and research groups to collaborate on dataset generation, storage, and analysis in one environment.
- Implement fairness auditing pipelines to validate that generated cohorts reflect real-world populations.
- Build an open library of ready-to-use synthetic datasets for educators, nonprofits, and public health organizations.
Built With
- archive
- gemini-api
- next.js
- node.js
- react
- synthea
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.