-
-
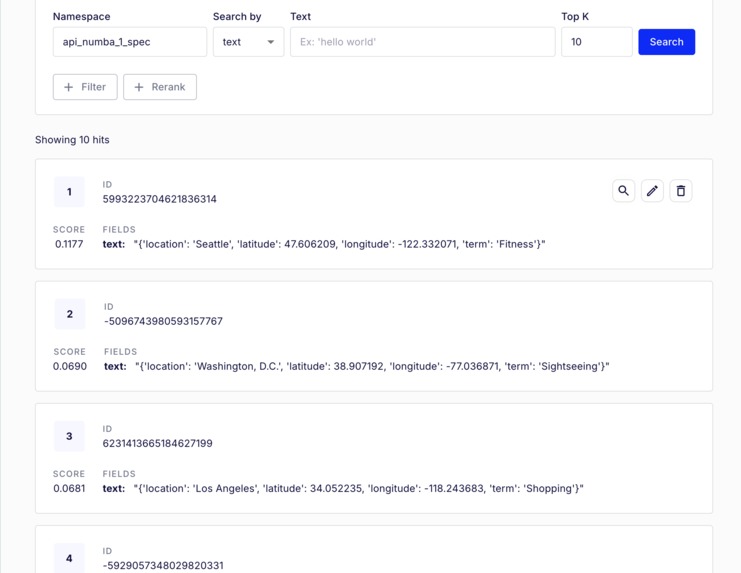
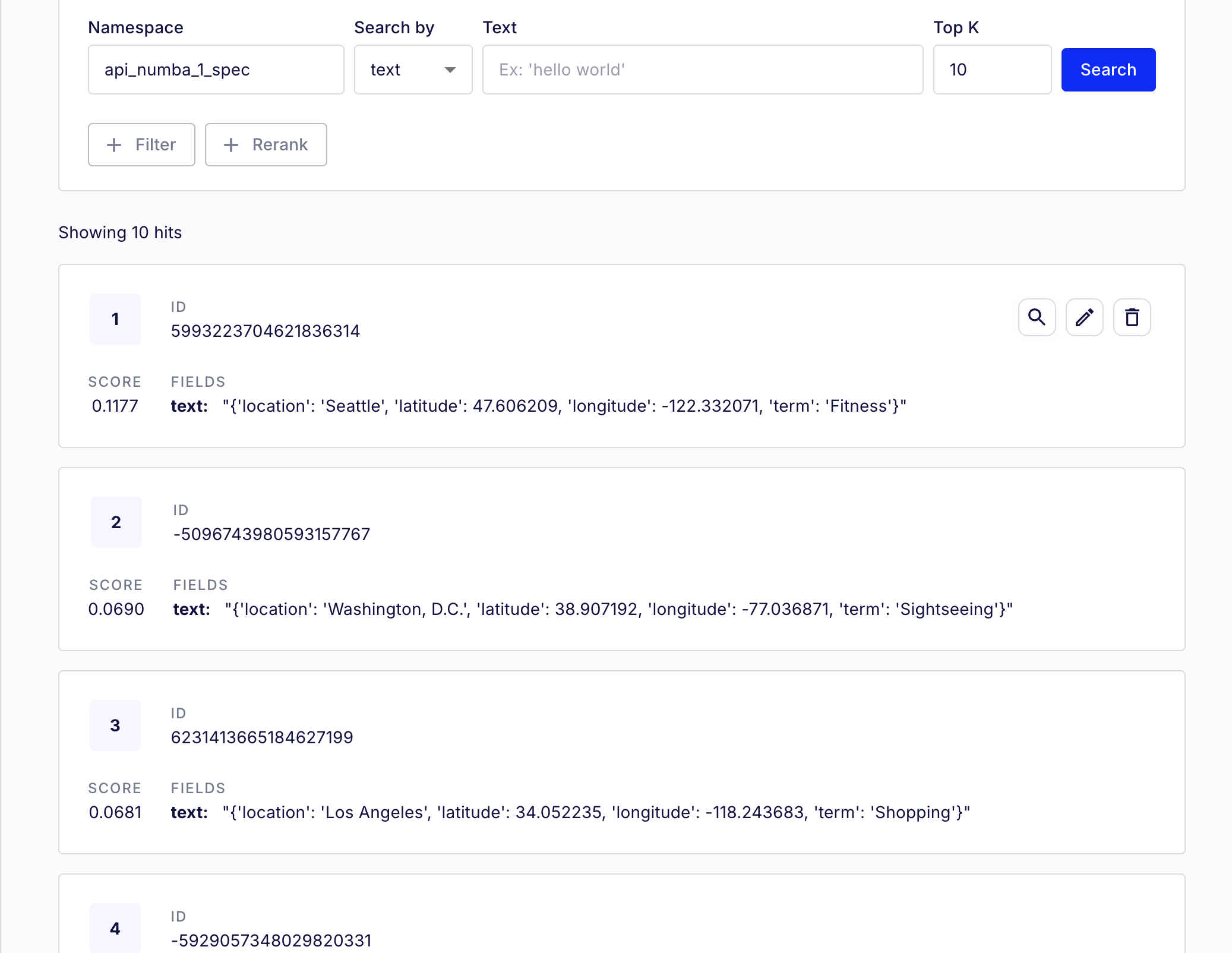
VectorDB Populated with Synthetic Data for a City API
-
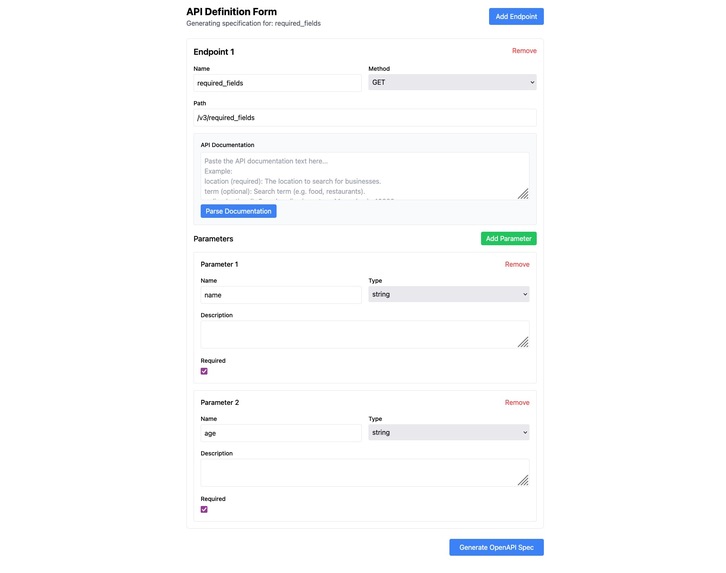
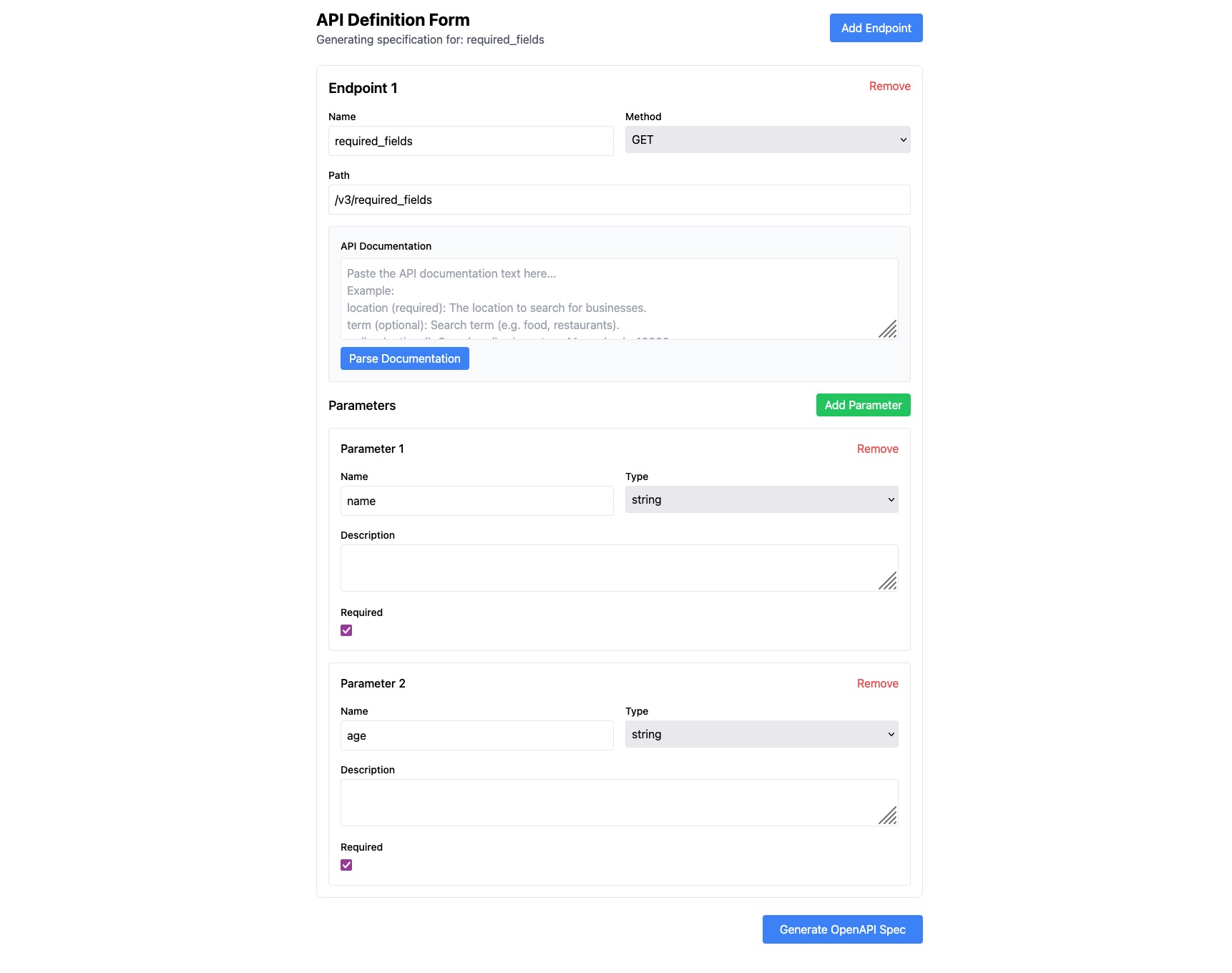
Screenshot of the OpenAPI Spec Creation Form
-
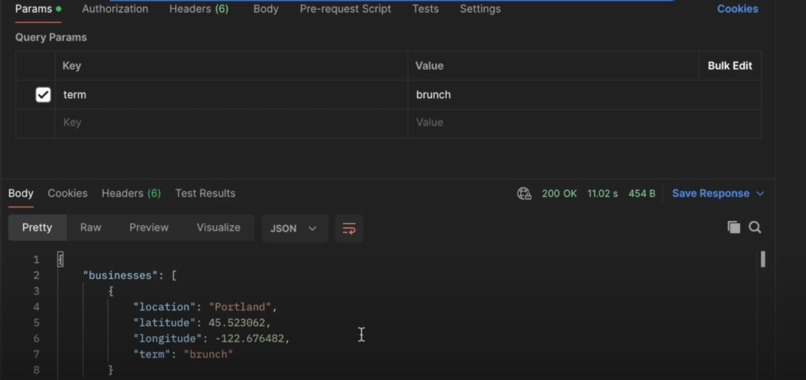
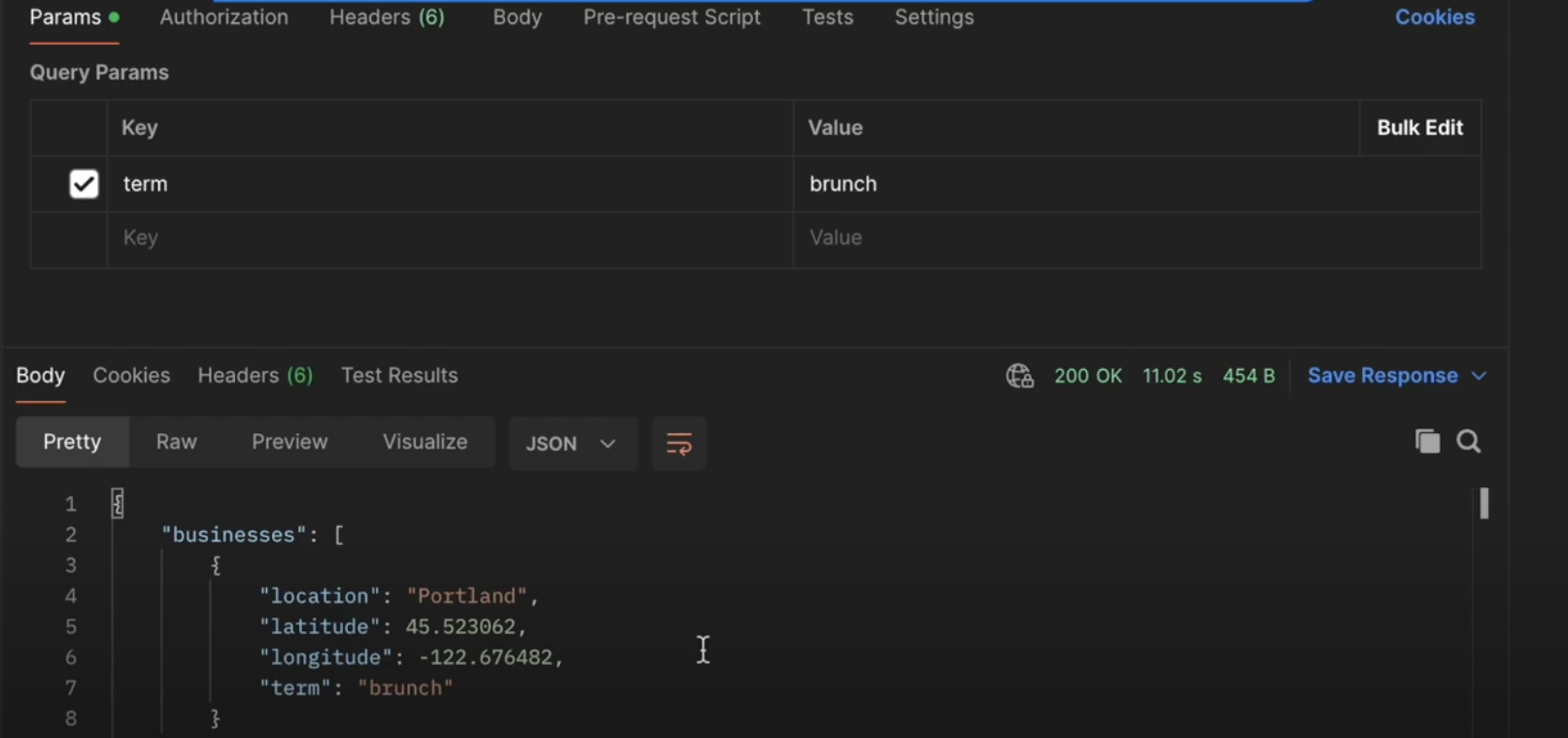
Screenshot of a Sample API Request Using a Copy of Yelp Fusion API on our Lambda
Inspiration
Private APIs are increasingly becoming a barrier to innovation. When developers face expensive paywalls, lengthy application processes, and restrictive rate limits for APIs like X/Twitter, Yelp Fusion, and OpenMenu, it stifles rapid prototyping and experimentation - especially for individuals and small teams.
For us, hurdles with APIs cost us a full day. Our first idea, related to healthcare, was gated by Apple's research proposal requirement to access iWatch and iPhone SensorKit data. Our second, focusing on finding food options for people with rare or uncommon food allergies, was one that we got farther on but was still blocked by APIs requiring hundreds to thousands of dollars annually to get data for a weekend project.
That led us to creating Synth API - why waste time, money, and effort trying to find or create an API when you can simply give us a description of the API you want and focus on your product, and we'll take care of the rest.
What it does
Synth API creates instant, simulated API environments based on standardized OpenAPI specifications. Developers simply define their expected API structure, and our platform automatically generates a synthetic dataset and API endpoints that mirror the real thing. This enables teams to prototype and develop without the constraints of traditional API access barriers.
How we built it
Our three-stage architecture leverages AWS services and LLMs:
- OpenAPI spec generation through a CLI/form interface, enhanced by LLM for descriptions
- Synthetic data generation via AWS Lambda and LLMs, stored in VectorDB with embeddings
- Intelligent endpoint simulation using Bedrock Agent for context-aware responses
Challenges we ran into
Maintaining data consistency across complex API relationships while generating synthetic data proved challenging. We also had to carefully architect our Lambda functions and VectorDB queries to ensure low latency responses that felt like real APIs.
Accomplishments that we're proud of
We built a fully automated pipeline that takes developers from API spec to working endpoints in minutes instead of days or weeks. The system generates contextually aware synthetic data and maintains referential integrity across endpoints - something that traditionally requires significant manual effort, resources, or more available time than people may have.
What we learned
Integrating LLMs for API simulation requires careful prompt engineering and architectural decisions. We gained deep insights into synthetic data generation and the importance of maintaining semantic consistency across interrelated API endpoints.
What's next for Synth-API
In the future, we want to be able to reduce latency and add the ability for users to run multiple simulated APIs truly simultaneously instead of sequential Lambda calls. Also, potentially allowing users to control generated data on a more granular basis (i.e. distributions for numerical variables, enums, descriptions for specific strings, etc.).
Built With
- amazon-web-services
- api
- bedrock
- chatgpt
- embedding
- genai
- lambda
- llama
- llm
- openapi
- pinecone
- python
- s3
- vectordb

Log in or sign up for Devpost to join the conversation.