🧠 Inspiration The human brain processes sounds, visuals, and emotions in complex, interconnected ways. Inspired by the phenomenon of synesthesia—where people naturally "see" sounds or "hear" colors—we imagined a future where AI could simulate such cross-sensory perception to enhance creativity, accessibility, and interaction.
SynesthAI was born out of our desire to create an immersive, assistive tool that reimagines how humans interact with information—by blending sound, visuals, and emotion using AI.
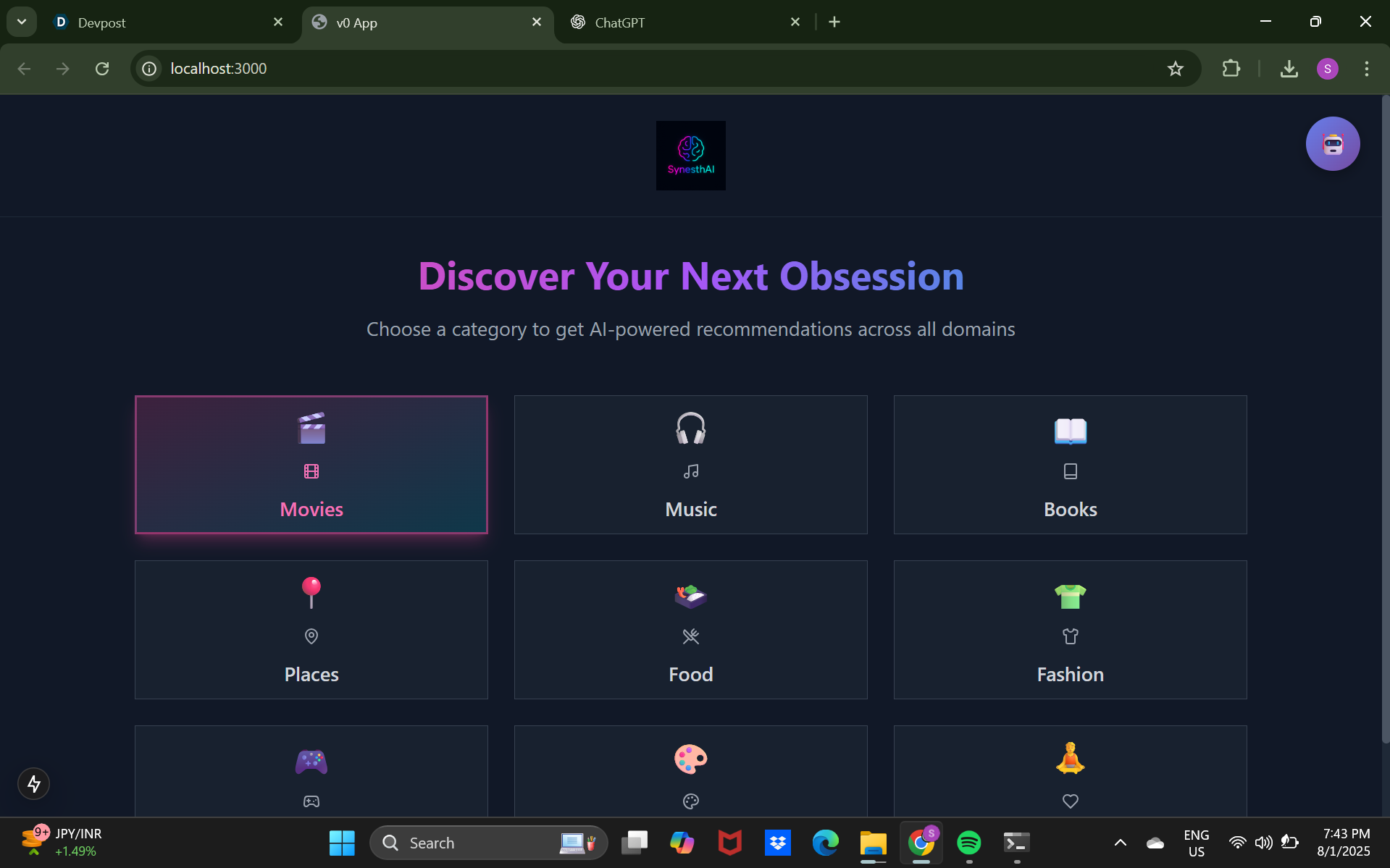
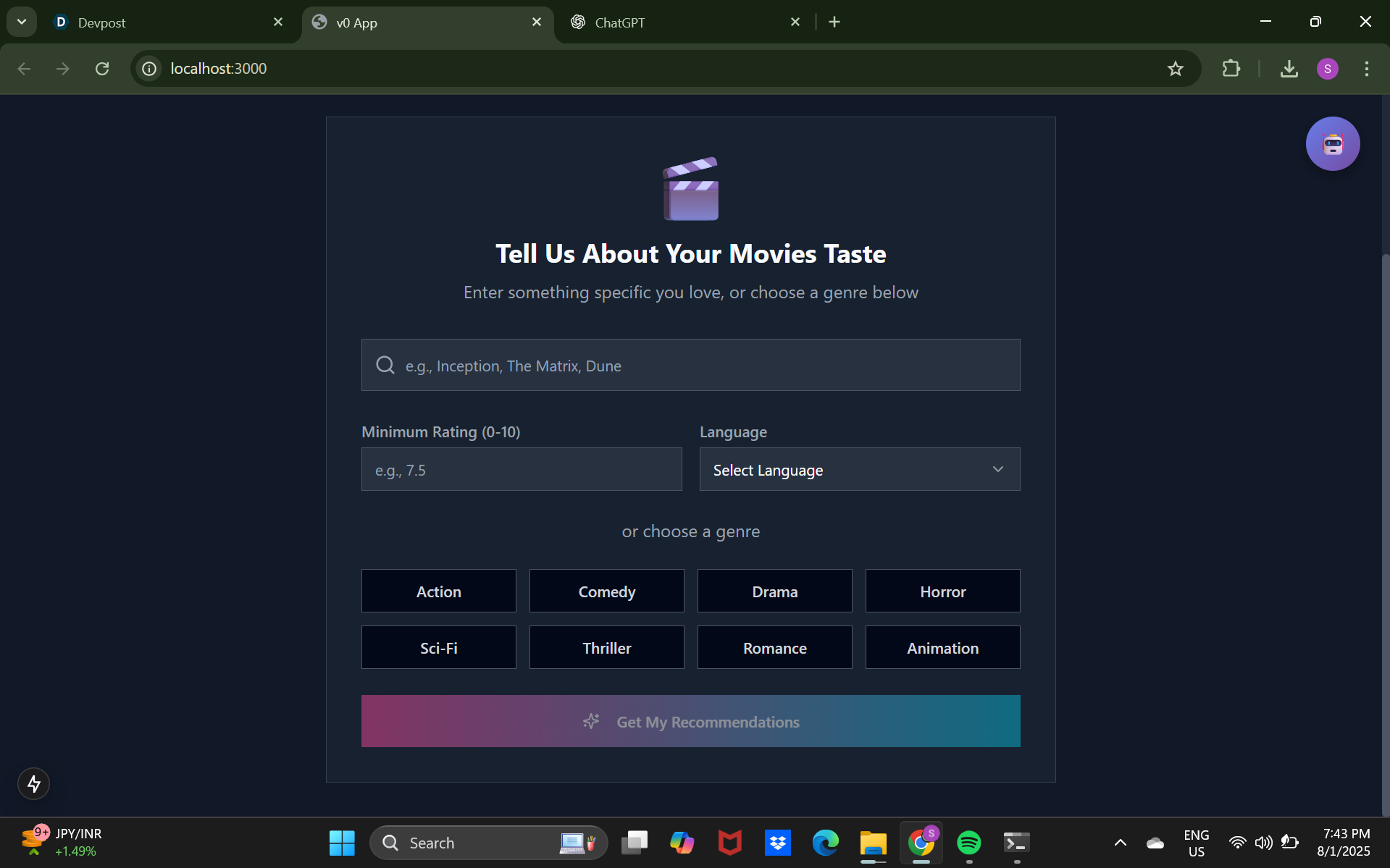
🚀 What it does SynesthAI is a multimodal AI platform that takes an input in one sensory format (e.g., audio, text, or image) and converts it into a creative or assistive output in another. Example features include:
🎨 Converting speech or text into expressive generative art
🎵 Translating images or mood descriptions into background music
🧘 Emotion-aware interfaces for stress detection and ambient response
This can serve artists looking for inspiration, neurodiverse users seeking expressive tools, or anyone interested in AI-powered creativity.
🛠️ How we built it We combined several technologies and APIs to build SynesthAI:
Frontend: Built using React.js for a clean and interactive UI.
Backend: Node.js + Python Flask for processing inputs and connecting models.
AI Models:
Speech-to-text via [Whisper API]
Text-to-image via [Stable Diffusion or DALL·E]
Text-to-music using [Riffusion or MusicGen]
Emotion recognition using transformer-based sentiment models
Cloud Infrastructure: Deployed using Vercel/Render and integrated with Firebase for user sessions.
😅 Challenges we ran into Getting consistent audio-to-visual transformations that felt artistic rather than random.
Integrating multiple AI models with different input/output expectations and formats.
Managing performance latency when dealing with large model inference, especially for real-time feedback.
Fine-tuning emotional accuracy without introducing bias or overfitting on generic datasets.
🌟 Accomplishments that we're proud of Built a fully functional demo in less than 48 hours!
Created genuinely expressive art and music from voice samples.
Seamlessly integrated different modalities (voice, text, image, music) through one intuitive interface.
Got positive feedback from mentors and users who found it both inspiring and accessible.
📚 What we learned Deepened our understanding of multimodal AI models and how they can interact creatively.
Learned how to optimize large ML models for real-time or near-real-time applications.
Understood the UX importance in projects that bridge technology and emotion.
Improved collaboration across frontend, backend, and ML domains within tight deadlines.
🔮 What’s next for SynesthAI Integrate real-time emotion detection from webcam + voice.
Allow users to export their generated music/art as NFTs or downloadable media.
Add community-driven galleries for creative sharing and inspiration.
Train custom models on diverse emotional datasets to reduce bias.
Make it open source for educators, artists, and accessibility developers to build upon.
Built With
- api
- json
- llm
- ollama
- qloo
- typescript




Log in or sign up for Devpost to join the conversation.