-
-
Studio
-
Tunnelling leak
-

Architecture


Inspiration
Designing a sub-2nm transistor means solving coupled quantum–thermal physics — and today that means days-to-weeks of cluster time per layout on classical TCAD tools (Synopsys, Cadence). That latency serializes hardware innovation: every "what if I nudge this gate?" costs a full simulation. We asked a simple question: what if a chip architect could drag a slider and watch the physics update in real time?
What it does
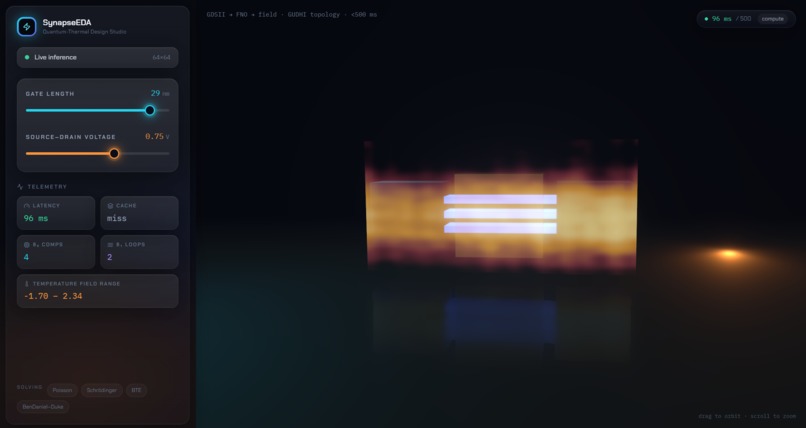
SynapseEDA is a SciML physics coprocessor. It learns the continuous map from device geometry to its physical fields and predicts them in well under 500 ms — turning a batch simulation into an interactive design loop.
- Tune gate length and drain voltage → the predicted electron-density and phonon-temperature fields update live in a 3D WebGL view.
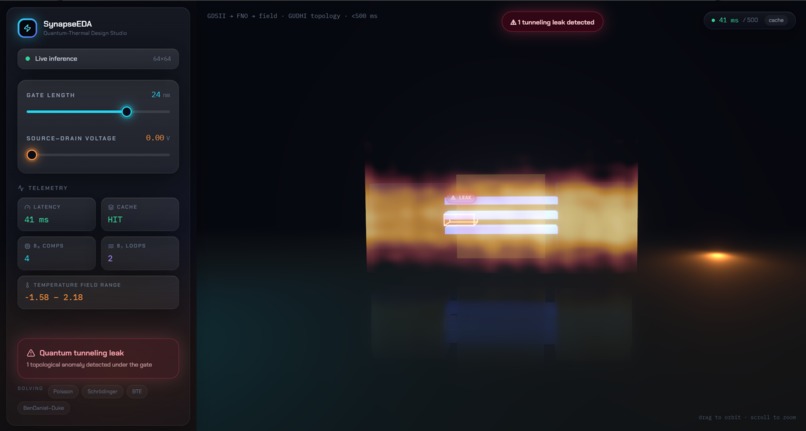
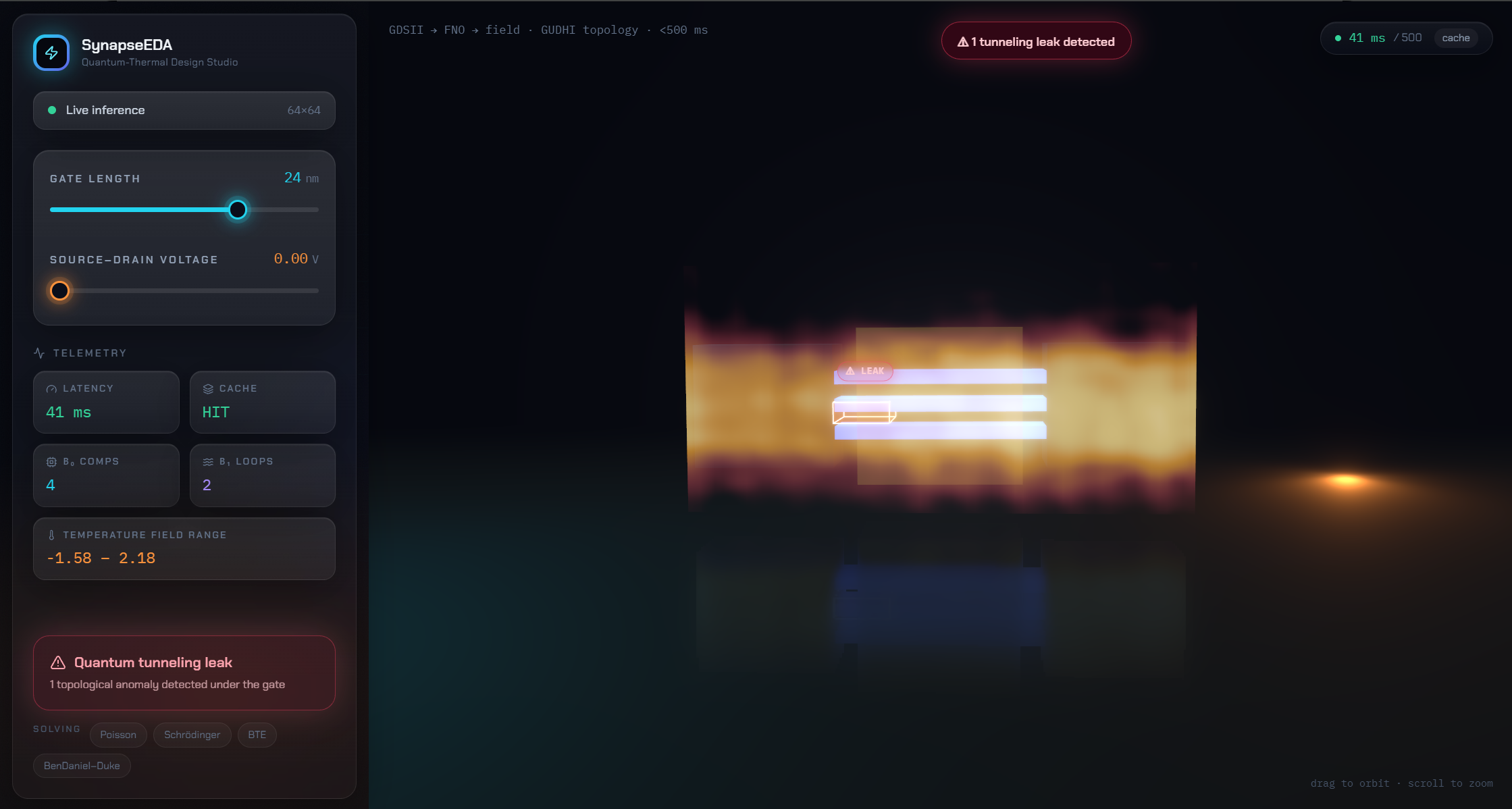
- GUDHI persistent homology scans the predicted density for topological anomalies and surfaces potential quantum-tunneling leakage paths as on-screen alerts.
- Every prediction reports its latency and component-wise physics residuals — no black box.
The Physics it respects
The surrogate is constrained by the governing equations, not just curve-fit. Poisson (electrostatics): $$ \nabla \cdot (\varepsilon \nabla \phi) = -e\,(N_D^{+} - N_A^{-} + p - n) $$ Schrödinger with position-dependent effective mass (BenDaniel–Duke): $$ -\frac{\hbar^2}{2}\,\nabla \cdot \left( \frac{1}{m^{}(\mathbf{r})}\,\nabla \psi \right) + V\psi = E\psi $$ Thermal transport uses a Boltzmann (Guyer–Krumhansl) closure. We enforce the **correct* interface conditions — continuity of the normal displacement \( D_n = \varepsilon E_n \) (not \( \nabla\phi \)) and of \( \tfrac{1}{m^*}\partial_n\psi \) (not \( \partial_n\psi \)) — the exact traps a sharp reviewer probes.
How we built it
- Operator core: a Fourier Neural Operator in JAX + Equinox (lift → spectral-conv blocks → project), trained with Optax AdamW.
- Physics-constrained training: Poisson / Schrödinger / BTE residuals as named loss terms, balanced by gradient-norm adaptive weighting and ramped in by a 3-stage curriculum (electrostatics → thermal → quantum) so the stiff quantum loss never destabilizes early training.
- Active learning: a decoupled Redis queue + CPU worker fleet — the GPU keeps training while workers solve ground truth only for the highest-uncertainty layouts (MC-dropout variance). The accelerator never waits on the slow solver.
- Topology: GUDHI cubical persistent homology over the density field.
- Serving: a FastAPI + WebSocket gateway with Redis caching, loading the trained
.eqxmodel. - Studio: Next.js + React Three Fiber + three.js with real bloom post-processing, a reflective floor, and framer-motion.
Challenges we ran into
- Interface conditions at hard material jumps — naïve \( \partial_n\psi \) continuity is wrong; harmonic averaging of \( \varepsilon \) and \( m^* \) was needed to stop gradient explosions.
- The sub-500 ms contract vs. float64 accuracy and FFT cost.
- Decoupling the GPU from the CPU solver without ever stalling training.
- Bleeding-edge dependency skew (JAX vs. libraries) — solved with a pinned lockfile.
Accomplishments that we're proud of
- A trained neural operator generalizing to unseen layouts at \( \approx 0.28 \) relative-\( L_2 \) error, served live in ~40–50 ms — far inside the 500 ms budget.
- Machine-precision physics: every loss term drives to \( \sim 10^{-15} \) residual on manufactured analytic solutions.
- A fully live, browser-verified demo: drag sliders → the fields and tunneling-leak alerts react in real time.
What we learned
Operator learning is a different beast from regression. The FNO's complex spectral weights forced complex-aware optimization, and "mesh invariance" only holds once you fight spectral aliasing (zero-padding + smooth mode filters). The hardest lessons were in the physics: getting interface flux-matching exactly right and conditioning the loss landscape so coupled PDEs train at all.
What's next for SynapseEDA: Neural Physics Engine for Sub-2nm Chips
The operator is currently trained and validated on a spectral-PDE benchmark (Poisson/heat), with the entire pipeline — ingestion, active learning, physics losses — built to ingest real NanoTCAD ViDES / NEGF labels. Next: real TCAD ground truth, full 3D devices, and Domain-Decomposition operators for sharp heterostructure interfaces.
Built With
- docker
- equinox
- fastapi
- framer-motion
- gudhi
- jax
- next.js
- numpy
- optax
- python
- react
- react-three-fiber
- redis
- tailwindcss
- three.js
- typescript
- uvicorn
- webgl
- websockets
- weight&biases

Log in or sign up for Devpost to join the conversation.