-
-
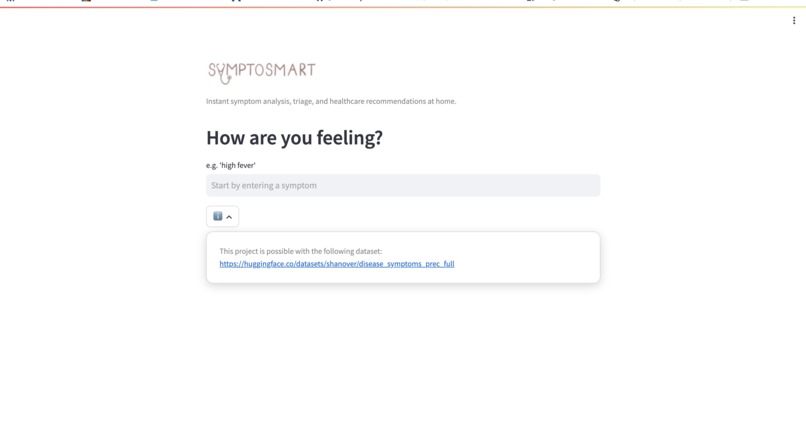
Main page
-
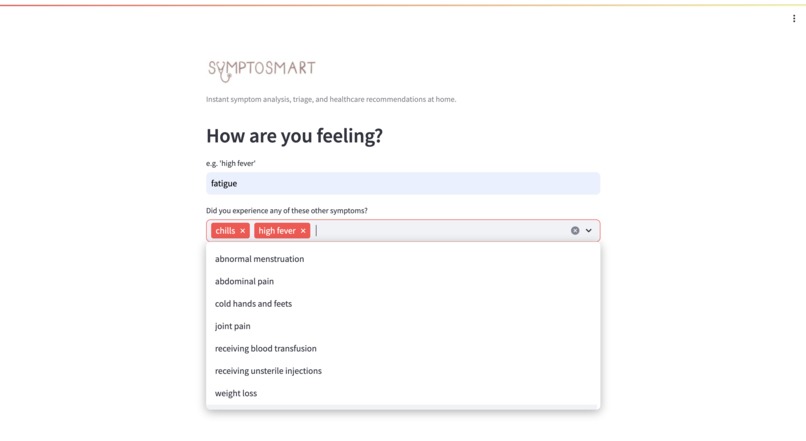
Searching for a symptom outputs a multi-select box of filtered symptoms
-
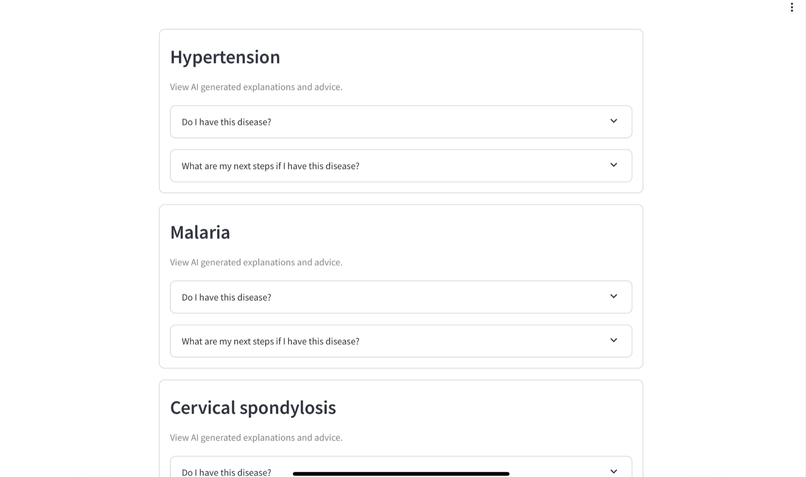
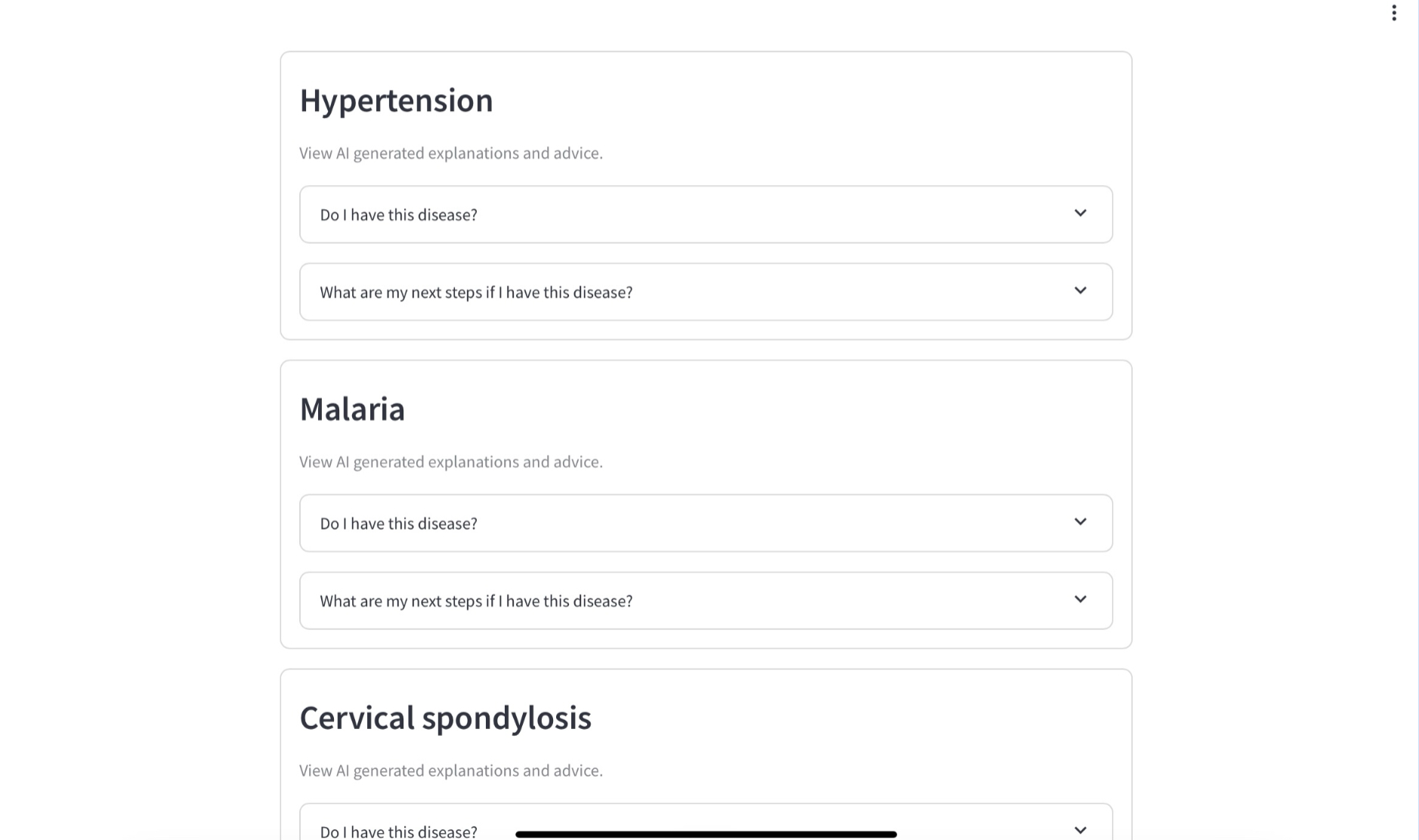
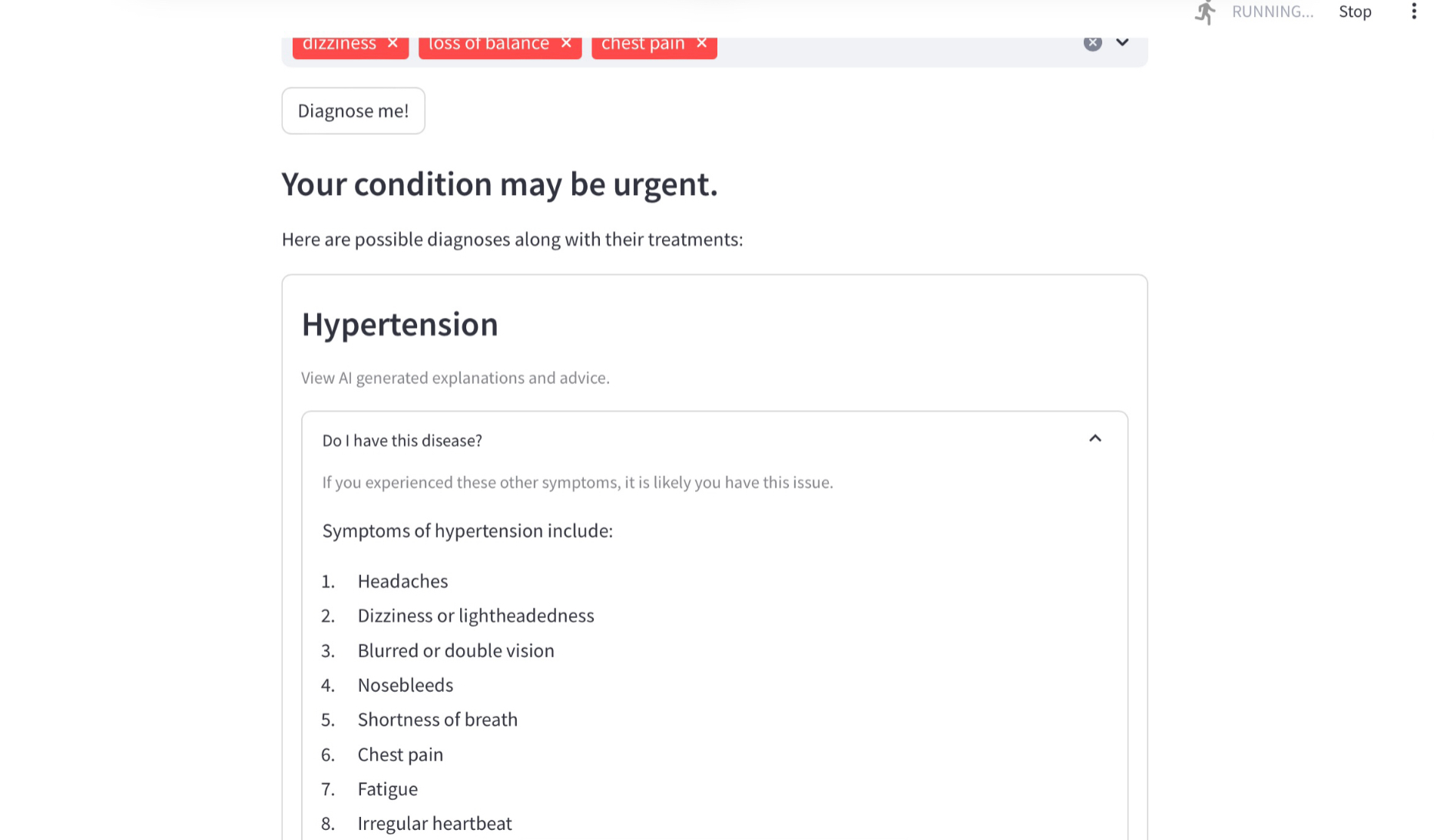
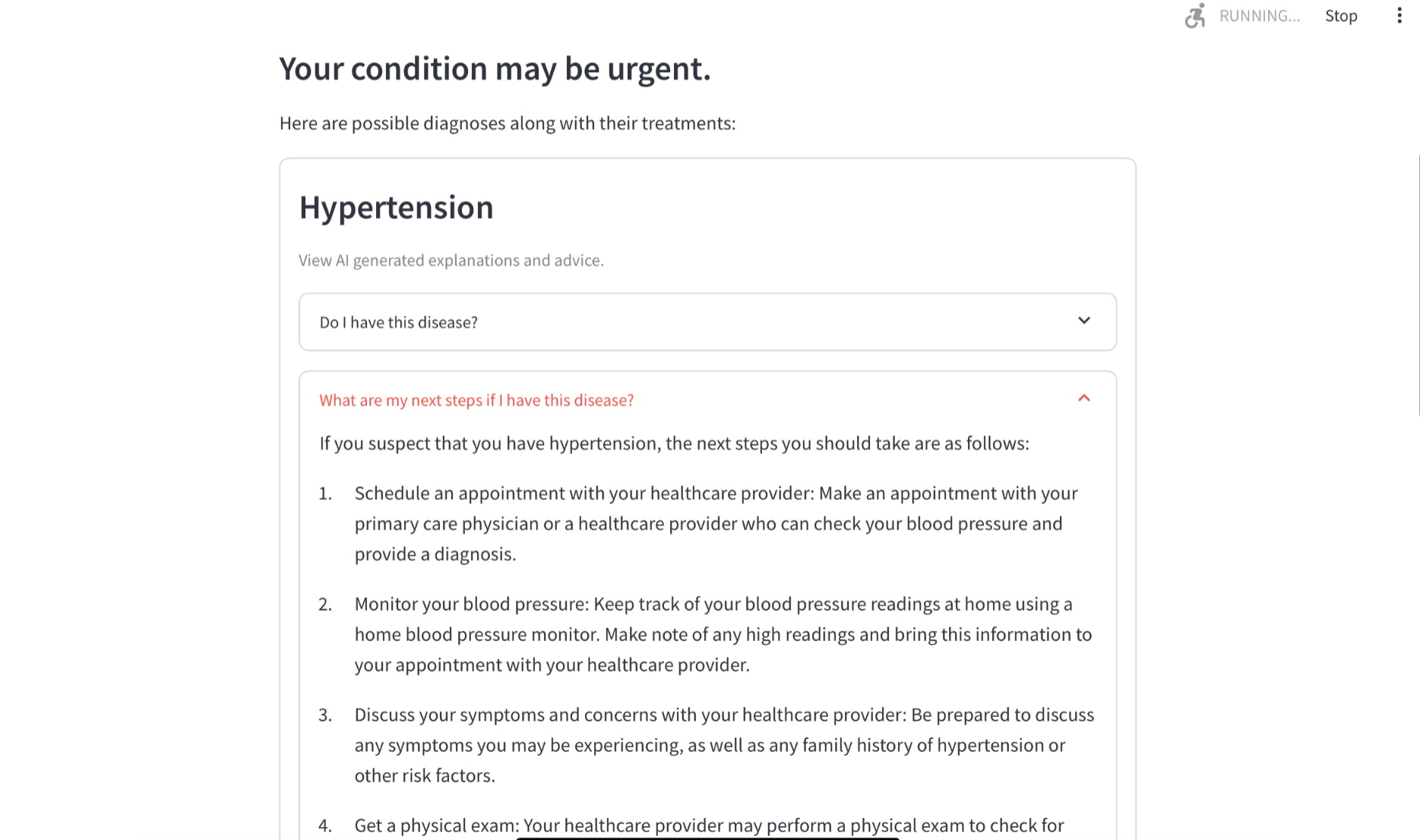
Provides multiple possible diagnoses
-
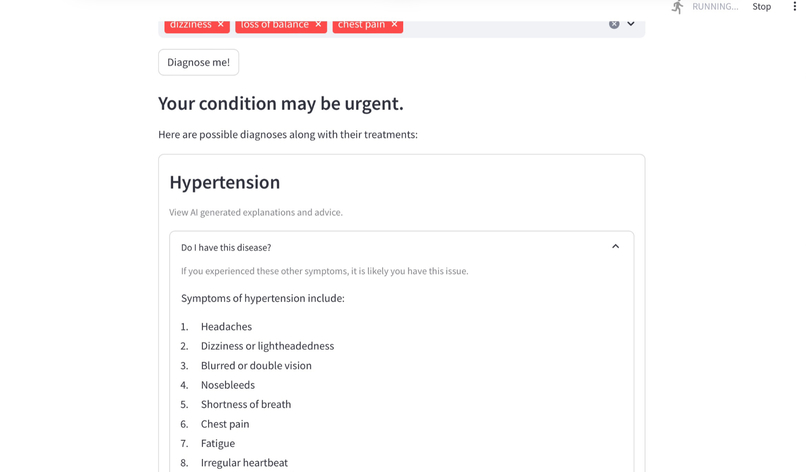
Recieve your triage and diagnosis
-
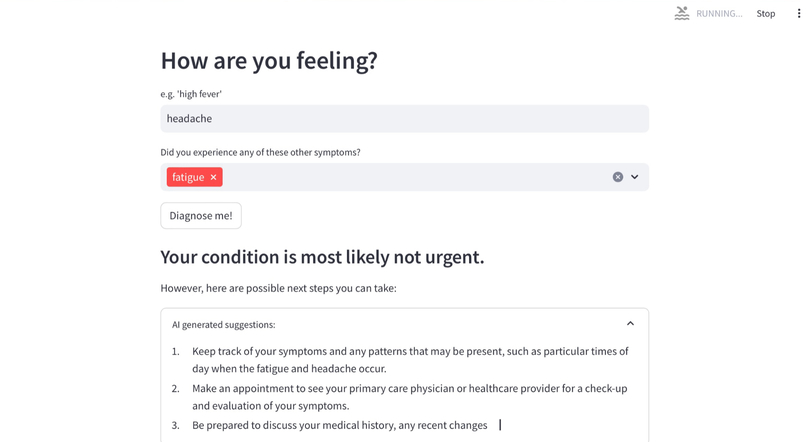
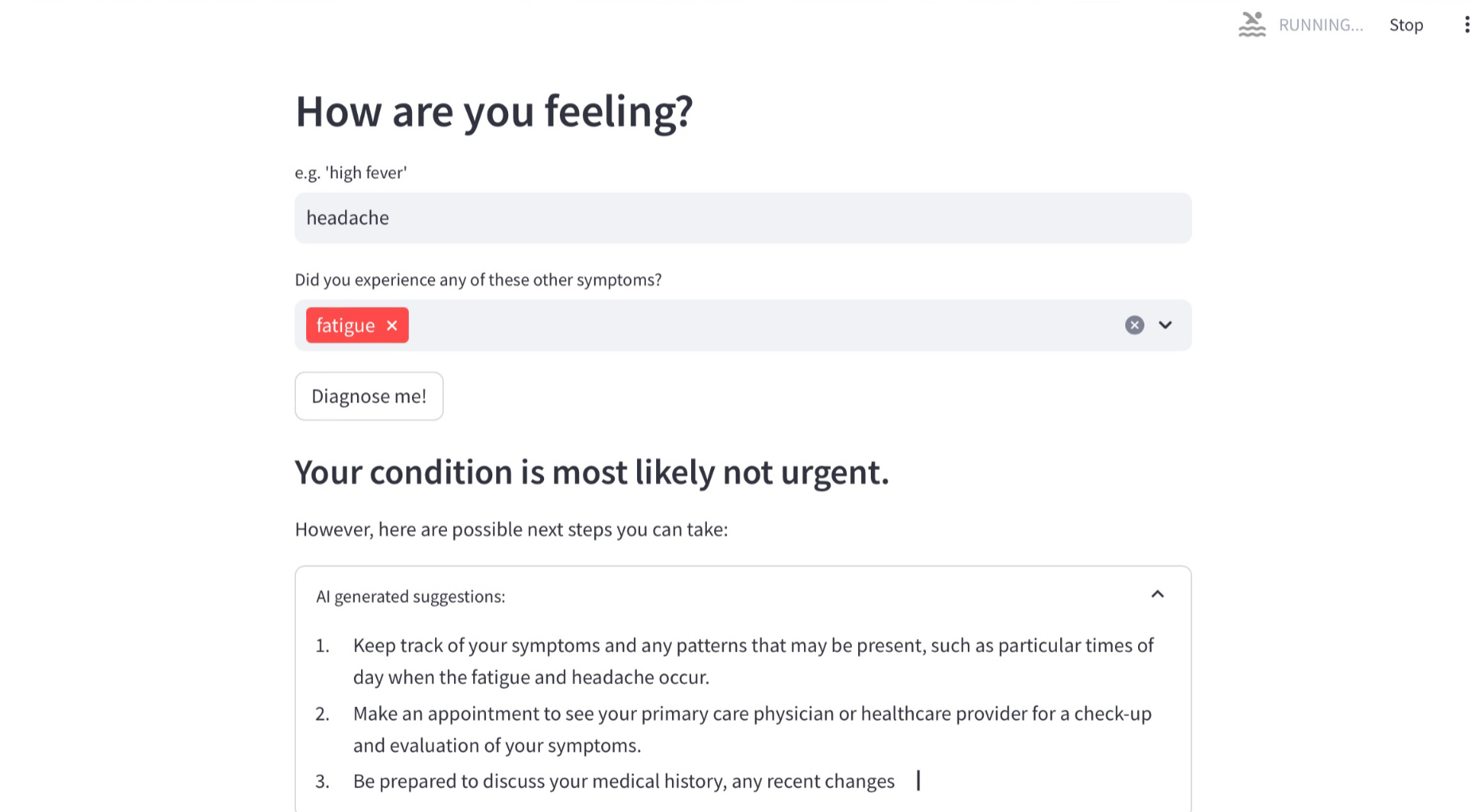
Non-urgent triages also provides AI generated recommendations of what to do next
-
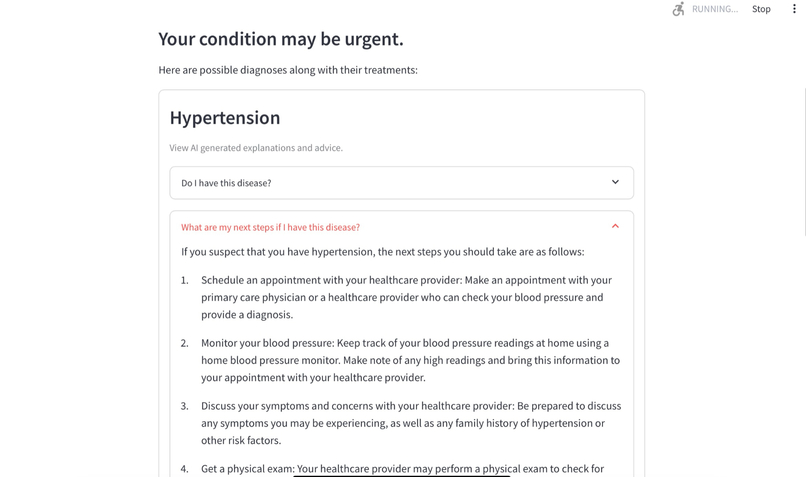
AI-generated next steps
Inspiration
Have you ever experienced a sudden onset of symptoms, like a cough, body ache, or nausea, but you’re unsure if it is serious enough to warrant a trip to the hospital? Even if we google the symptoms, we’d be overwhelmed with the results and whether it is serious enough to go to the hospital for. Simple doctor or hospital visits are a privilege in modern-day American society, especially with the inflated costs of healthcare. In fact, according to CBS News, 38% of Americans have reported to have delayed medical care due to healthcare costs in 2022 alone. Triaging, or a preliminary assessment of the urgency of one’s symptoms, can be enough for one to know if the hospital trip is worth it or not, but is not readily available unless one pays a doctor’s visit.
What it does
With our project SymptoSmart, we have developed a prototype of a clinical software that uses advanced search filtering, dataframes, machine learning technologies (such as vectorization and natural language processing), and artificial intelligence to output a triage (urgency of symptoms), possible diagnoses, and recommendations/next steps for the user to take when provided with user-inputted symptoms. This way, users can get an understanding of their inputted symptoms right from home at absolutely no cost.
How we built it
We used python for backend and imported several python libraries to help create our project. We used streamlit, a powerful library made for data scientists to create web applications with machine learning. In addition, we created and configured two machine learning models that diagnose a patient's urgent symptoms using scikit-learn libraries, particularly RandomForestClassifier, TfidfVectorizer, and TruncatedSVD. We created the models based on this dataset from HuggingFace, where the input is different symptoms and the output is possible diagnoses, and we used pandas and numPy to create the dataframe. We saved the models using pkl files and opened them on our application. We also used OOP to clean up the code by defining a class "Symptosmart" along with member functions. These member functions are the application's features, which includes search filtering (which filters out the dataframe of symptoms to only associated symptoms), triaging (we used AI, particularly the OpenAI API to determine the urgency of provided symptoms), and diagnosing, which we executed using our custom-made machine learning models. In addition we used AI to provide the user with further symptoms & causes so they understand the likelihood of them having this disease, along with AI-generated "next steps" for the user to take if they want to absolve their symptoms.
Challenges we ran into
One challenge we ran into was the search filtering and the overall structure of the dataframe. The symptoms in the given dataset are not listed in individual columns (meaning we cannot apply binary logic to say if the user does or does not have the symptom), but rather listed. In order to compile all the symptoms into a unique, iterable list of symptoms, we tackled the issue by pre-processing the data and researching on existing pandas and numPy functions that can help us. We also used vectorization and truncated svd, a form of NLP to fine-tune the model and have it provide us with diagnoses.
Another challenge we ran into was that the model did not give all the possible diagnoses and excluded some. We solved this issue by creating multiple different variations of the model, (by reconfiguring Random Forest parameters, applying support vector machines, and using GradientBoosting classifiers instead), and chose the best, most accurate models, compiling the predictions from both of them to a unique set of diagnoses.
Lastly, we also had issues with created an ML model that triages the symptoms. Given the sheer lack of datasets and the questionability of the accuracy of them, we decided to use AI to determine the urgency of an issue, which is also safer for the user as well. We did try, however, to use NLP with this dataset to creating a triaging model, however the runtime and accuracy of the model was not ideal for the user.
Accomplishments that we're proud of
We are proud of how we managed to approach all our challenges, the extensive research we did, and the way we managed to make this program run smoothly. In the past, runtime on web applications has always been an issue, but we managed to avoid that issue here and provide good running times. This enhances the usability of the web app.
We are also proud of the accuracy of our diagnoses and triages, something that we did not know was possible before. This way, we managed to combine the healthcare field with computer science, and also made something which, if developed upon, can greatly impact the large majority of underprivileged people who cannot access simple triages/diagnoses.
What we learned
This project motivated us to learn and understand many things; along with learning about new libraries and techniques for machine-learning, we also learned how to create a program with the user in mind. If we want to make an application aimed in the medical field for the general public to use, we needed to keep in track of runtime, the UI/UX of the web application, and the specific texts and formatting we had to use which improve usability.
What's next for SymptoSmart
Phase 1: Initial Development (2-3 months) Develop AI-powered platform SymptoSmart. Implement basic symptom logging and tracking feature. Set up secure user accounts and data storage using SQL.
Phase 2: Triage System Development (4-5 months) Introduce Natural Language Processing (NLP) for symptom description. Develop a triage system for accurate diagnosis and urgency assessment with ML. Expand the symptom list using NLP to allow users to describe health concerns accurately.
Phase 3: Health Data Management (6-7 months) Enable users to store comprehensive health data securely. Implement blood pressure, cholesterol level, and medical history logging. Develop predictive machine learning models for personalized diagnosis and lifestyle recommendations.
Phase 4: FAQ Section Integration (7-9 months) Integrate FAQ section with information on common health issues. Use NLP, Queries, or Database Management System for FAQ structuring and storage. Ensure the FAQ section provides accurate and relevant information for users.
Phase 5: Continuous Improvement and Expansion (Ongoing) Collect user feedback and data to improve accuracy and usability. Expand database of symptoms, diagnoses, and lifestyle recommendations. Enhance AI capabilities for better understanding and assistance.
Built With
- api
- machine-learning
- openai
- pandas
- python
- scikit-learn
- streamlit
- vectorization


Log in or sign up for Devpost to join the conversation.