-
Starting state: paste any paper on the left, then three opinionated AI scholars enter on the right to debate it.
-
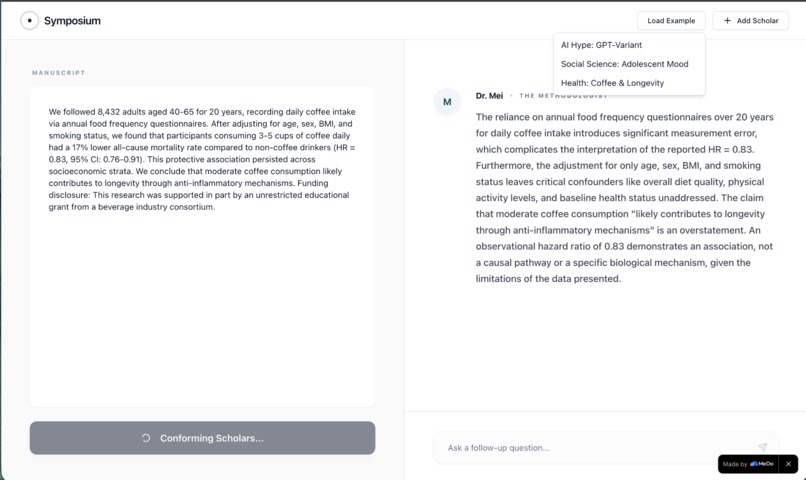
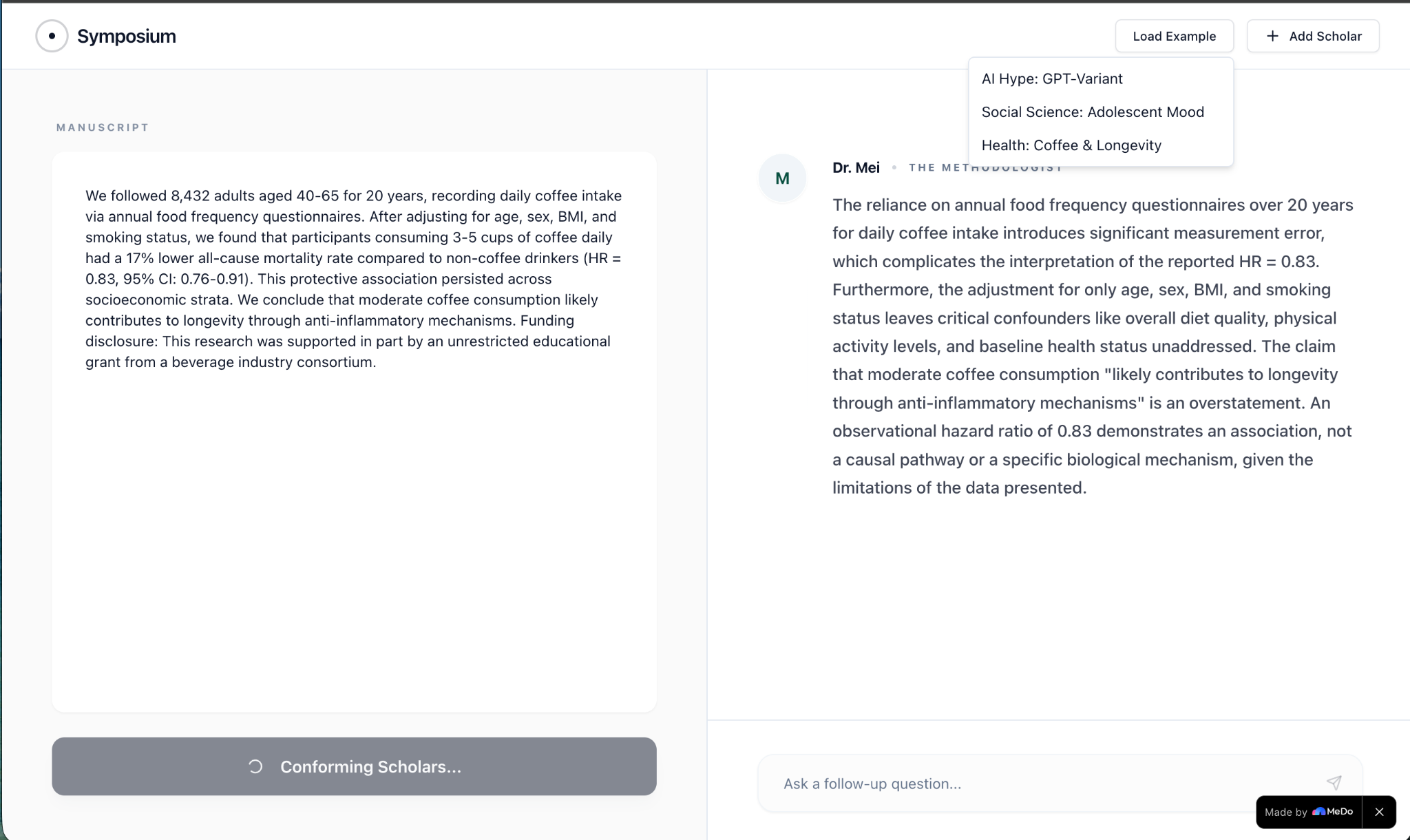
One screen shows examples, Dr. Mei critiquing a coffee study, and scholars entering one at a time.
Inspiration
Every researcher knows the feeling: you read a paper, and a single voice in your head — your own — tries to evaluate it. You catch some flaws. You miss many more. Reading is lonely, and our blind spots are invisible to us.
In academic seminars, the magic isn't any single perspective. It's the collision of perspectives. The methodologist who questions the numbers. The philosopher who questions the framing. The cynical reviewer who has seen this trick before.
Symposium recreates that collision — for any paper, any time, with three opinionated AI scholars who actually disagree with each other.
What it does
Paste any academic paper, article, or even a Reddit post that sounds scientific. Click “Convene the debate”. Three scholars arrive in sequence:
- Dr. Mei, the methodologist: sharp on sample sizes, confounders, and the gap between correlation and causation
- Prof. Aris, the philosopher of science: questions the framing, the unstated assumptions, the definitions everyone takes for granted
- Reviewer 2, the anonymous peer reviewer: sees the overclaiming, the cherry-picked citations, the limitations sections that limit nothing
Then click "Continue the debate" and watch them respond to each other. Dr. Mei pushes back on Reviewer 2's tone. Prof. Aris reframes Dr. Mei's empiricism. Reviewer 2 weaponizes Aris's philosophical questions back at the original authors.
How I built it with MeDo
The entire application was built through a structured conversation with MeDo without coding. The interesting part was how the build naturally split into four conversational stages:
Stage 1: Structure. I described the two-panel layout in natural language. MeDo returned a requirements document I could review before any code was generated. This pre-build confirmation cycle was crucial — I caught a layout ambiguity (text area height) before it became a bug.
Stage 2 : Characters.I introduced the three scholars with their colors, avatars, and roles, but with placeholder messages. This let me verify the visual identity before committing to AI integration.
Stage 3 : Soul.I provided detailed system prompts for each scholar, not just "be a methodologist" but full character specifications including their PERSONALITY, FOCUS, HOW YOU SPEAK, and YOU NEVER sections. Critically, each scholar's prompt also references the others (e.g., "You think Reviewer 2 is too generous"). This is what makes their voices distinct and their disagreement believable.
Stage 4: Collision. The "Continue the debate" feature was the hardest part. I had MeDo wire up a second LLM call per scholar that includes the original manuscript AND the other scholars' Round 1 responses. To make the cross-fire feel structured, I hardcoded a debate triangle:
- Dr. Mei responds to Reviewer 2
- Prof. Aris responds to Dr. Mei
- Reviewer 2 responds to Prof. Aris
Each Round 2 response is forced to begin with @[ScholarName]: so the UI can render the addressing tag deterministically. The instruction also explicitly prefers disagreement over agreement.
The most impressive feature MeDo helped me create
The Round 2 cross-fire. When tested on a paper claiming "coffee likely contributes to longevity through anti-inflammatory mechanisms," the scholars produced this exchange:
Dr. Mei: The issue is not merely a "leap in logic" but a fundamental mismatch between the observational study design and the definitive causal claims presented.
@Dr. Mei — Prof. Aris: Your point about moving from correlation to causation is indeed critical, but perhaps the deeper question is what assumptions underpin our conceptualization of "coffee intake" itself as a singular causal agent, rather than an entangled practice within a broader set of lifestyle choices.
@Prof. Aris — Reviewer 2: Your thoughtful questions are precisely what these authors should have grappled with, rather than casually asserting causation. They haven't merely struggled with complexity; they've simply manufactured a mechanistic conclusion out of thin air. It's less about the difficulty of bridging the gap, and more about the audacity of claiming a bridge exists where none has been built.
Three scholars. Three escalating reframings of the same critique. Each in a distinct voice. This kind of layered, recursive intellectual debate is something a single LLM call simply cannot produce — and MeDo's multi-turn orchestration made it possible without writing any backend code.
Challenges I ran into
Getting scholars to actually disagree. My first version had three scholars who all critiqued the paper but never each other. They were three parallel monologues, not a debate. I solved this by structuring Round 2 with assigned targets (the debate triangle) and an explicit instruction that "disagreement is more interesting than agreement."
Avoiding markdown contamination. LLMs love outputting bold and bullet points. In a chat-style scholarly debate, this would shatter the conversational feel. I had to explicitly instruct the model to produce flowing prose only.
Maintaining distinct voices across rounds.Without careful prompt design, Round 2 made all three scholars sound similar (because they were all "responding to each other"). Keeping the system prompts strict and adding voice-specific phrases preserved their identities.
Accomplishments I'm proud of
- Built a working multi-agent debate system in under two days with zero traditional coding
- The scholars produce genuinely quotable lines — Reviewer 2's "audacity of claiming a bridge exists where none has been built" reads like real peer review
- The product reveals a real gap in current AI reading tools: they summarize, but they don't disagree
What I learned
- Multi-agent prompts beat single-agent prompts for nuanced critique. A single AI trying to "give multiple perspectives" produces hedged, balanced text. Three AIs each committed to their own view produce sharper, more useful analysis.
- MeDo's requirement-confirmation cycle is underrated. Most no-code platforms generate code immediately; MeDo's pause-and-confirm step saved at least three rounds of debugging.
- Character is built through what you refuse to do. The "YOU NEVER" sections of each scholar's prompt did more work than the positive descriptions.
What's next for Symposium
- Custom scholar packs: design your own three-scholar panels (a literary analysis pack with a New Critic, a Marxist, and a postmodernist; a startup pitch pack with a VC, a customer, and a competitor)
- Round 3 and beyond: open-ended debate where scholars can call on each other interactively
- Selection-triggered discussion — highlight a sentence in the manuscript, summon a focused debate on just that passage 4.Save & share debates: export a complete scholarly debate as a markdown document for citation in future work
Built With
- baidu-ernie
- llm
- medo
- multi-agent
- no-code
- prompt-engineering

Log in or sign up for Devpost to join the conversation.