
I outperformed Opus 4.6 on Terminal Bench 2.0!
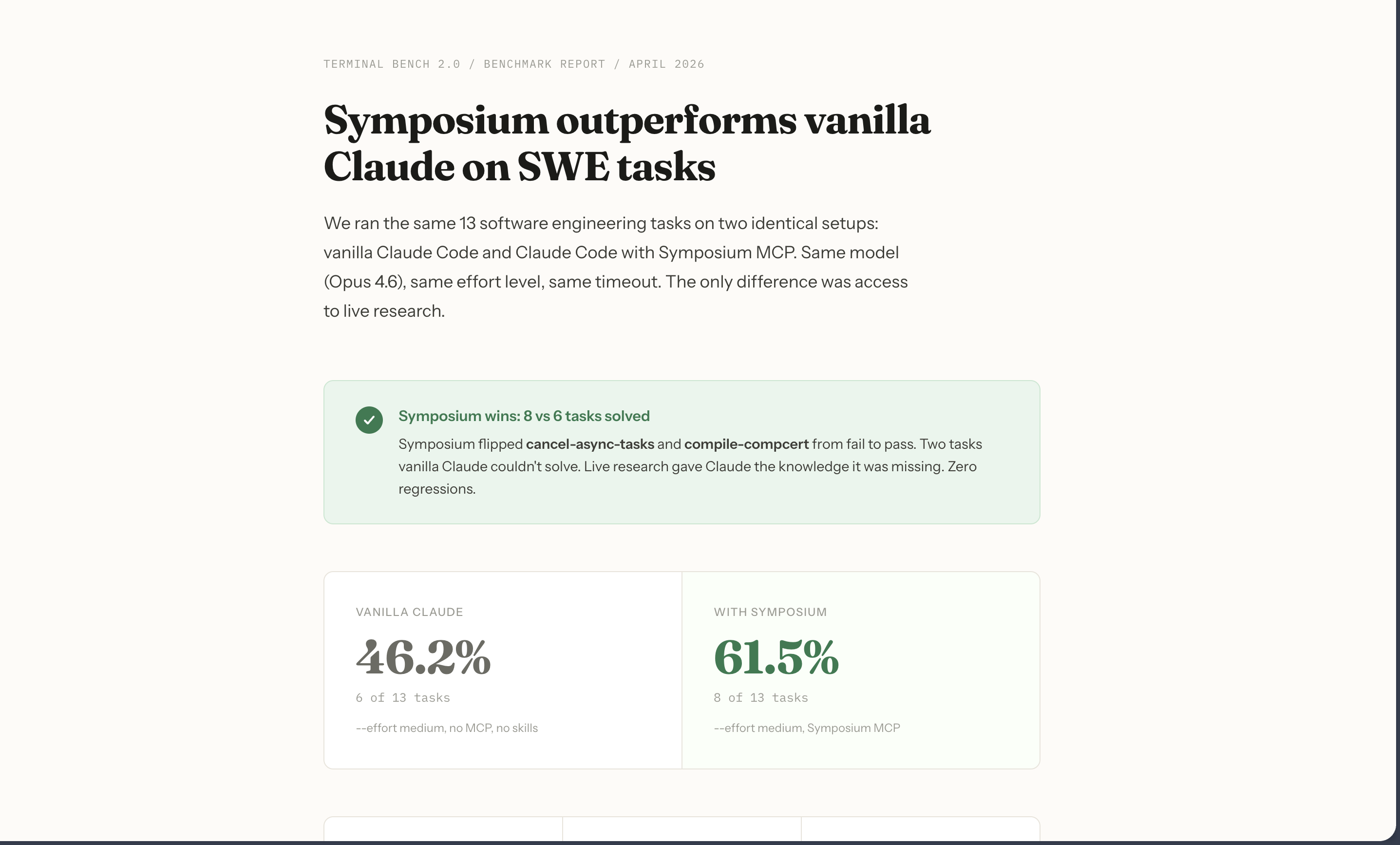
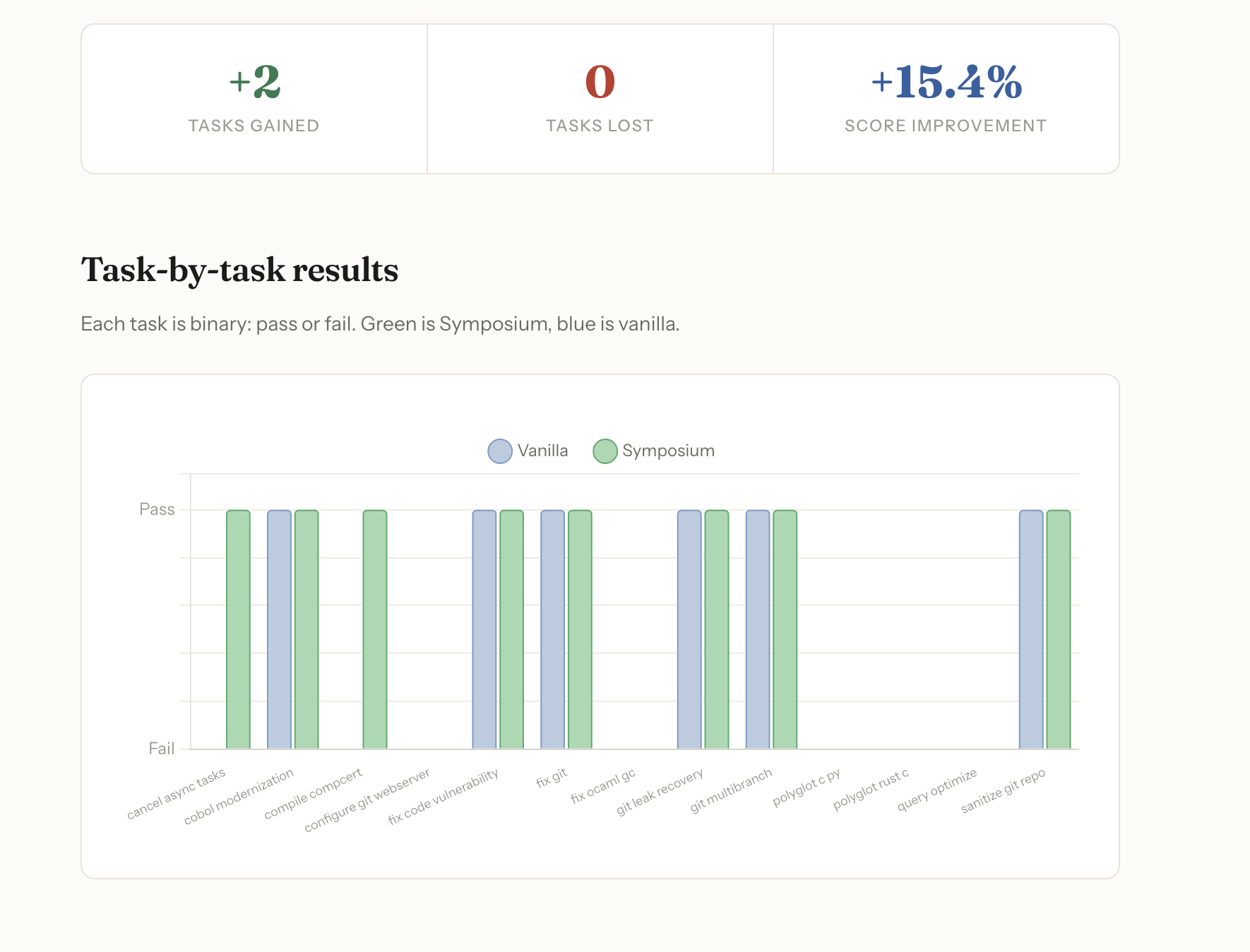
46.2% → 69.2% (6/13 → 9/13) | +3 tasks | 0 regressions | +23.1% Ran on 13 SWE tasks from Terminal Bench 2.0
This was ran on the 13 hardest SWE questions from terminal 2.0 benchmark (Lack of time and compute to run the entire benchmark)
NOTE: The benchmark was not completed during recording the video
Inspiration
In World War II, the Allies studied returning bombers to figure out where to add armor. They looked at bullet holes on surviving planes and said "reinforce those spots." A statistician named Abraham Wald pointed out the problem. You're only seeing the planes that made it back. The ones hit in other places never returned. Armor the spots with no holes.
Same thing with LLMs.
Models are great at the stuff in their training data. Add Stripe. Read docs. Update an API. Easy. But some tasks, they just fail. Hallucinate a function. Use a deprecated API. Confidently write broken code. They don't know what they don't know.
Symposium finds those gaps.
What it does
Symposium is an MCP server for Claude Code. When the model can't get something right, Symposium steps in.
The key: I don't spawn 10 agents to hallucinate the same wrong answer. If the main model got it wrong, copying that approach is pointless. Instead, the problem gets split into different angles. One agent reads official docs. Another searches real GitHub repos. One checks failure modes. One studies the codebase. One plans tests. All different directions.
Findings get collected, evidence scored from real signals, cross-validated where doc agents and code agents agree, and synthesized into a final answer.
Then every novel discovery gets stored. Next time anyone hits the same issue, instant recall. No agents needed.
And every correction gets exported as training data. DPO-format pairs: what the model got wrong vs the verified answer. The stuff models fail at today becomes the data that fixes them tomorrow.
How I built it
TypeScript on Bun. MCP protocol over stdio.
8 core modules: recall.ts checks prior knowledge. decomposer.ts picks research angles. spawner.ts dispatches parallel agents with retry and dual-mode. collector.ts scores evidence. synthesizer.ts merges findings into a plan. learner.ts stores discoveries after a quality gate. feedback.ts adjusts confidence from user feedback. handlers.ts formats the output.
Nia SDK powers the research. Oracle agents for deep analysis, Tracer agents for GitHub search, Context API for the learning loop, Advisor for verification against indexed docs.
Evidence scoring is real math. Agent convergence 1x, tracer evidence 2x (real repos don't lie), pattern consistency 1x, cross-validation bonus when Oracle and Tracer agree. Not vibes. Numbers.
Oracle streams via SSE first, falls back to polling. Early completion starts synthesis when N-1 agents finish. 9 test files run without an API key. One-line install.
Challenges I ran into
Making agents actually research differently, not just echo the same hallucination in different wrappers. Dual-mode (api_correctness runs both doc search and code search) with cross-validation was the solution.
LLM JSON output parsing. safeParseJSON handles trailing commas, comments, multi-block extraction, balanced brace matching. 15+ test cases just for that.
The learning quality gate. Too loose, you store garbage. Too strict, you never learn. I ended up with vagueness heuristics plus duplicate detection via semantic search before every save.
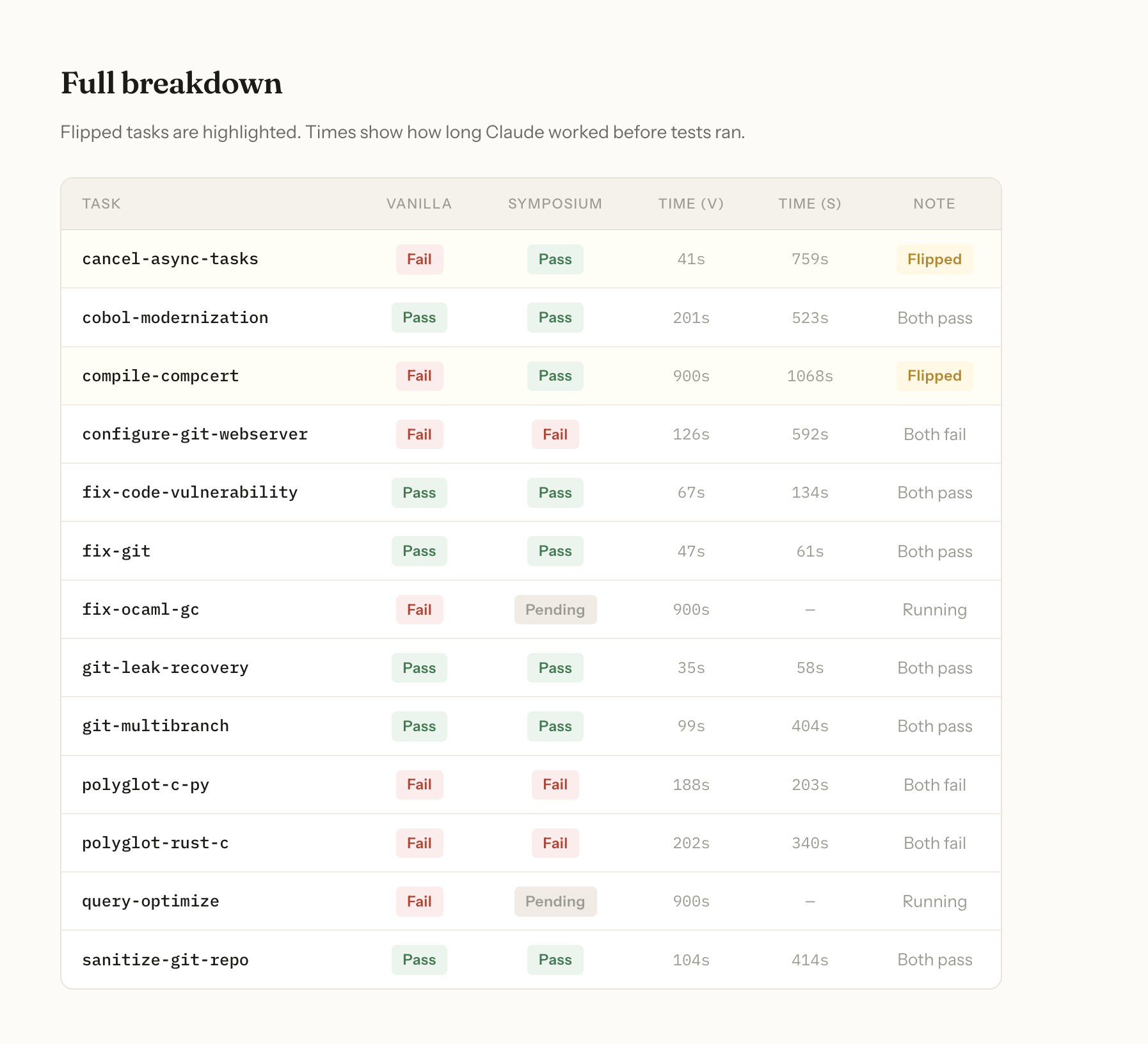
The benchmark. I finished building Symposium way earlier than expected, so I spent the rest of the time on Terminal Bench 2.0. Started with all 80 questions. That killed hours. Each run spawns a full Claude Code session inside Docker, waits for it to finish, runs the verifier. 80 of those back to back takes forever. Eventually I scoped it down to the 13 hardest SWE tasks and ran those head-to-head. That's where the 46.2% → 61.5% result came from.
Accomplishments I'm proud of
Fast path works. Seen this problem before? One call instead of five. Gets faster the more you use it.
Training data export is real. symposium_export gives DPO-format pairs ready for fine-tuning. What the model got wrong (rejected) and the verified answer (chosen), with sources.
Evidence scores from actual signals. Three GitHub repos using the same pattern? Tracer evidence = 1.0. Not a model guessing confidence.
What I learned
Survivorship bias isn't just a metaphor here. It's the engineering approach. You can't improve models by feeding them what they already know. You have to find the crashes, the wrong answers, and turn those into training signal.
Multi-agent only works if agents are actually different. Same model, same prompt, different wrapper? Useless. Different data source, different research angle? That works.
The learning loop changes everything. First run: 5+ agents, 30-60 seconds. Second time? Instant.
What's next
Making it faster. Smarter caching, fewer redundant agent calls, tighter early completion so synthesis kicks in sooner.
And maintaining it as open source. Symposium is MIT licensed. I want people using it, breaking it, contributing dimensions, improving the evidence scoring. The more users run it, the more knowledge gets discovered, the better the training data gets. That loop only works if it's open.
Built With
- mcp
- nia
- nia-advisor
- nia-context-api
- nia-oracle
- nia-sdk
- nia-tracer
- sse
- typescript



Log in or sign up for Devpost to join the conversation.