-
UI
-

Personas
-
Summary

Sympli: Not a second doctor. A first advocate. Anthropic x UMD Hackathon 2026 — Health & Wellbeing Track
Inspiration Most people leave a doctor's appointment more confused than when they walked in. Lab results arrive with no explanation. Radiology reports are written in language nobody outside a hospital understands. And most patients, especially students, uninsured individuals, and first-generation healthcare navigators, have nobody to call. We kept coming back to one specific moment: you receive a report, you see a number flagged in red, and you have no idea whether to panic or ignore it. That moment of alone-ness in the face of medical information felt like exactly the kind of problem AI could solve, responsibly, without overstepping into diagnosis territory. The track problem statement said it best: medical knowledge is locked behind jargon and paywalls, and most people navigate it alone. Sympli is our answer to that.
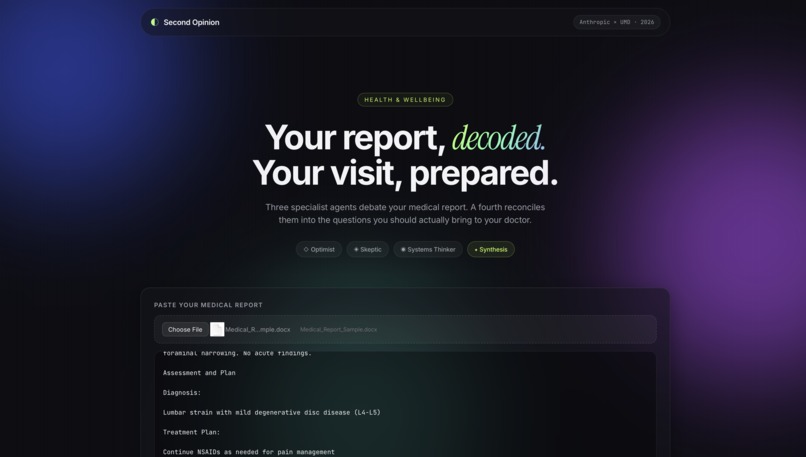
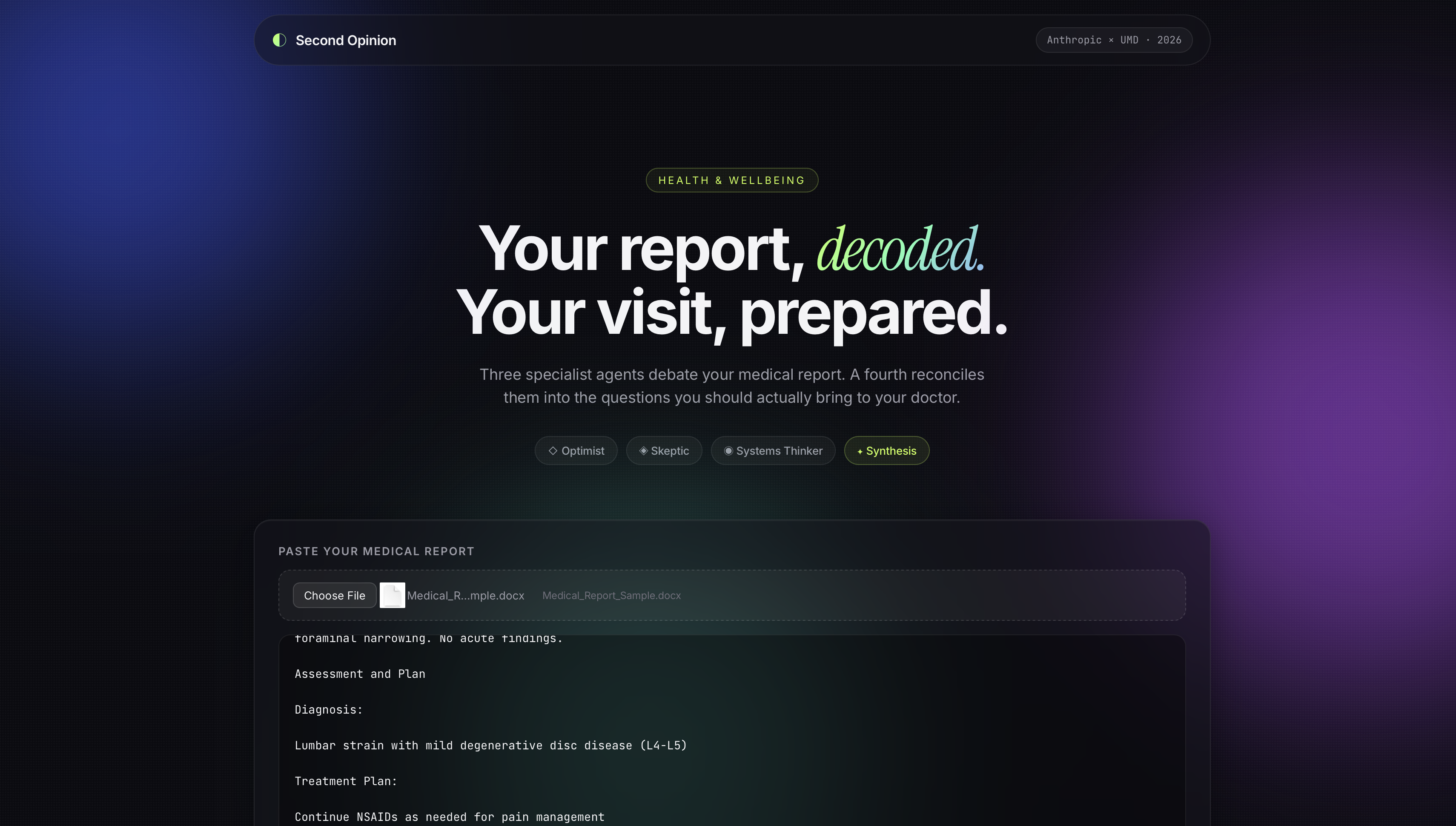
What it does Sympli is a patient preparation tool. Upload any medical report, lab panel, blood work, or radiology summary, and three AI specialists analyze it simultaneously from different angles. AgentRoleThe OptimistFinds what is normal, stable, and reassuringThe SkepticFlags values and language that deserve follow-upThe Systems ThinkerConnects findings to each other and the bigger pictureThe SynthesizerReconciles all three into one actionable brief A fourth synthesis agent reconciles their debate into:
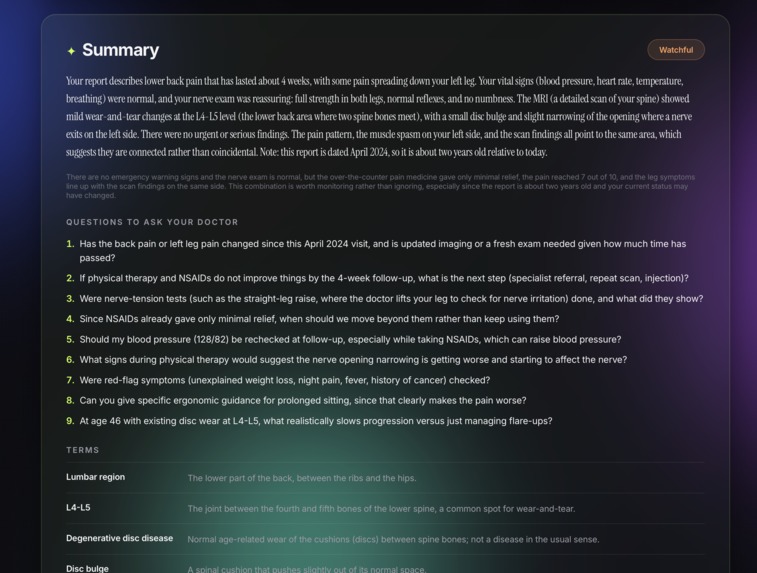
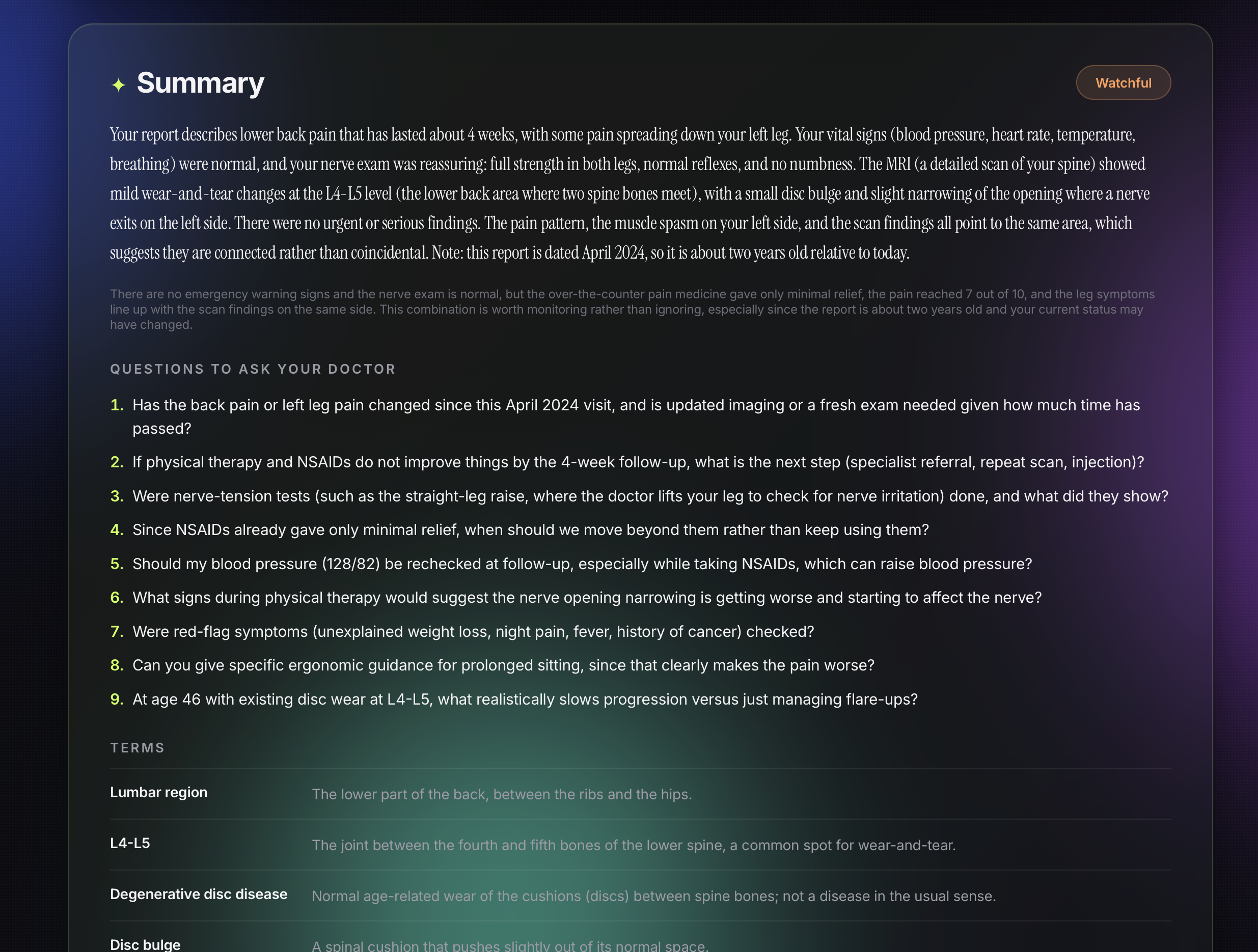
A plain-English summary with no jargon A triage signal: Reassuring, Watchful, or See Doctor Soon A ranked list of questions to bring to the appointment Nearby clinic suggestions tuned to urgency level
It does not diagnose. It does not replace your doctor. It makes sure you walk in knowing exactly what to ask.
How we built it The frontend is built with React 18 and Vite, styled with plain CSS and no external UI libraries. The backend is a thin Express server that orchestrates four parallel agent calls via the Claude Code CLI. Each agent is a structured prompt returning strict JSON, constrained to its analytical lens. The pipeline: Upload → Extract Text → [ Optimist | Skeptic | Systems Thinker ] → Synthesizer → Render The three specialist agents run in parallel via Promise.all(), minimizing total latency. File handling supports:
PDF via pdfjs-dist, parsed client-side DOCX via mammoth, parsed client-side TXT read directly in the browser
Challenges we ran into Getting three agents to return consistently structured JSON without bleeding into each other's assigned perspective was harder than expected. Each prompt went through multiple iterations to prevent the Optimist from flagging concerns or the Skeptic from offering false reassurance. Parsing diverse medical report formats, dense lab tables, unstructured clinical notes, and scanned PDFs, required careful text extraction logic. Balancing genuine usefulness with responsible safety framing was a constant design tension throughout the build.
Accomplishments that we're proud of The multi-agent architecture genuinely catches different things across different lenses. In testing, the Skeptic flagged a borderline creatinine value that the Optimist correctly contextualised, while the Systems Thinker connected it to an elevated WBC that neither had foregrounded independently. That felt like real clinical reasoning. We are also proud of the safety framing. Every output is conservative by design, consistently redirects to professional consultation, and never speculates on diagnosis. Formally, if each agent ( A_i ) has a probability ( p_i ) of catching a clinically relevant flag, the probability that at least one agent catches it across ( n = 3 ) independent agents is: P(at least one catch)=1−∏i=1n(1−pi)P(\text{at least one catch}) = 1 - \prod_{i=1}^{n}(1 - p_i)P(at least one catch)=1−i=1∏n(1−pi) For ( p_i = 0.7 ) across three agents: P=1−(0.3)3=1−0.027=0.973P = 1 - (0.3)^3 = 1 - 0.027 = 0.973P=1−(0.3)3=1−0.027=0.973 Three imperfect reviewers together are far more reliable than one perfect-seeming one.
What we learned Prompt engineering for structured, role-constrained output is a discipline in itself. Small changes in system prompt wording produce dramatically different agent behavior. The most valuable part of the tool is not the AI analysis itself but the synthesis layer that reconciles disagreement between perspectives. That reconciliation is where the real insight lives.
What's next for Sympli
Longitudinal tracking — compare this month's results against last month's to surface trends invisible in a single report Voice input — describe symptoms and cross-reference them against uploaded results Caregiver mode — for adult children managing an elderly parent's health Clinic edition — tuned for underserved settings where patients have limited health literacy and limited time with their doctor
Disclaimer Sympli is a preparation tool only. It does not provide medical diagnoses, treatment recommendations, or replace professional medical advice. Always discuss your results with a qualified healthcare provider. In an emergency, call 911.

Log in or sign up for Devpost to join the conversation.