-
-
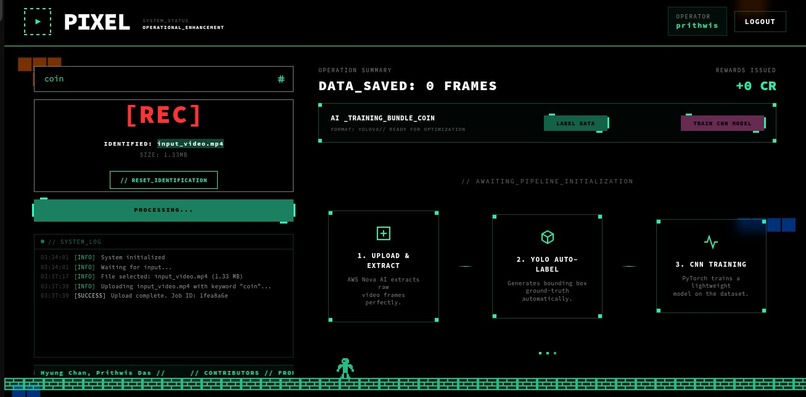
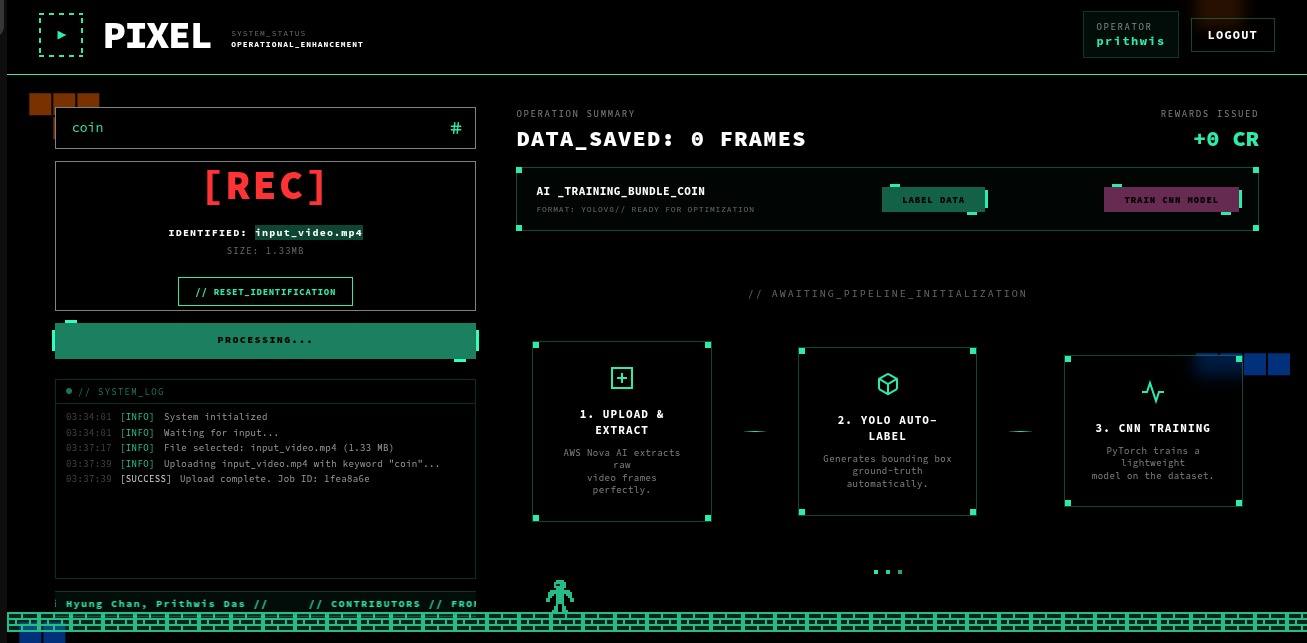
Authentication, Video Upload and Preprocessing
-
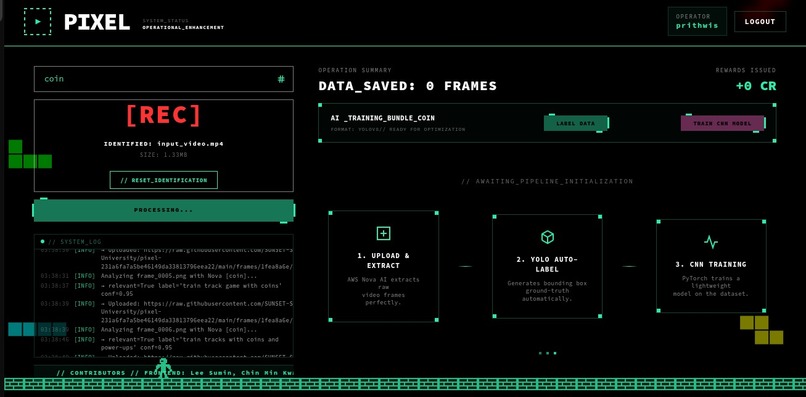
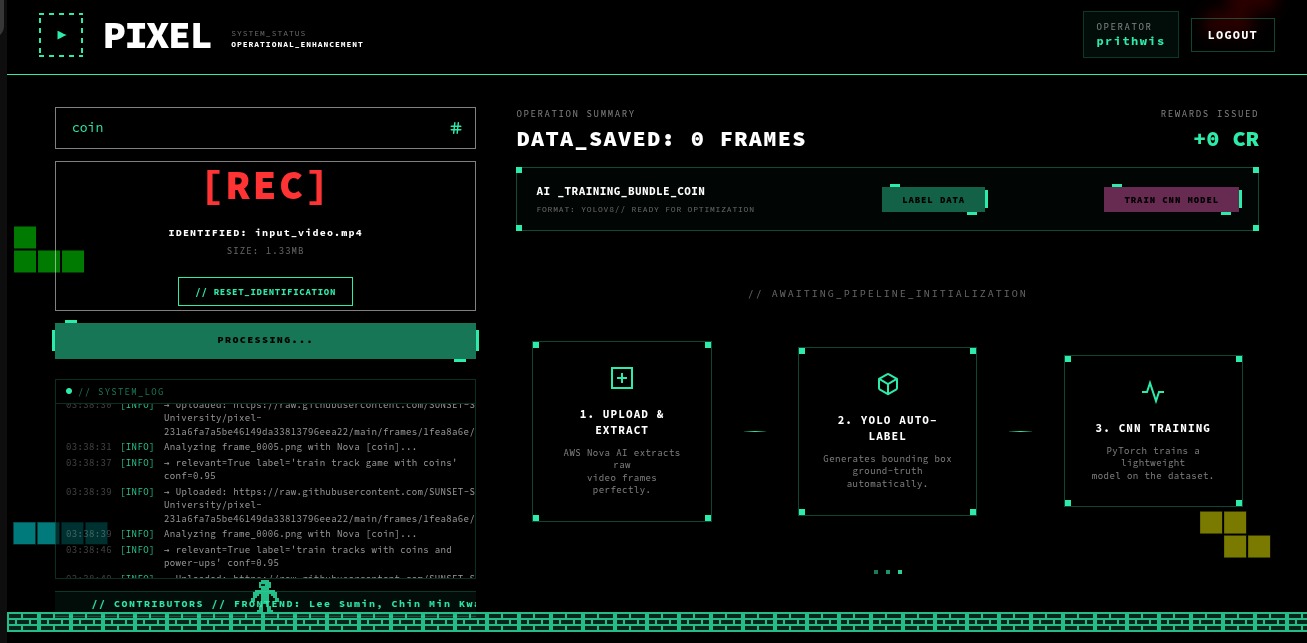
Processing and Evaluation of each frame by Nova 2 Lite
-
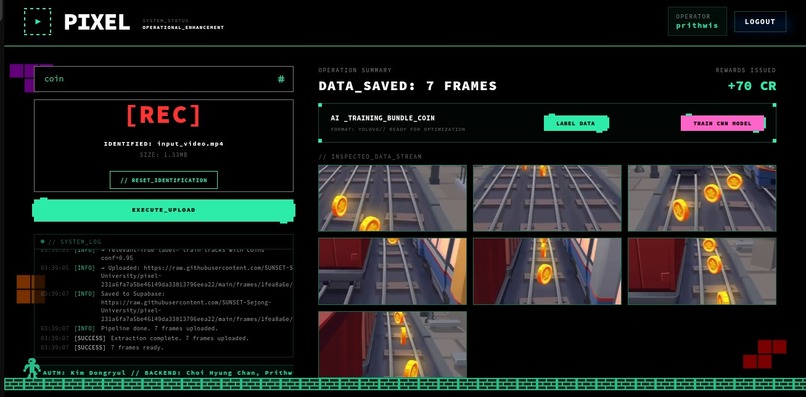
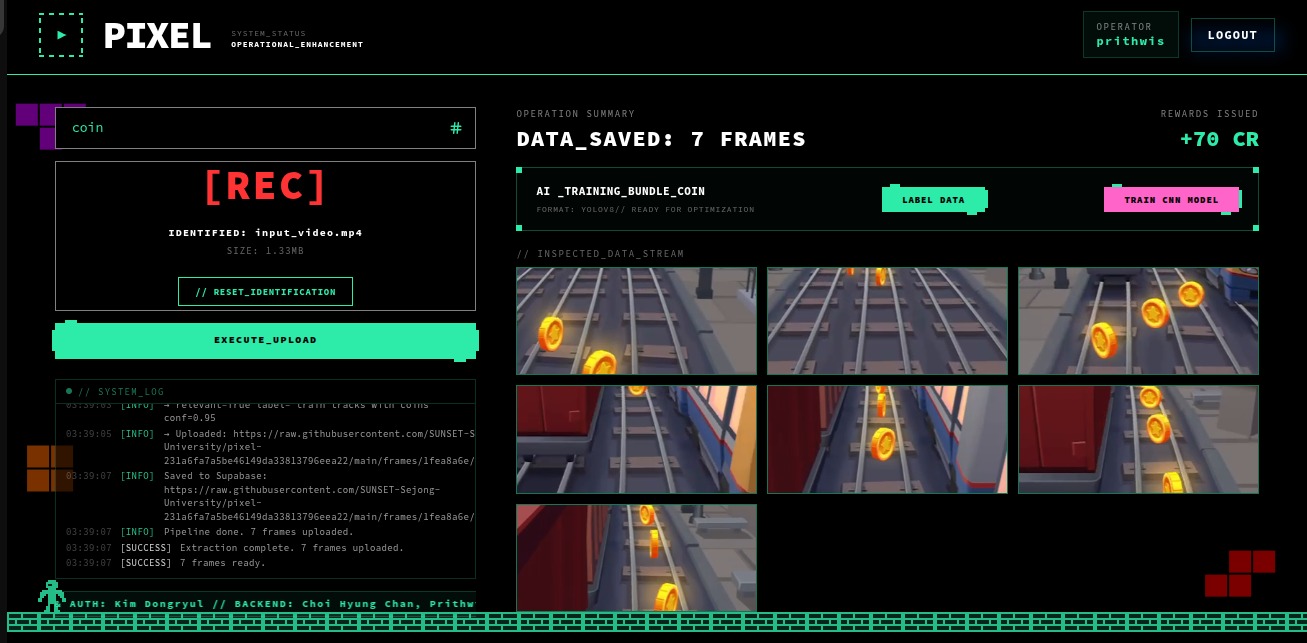
Selection of the most significant frames based on Nova's Relevance Score
-
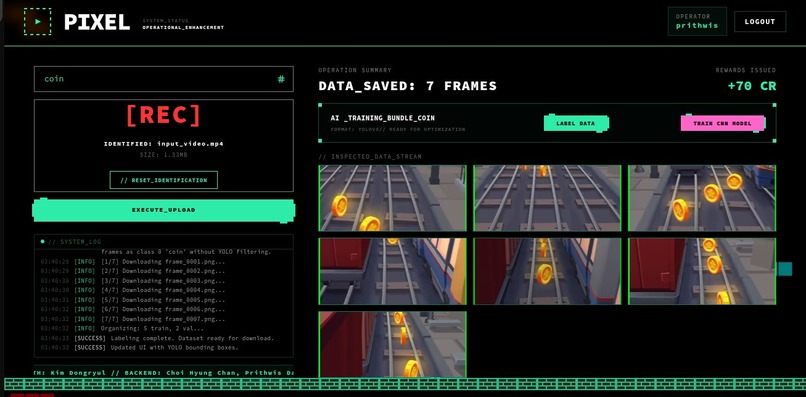
Transforming selected frames into labeled dataset using YOLOv8
-
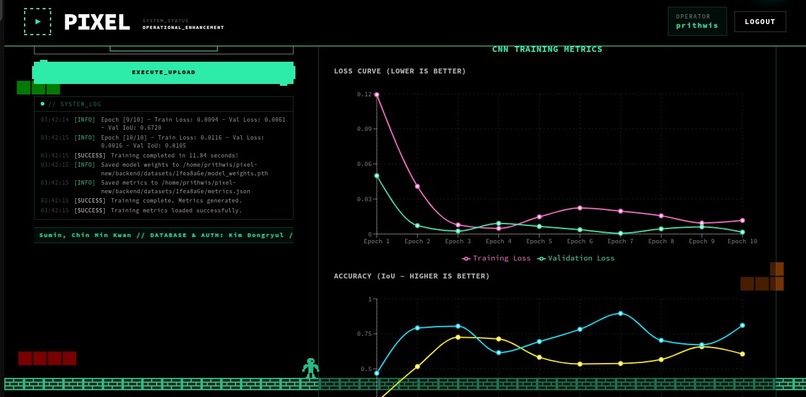
Performance Evaluation based on training of a custom lightweight PyTorch BBoxRegressor CNN
Inspiration
The inspiration for PIXEL came from a glaring bottleneck in the AI world: the data scarcity problem. While LLMs have become incredibly accessible, specialized object detection models still require immense amounts of manually labeled data.
We noticed that while labeled datasets for niche concepts (like a "red jacket" or specific objects in a game) are rare, video footage is everywhere. From movies and music videos to millions of hours of gaming footage, the information is there—it's just "locked" in an unstructured video format. We built PIXEL to bridge this model knowledge gap by unlocking the potential of video as an automated training source.
What it does
PIXEL is an end-to-end, automated AI pipeline that converts raw video into a fully labeled, training-ready machine learning dataset:
- Ingestion & Distillation: Extracts frames at a controlled FPS and uses SSIM deduplication to remove redundant data.
- AI-Powered Curation: Integrates Amazon Nova AI (Nova-2-Lite) to intelligently filter frames. Instead of simple extraction, Nova ensures every training image is actually relevant to the user's specific keyword.
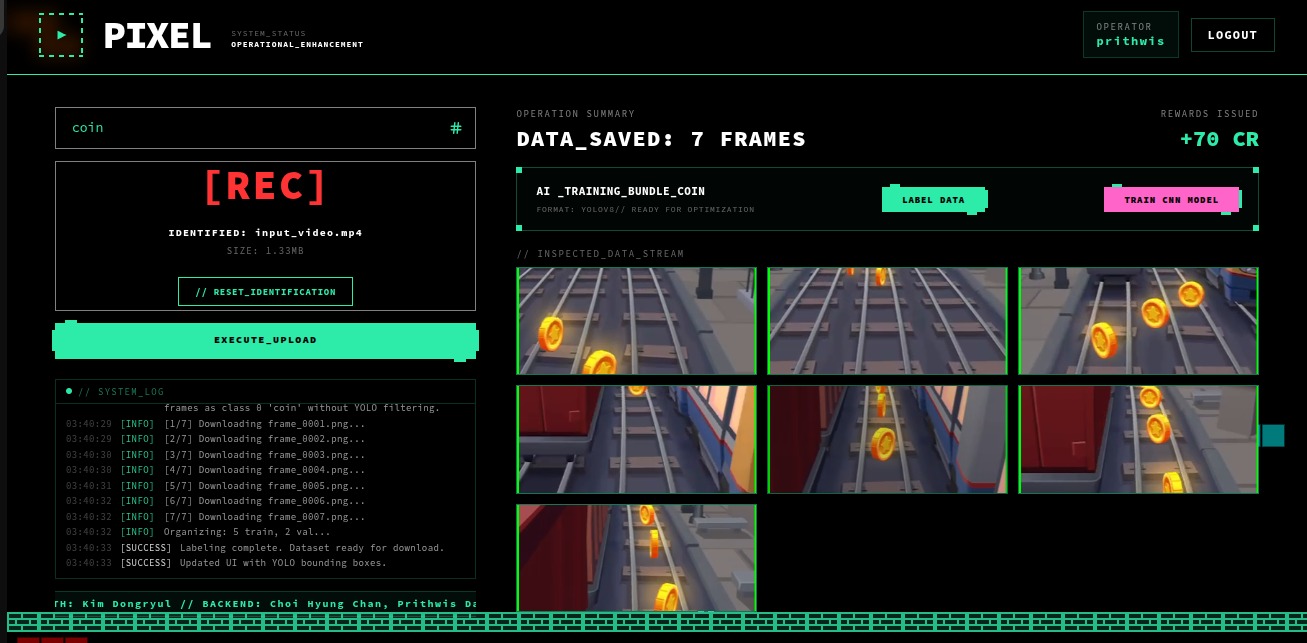
- Automated Labeling: Runs YOLOv8 on the curated frames to generate ground-truth bounding boxes and YOLO-format label files automatically.
- Cloud-to-Local Bridge: Uploads curated frames to a per-user GitHub CDN for persistence and records metadata in Supabase.
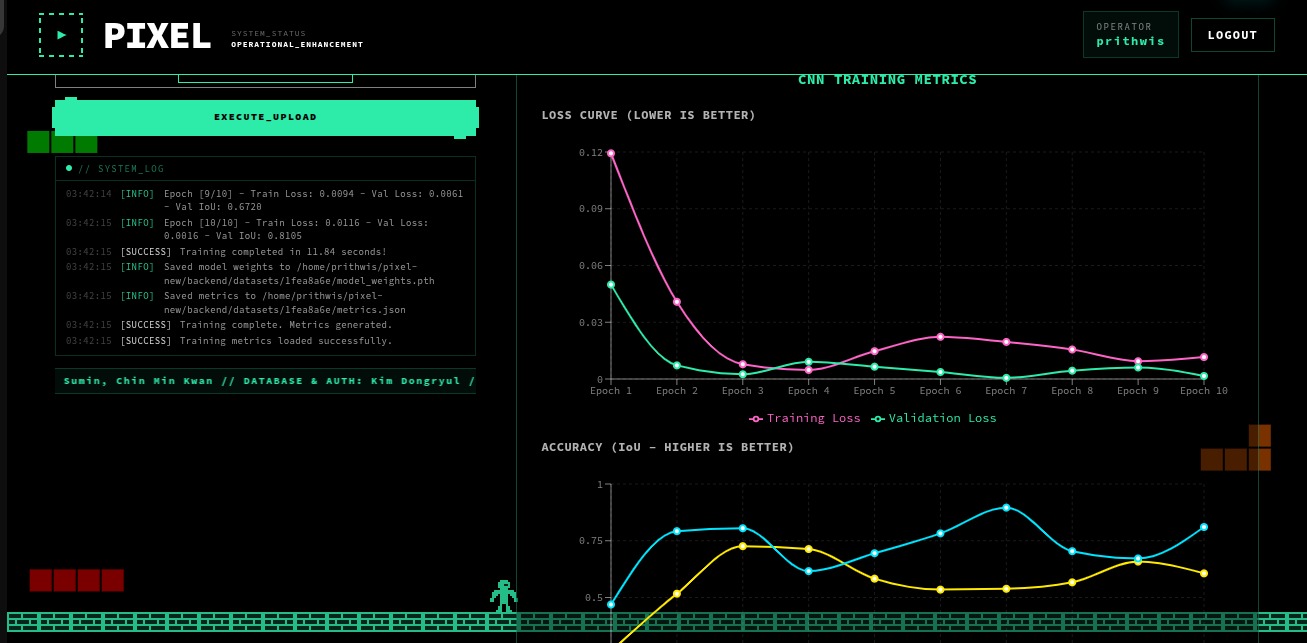
- Built-in Training: Triggers a custom PyTorch CNN (BBoxRegressor) to train directly on the newly created dataset, providing immediate feedback via real-time loss and IoU accuracy charts.
- Export: Delivers a production-ready .zip dataset and trained weights.
How we built it
- AI Engine: Amazon Nova AI (Nova-2-Lite) via AWS Bedrock for multimodal frame analysis; YOLOv8 for zero-shot auto-labeling.
- Backend: FastAPI (Python 3.11) with a robust background task orchestration system and Server-Sent Events (SSE) for real-time log streaming.
- Machine Learning: PyTorch for the custom lightweight CNN regressor; OpenCV and scikit-image (SSIM) for frame processing.
- Frontend: React 19 with Vite, TypeScript, and Tailwind CSS v4. Data visualization for training metrics is handled by Recharts.
- Infrastructure: Supabase for relational metadata and GitHub API for scalable, automated CDN repository provisioning.
Challenges we ran into
- Prompt Engineering for Vision: Fine-tuning the prompt for Amazon Nova to ensure it returned consistently formatted JSON filters for diverse video scenes (from pixel-art games to high-fidelity movies) without hallucinating labels.
- State Orchestration: Managing the complex, multi-stage pipeline (extraction → filtering → labeling → training) asynchronously while keeping the frontend perfectly in sync via SSE streams.
- CDN Automation: Programmatically handling the creation and management of GitHub repositories per user to host thousands of frame images as accessible CDN endpoints.
Accomplishments that we're proud of
- The "Smart" Filter: Successfully using Nova AI to act as a "human-in-the-loop" filter, which dramatically increased the quality of the resulting datasets compared to blind extraction.
- Seamless Full-Stack UX: Taking a user from a raw .mp4 file to a ready-to-use dataset and a trained model in minutes, with zero technical manual intervention required.
- Live Monitoring: Our real-time terminal log viewer and dynamic charts effectively demystify the complex ML training process for the user.
What we learned
- Multimodal Utility: We learned how powerful multimodal models like Amazon Nova are for data distillation tasks—filtering the noise out of big data so smaller models can learn faster.
- The Power of SSE: Real-time communication via Server-Sent Events is significantly lighter and easier to implement than WebSockets for linear, log-heavy pipelines like ML training.
- Edge Case Diversity: Testing on different video sources taught us a lot about how visual concepts vary between digital (gaming) and physical (film) environments.
What's next for PIXEL
- Beyond Bounding Boxes: Extending the pipeline to support Instance Segmentation and Keypoint Detection using Nova's more advanced reasoning capabilities.
- Collaborative Labeling: Adding a "Human-Correct" loop where users can quickly edit Nova/YOLO labels in the browser before final training.
- SageMaker Integration: Allowing users to trigger a full-scale YOLOv8 fine-tune on AWS SageMaker directly from the PIXEL dashboard for production-grade models.
- Edge Deployment: One-click export to TensorRT or CoreML for deploying the trained concepts directly to mobile or IoT devices.
Long term, we see PIXEL as a platform that helps users go from raw visual data to a deployable, task-specific vision model with far less manual effort.
Built With
- amazon-bedrock-(nova-2-lite)
- fastapi
- ffmpeg
- jwt-authentication
- opencv
- postgresql-(supabase)
- python
- react
- sqlalchemy
- typescript
- vite
- yolov8






Log in or sign up for Devpost to join the conversation.