
Inspiration
Unfortunately, many people and communities across the globe have poor access to medical care, especially in remote communities/villages in contents like Africa, South-America and South-East Asia. One of the most prevalent types of infections in these communities are caused by parasites. In fact, the prevalence of infection across multiple different parasite is estimated to affect more than 2 billion people while there is an estimated 4.5 billion at risk of infection. (These stats take into account the possibility of contracting multiple parasitic infections) Currently, the diagnosis process for these diseases in these remote communities only really occurs when health care volunteers travel to these communities and run tests on sight. These samples are then sent to the nearest hospital where they can be review and diagnosed. Due to this gap in diagnosis time and poor organization, the treatment of these diseases becomes extremely difficult, even though we mostly have medications to help fight most of these infections.
What it does
Our program aims to directly aid this gap in diagnosis time. Essentially, instead of the samples getting sent to the closest hospital (which in some cases can be 100s of kilometers away), was propose that a technician can upload images either fecal or blood smears taken under a microscope. Our application will then classify the type of infection based on a pre-trained ResNet deep-learning model. Doctors at the hospital can view these upload images and the classification by the program can aid doctors in confirming the diagnosis. Further more, the confirmed data can be further used to improve and train the deep-learning model.
How we built it
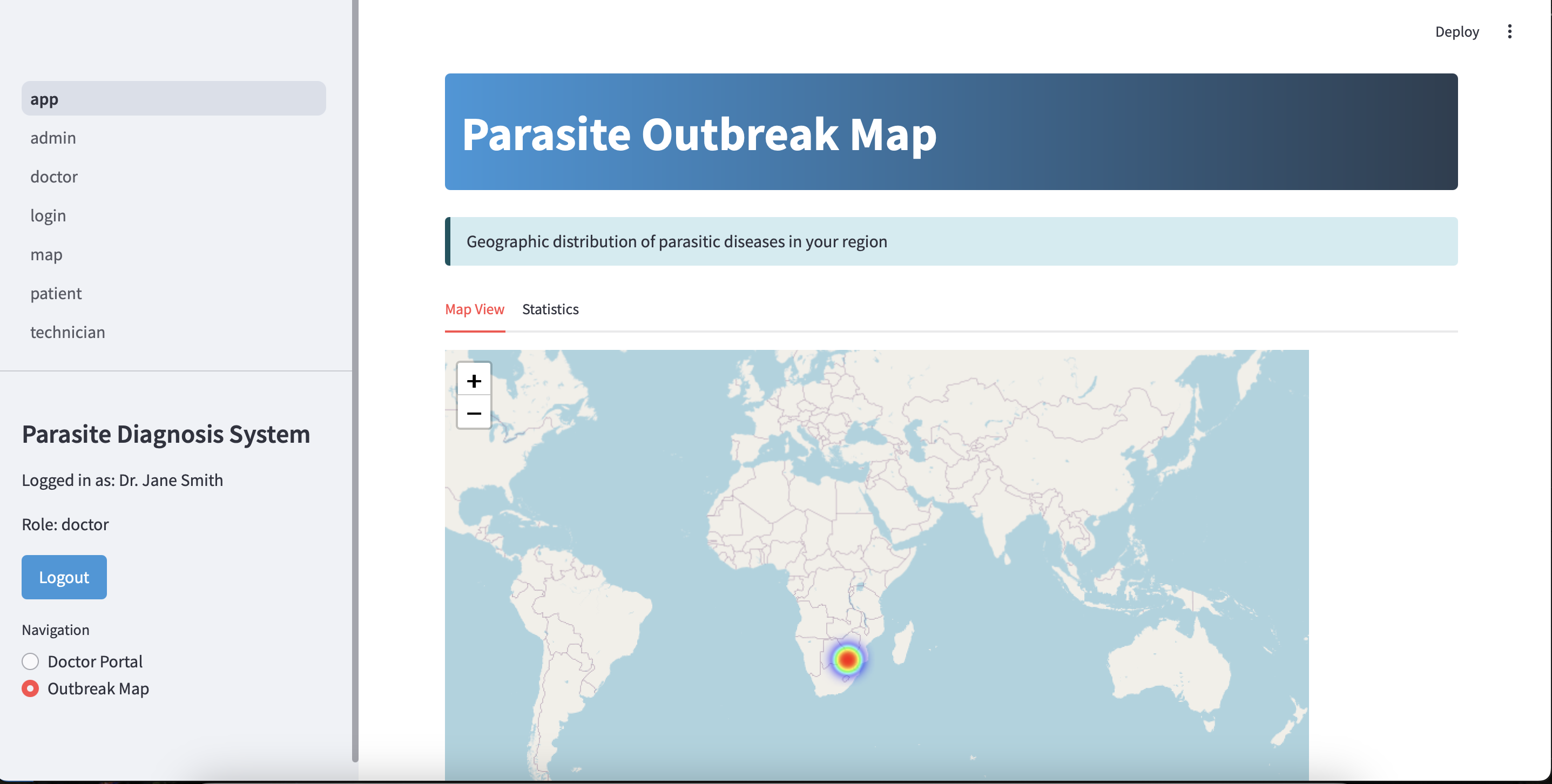
We built an application using StreamLit and SQL for our database to store patient and doctor account information. In our application with have a section whereby images can to uploaded then analyzed by our ResNet model. We also implemented an outbreak map using the StreamLit folium package.
Challenges we ran into
One of the main challenges we ran into was obtaining and processing our training dataset. As our dataset contained upwards of 34,000 images, all the photos needed to be resized and stored as NumPy arrays. Due to the sheer amount, we immediately ran into RAM utilization issues even when using cloud computing. We were able to get around this challenge because we ended up finding the dataset already published on Kaggle, so we were able to run a Kaggle notebook to preprocess the images and train our model.
Accomplishments that we're proud of
For every individual in our group, it was our first time using SQL data bases for the implementation of our platform!
What we learned
Some of the main learning take aways from this project were image processing and classification, app building and working with databases.
What's next for Symbiotic
As of right now, our model is only trained on 8 classes of cells/organisms, of which 2 of them are actually human cells (red blood cells and white blood cells). The aim in the future is to expand the number of parasite our model is able to detect. At a large scale, we can implement multiple models, each responsible for their own classes of parasites. This could be useful when deployed internationally as in different regions of the world, there exist different parasites.


Log in or sign up for Devpost to join the conversation.