About the project
Inspiration
SyllabusSync started as a practical answer to a recurring student problem: syllabi are full of dates, but manually transferring assignment and exam deadlines into calendars is tedious and error-prone. I wanted a tool that makes course deadlines instantly actionable—scan a syllabus once and automatically populate your calendar with due dates and reminders—so students and instructors can focus on learning instead of scheduling.
What I built
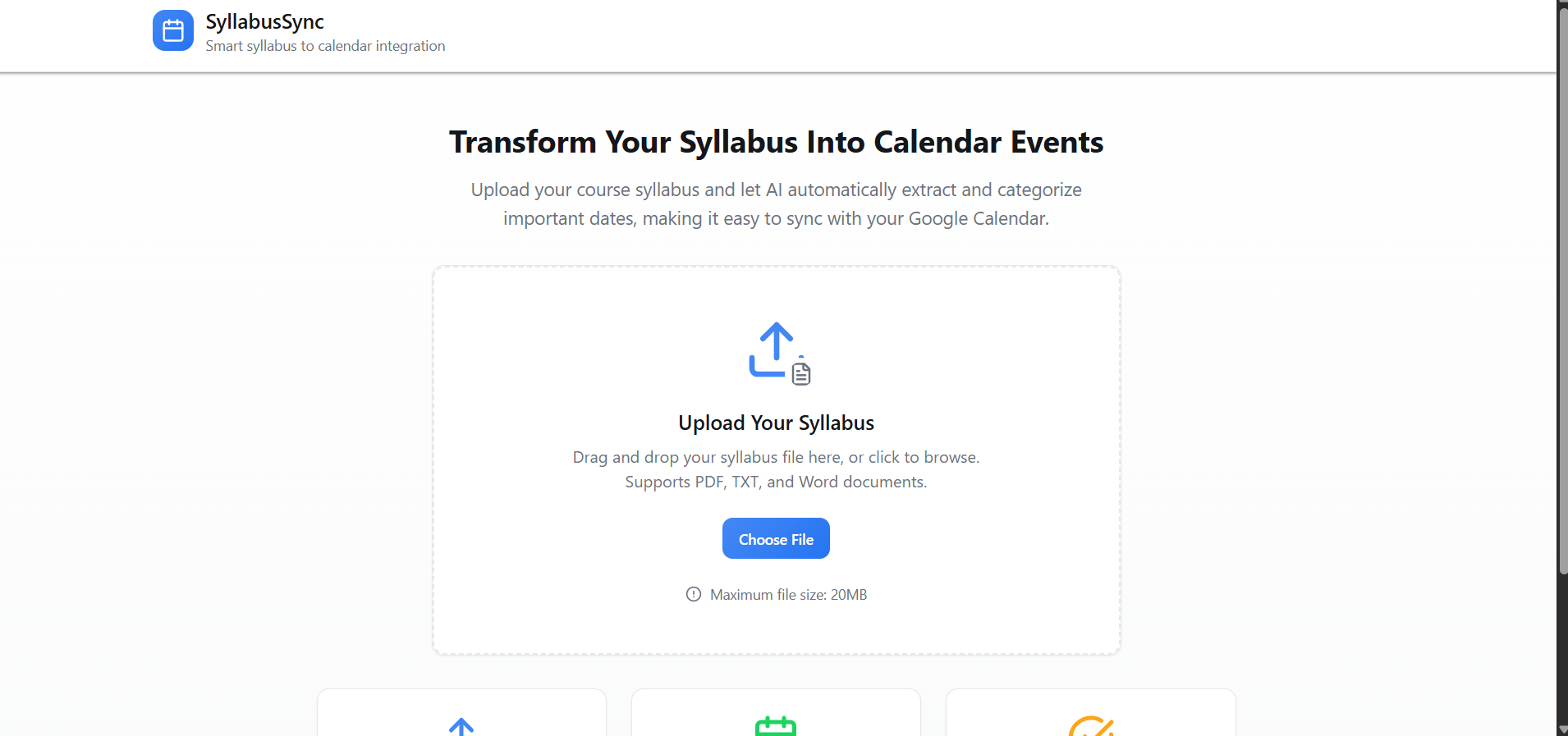
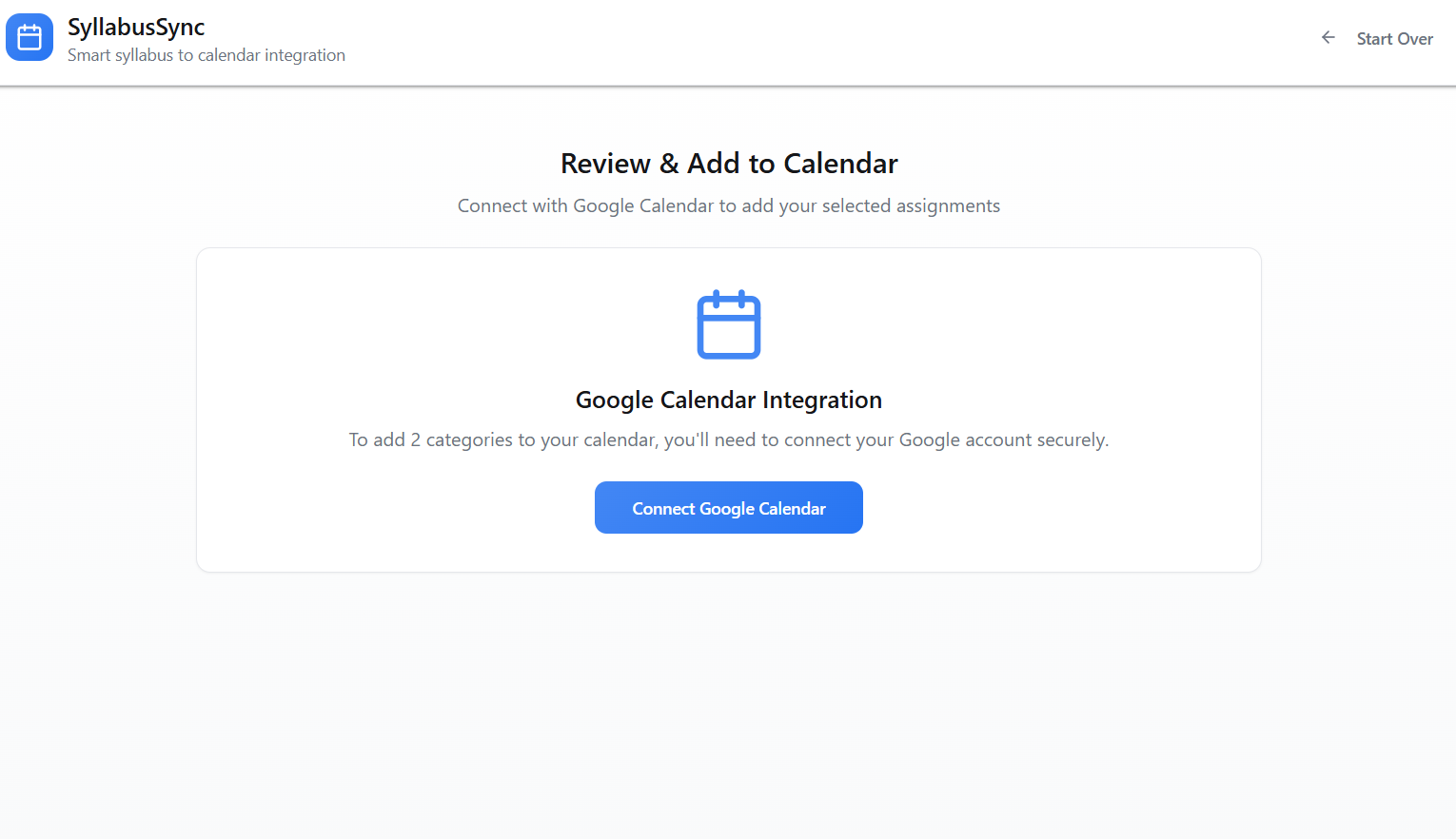
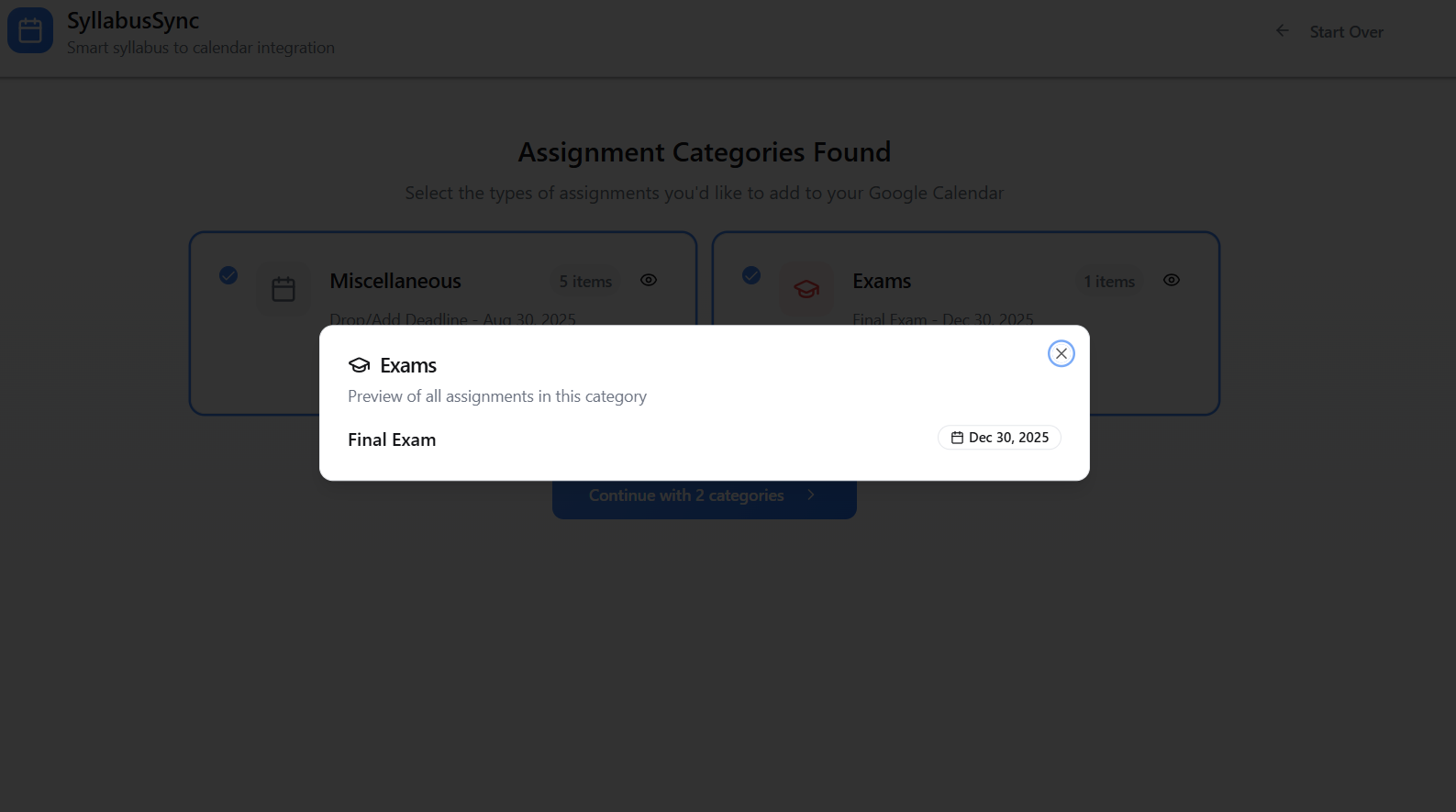
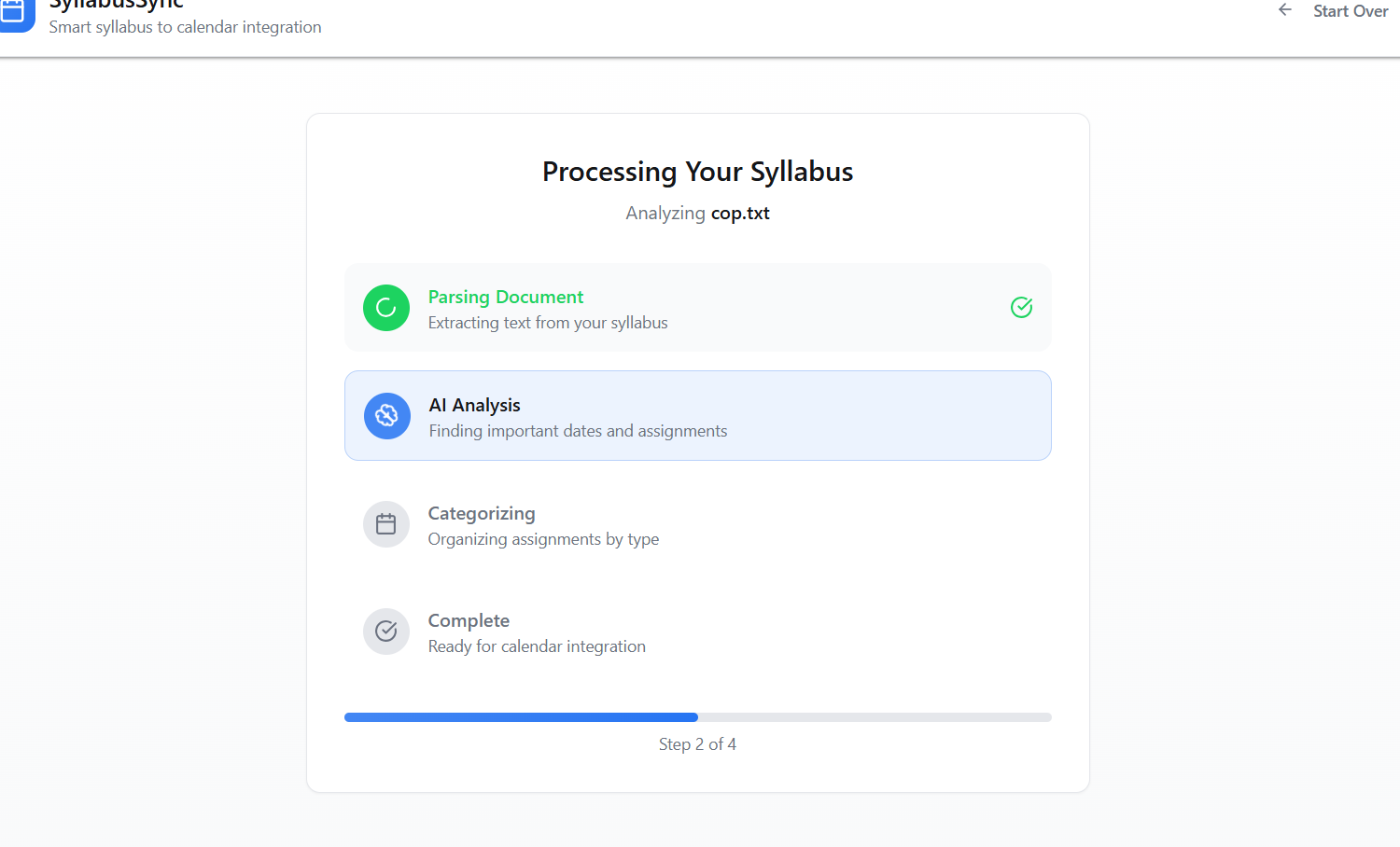
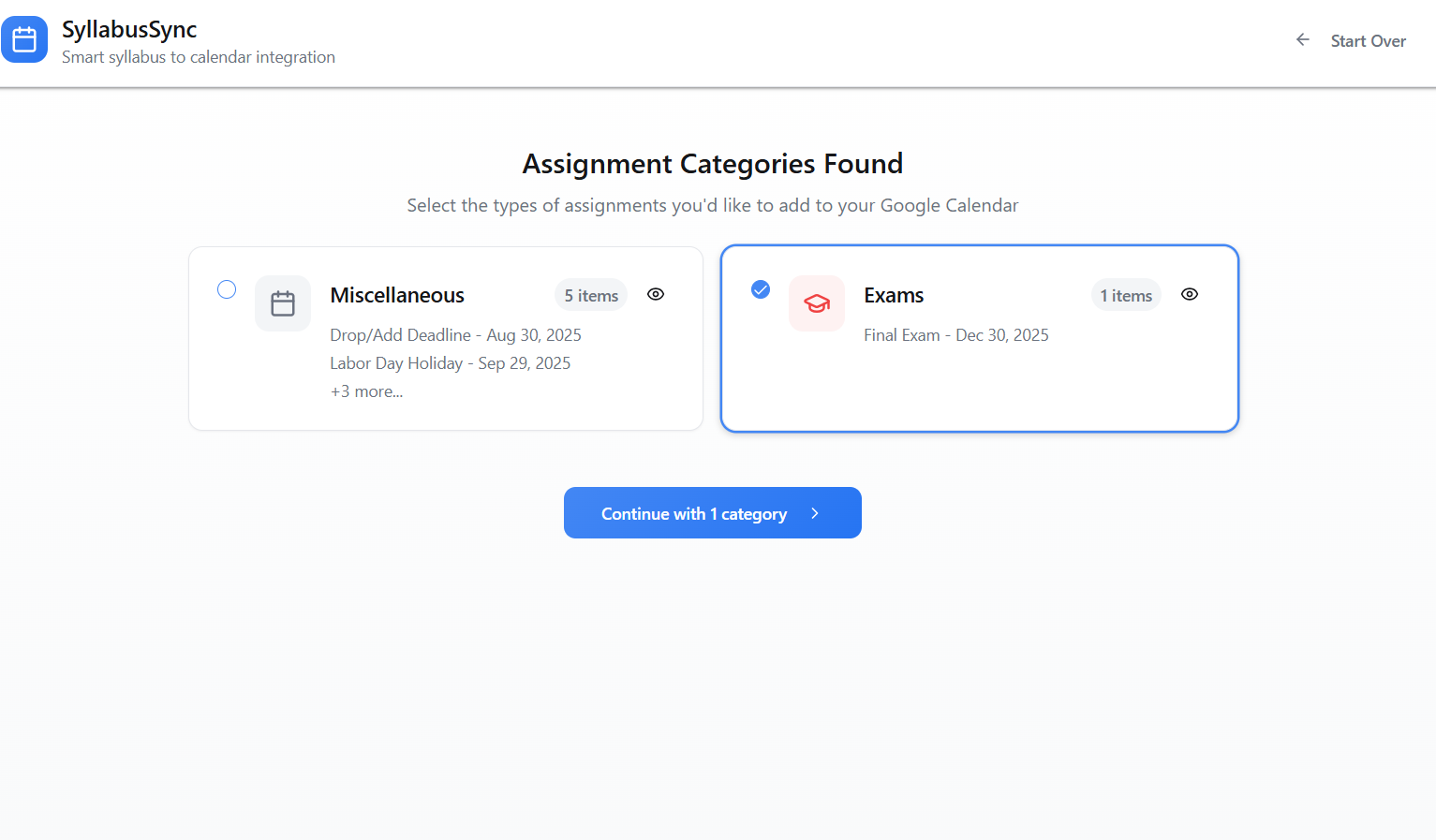
SyllabusSync is a small web app that parses course syllabi to extract assignment and event dates, normalizes and stores them, and syncs the resulting events with Google Calendar (and a Supabase backend for persistence and multi-device sync). The UI supports uploading syllabus files, reviewing parsed items, and choosing which events to add to a calendar.
How I built it
- Frontend: built with a TypeScript + React stack using Vite, Tailwind CSS, and a collection of UI primitives in ui. The app provides an upload flow, a processing step, and a calendar sync flow.
- Backend / persistence: uses Supabase for user/session management and to store parsed assignments and user preferences in supabase and supabase.ts.
- Parsing: a core parser in file-parser.ts extracts candidate date strings from uploaded syllabus text, then applies normalization and heuristics to interpret ambiguous dates (e.g., "Monday, Oct. 5" vs "Oct 5" vs "5 Oct").
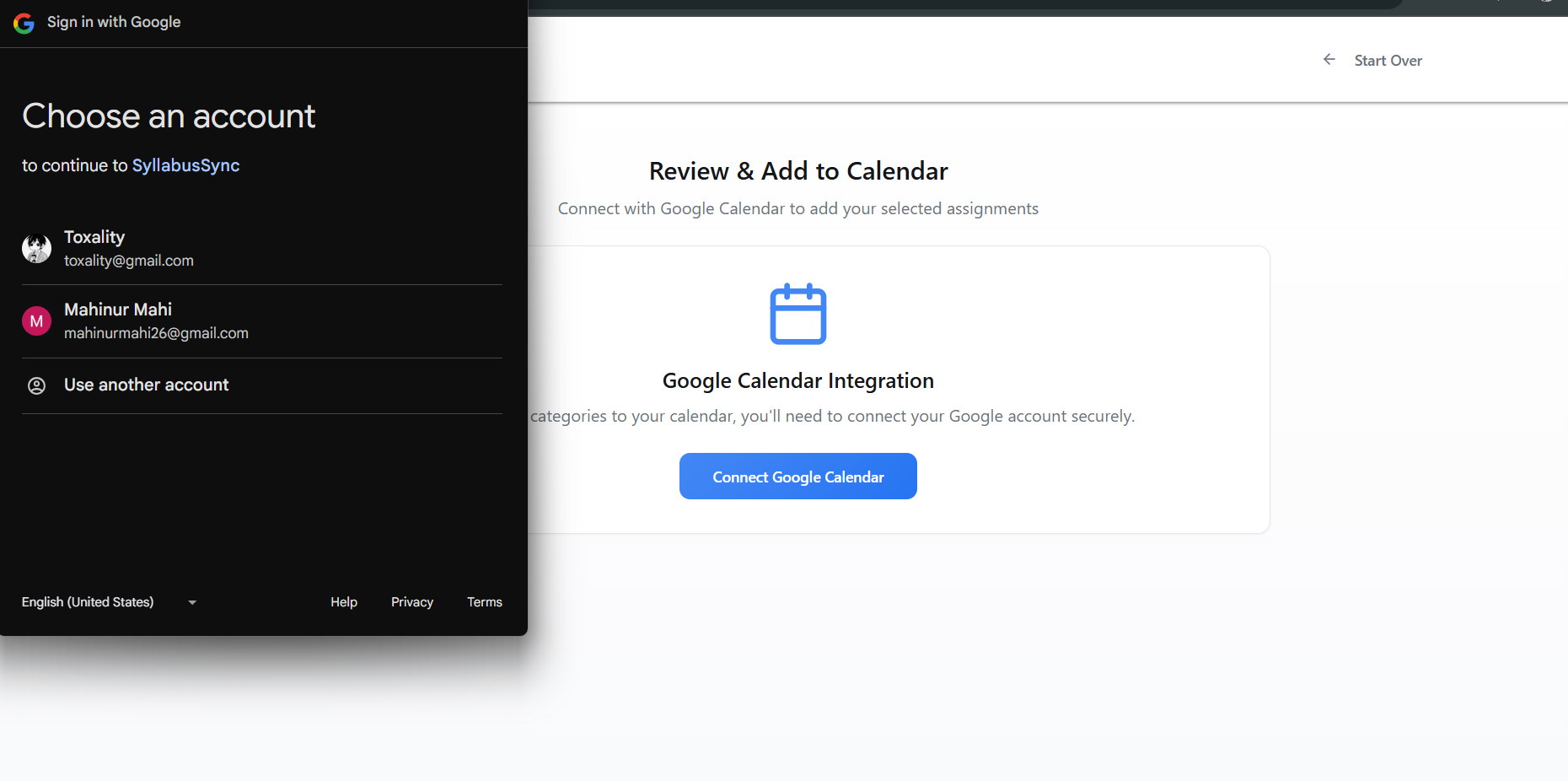
- Calendar integration: Google OAuth + Calendar API is handled in google-auth.ts and google-calendar.ts to create events based on the normalized deadlines.
- Testing: unit tests for critical parsing and normalization logic live under test and use the project's test setup in vitest.config.ts.
Key idea (brief formalization)
Parsing dates follows two main steps: detection and normalization. Let S be the set of detected date-like substrings in the syllabus text T. The parser applies a function detect(T) → S, then a normalization function norm(s, ctx) → ˆd that resolves s into an ISO date using the syllabus context ctx (course term, year hints).
We can express normalization heuristically as:
- If s contains a full year, use it.
- Else infer year y from the syllabus term; if the inferred date is earlier than the syllabus start, increment y. A concise rule used in code is: $$\hat{d} = \text{norm}(s, y_{\text{term}})$$ where norm resolves month/day and chooses $y \in {y_{\text{term}}, y_{\text{term}}+1}$ minimizing $|\hat{d} - \text{median_term_date}|$.
What I learned
- Robust text parsing needs layered heuristics. Simple regexes find candidate dates but fail on context-dependent phrases like "first Monday after spring break" or relative deadlines ("two weeks after lecture 4").
- Testing with real-world syllabi (PDFs, DOCX, and HTML) revealed many edge cases: nonstandard date formats, typos, and date ranges.
- OAuth and calendar sync flows are straightforward in development but require careful token refresh and permission scoping handling for production.
- Building a pleasant UX for verifying parsed dates is as important as the parser itself—users must be able to correct mistakes before events are pushed to calendars.
Challenges faced
- Date ambiguity: phrases without a year require inference from context; term boundaries (e.g., fall term overlapping the new year) can lead to off-by-one-year errors.
- Document formats: PDFs often need OCR or PDF text extraction; varied authoring styles mean the parser must be tolerant and resilient.
- Privacy and permission scope: only request necessary OAuth scopes and clearly explain why calendar access is needed.
- Edge-case scheduling: recurring items, ranges ("due Oct 10–12"), and relative deadlines required special handling and sometimes manual user confirmation.
Notable implementation details
- The parser's normalization pipeline uses a priority of cues: explicit year > month name > month abbreviation > numeric-only dates. When ambiguous, it uses a small scoring function that considers proximity to the course term midpoint: $$\text{score}(\hat{d}) = |\hat{d} - m_{\text{term}}|$$ and picks the $\hat{d}$ with the smallest score.
- For date ranges the system creates a single event at the end date by default but exposes the range to the user so they can create multi-day events if needed.
- Supabase stores parsed events with a confidence score; the UI surfaces low-confidence items for manual review.
Future work / improvements
- Add more NLP: use a lightweight transformer or rule-enhanced model to interpret relative phrases ("two weeks after midterm").
- Improve PDF parsing with a robust OCR fallback to handle scanned syllabi.
- Add calendar templates or course import (CSV) for instructors to upload canonical schedules.
- Handle recurring events and series more intelligently (e.g., weekly labs).
Closing note
SyllabusSync grew from a simple frustration into a practical toolchain: file ingestion → heuristic parsing → user review → calendar sync. The core trade-offs were between automation and user control; deliberate confirmation steps help keep calendar data accurate while saving a lot of manual work. config.ts.



Log in or sign up for Devpost to join the conversation.