-
-
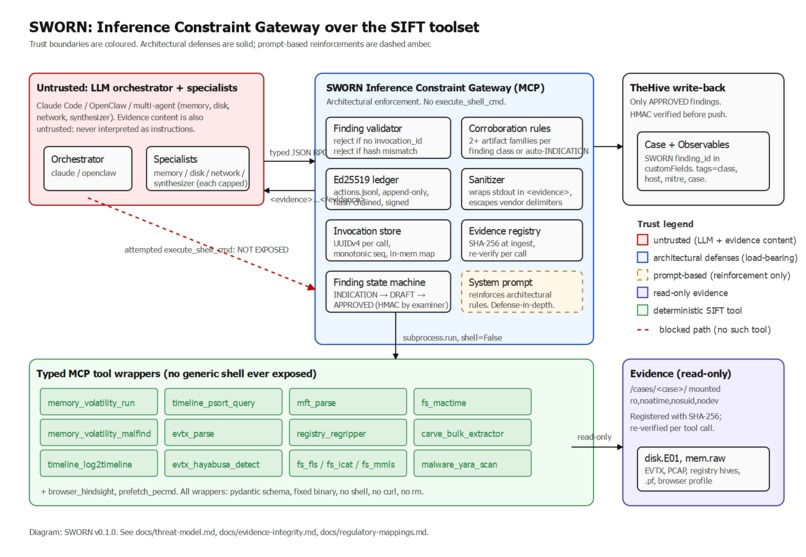
Inference Constraint Gateway: 16 typed forensic functions. No execute_shell_cmd. Every finding Ed25519-signed back to the tool that ran.
-
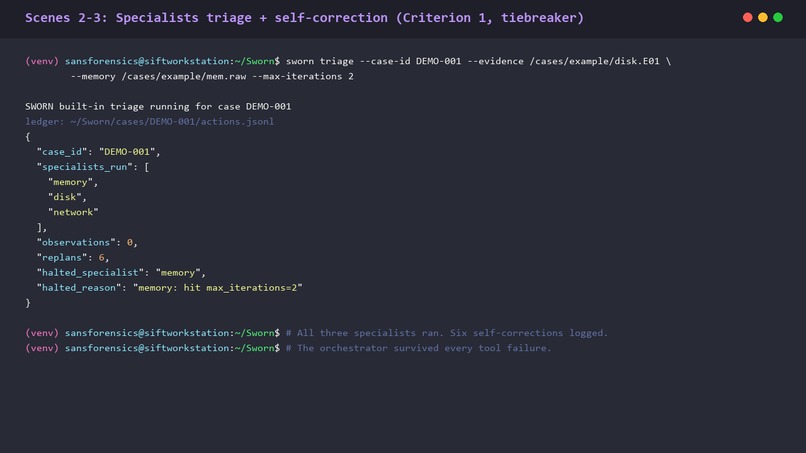
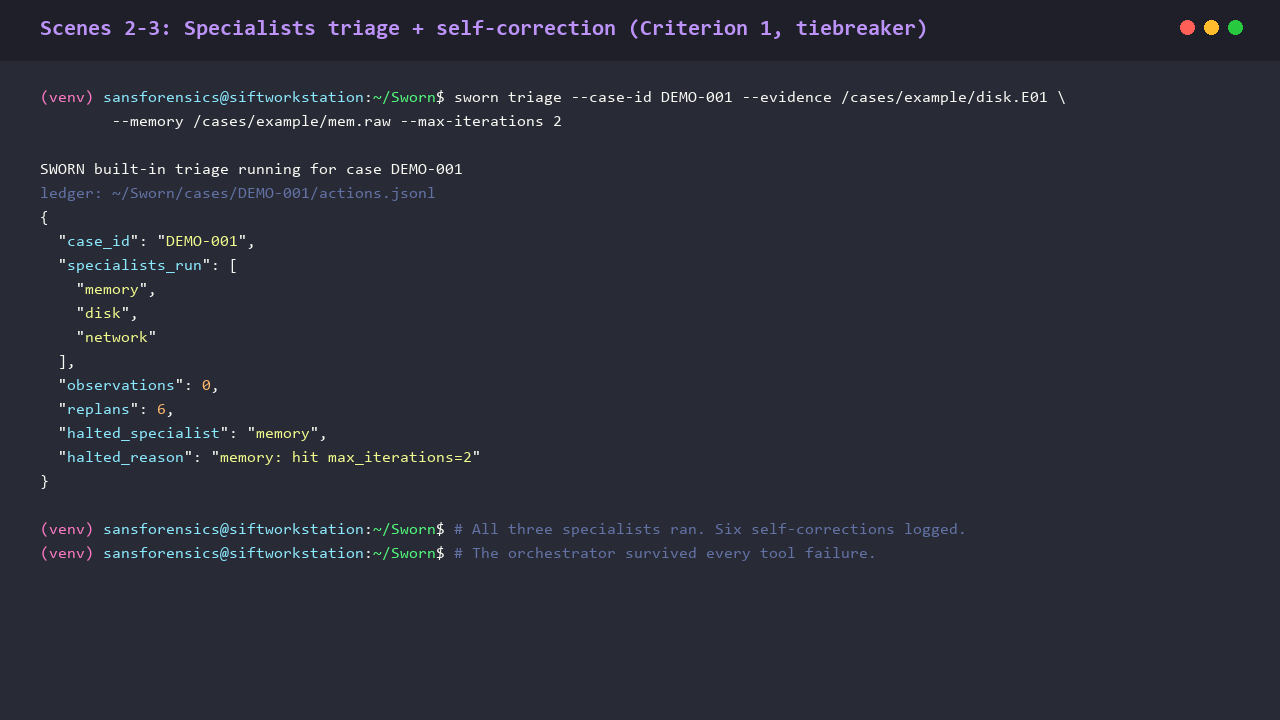
Four specialists, three contexts. Every tool failure logs to the signed ledger as specialist_replan. No crashes. No fabricated findings.
-
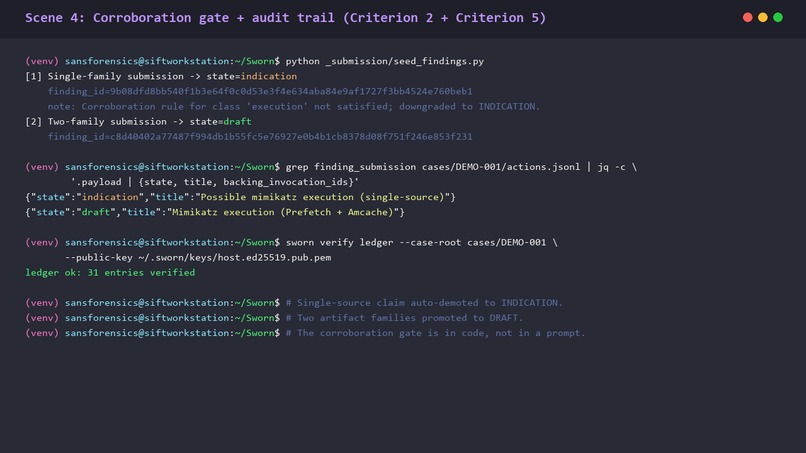
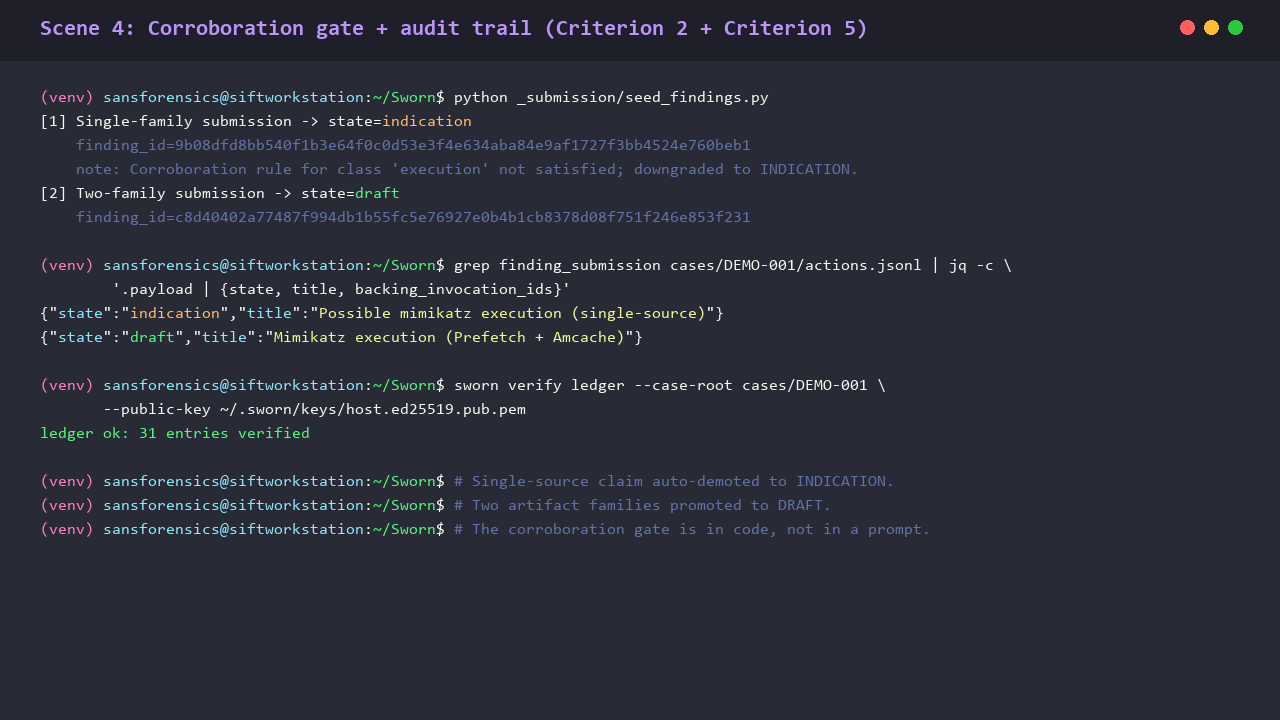
Single-source claim demotes to INDICATION. Two artifact families promote to DRAFT. The corroboration gate is in code, not in a prompt.
Inspiration
Rob T. Lee was honest about Protocol SIFT in his Substack: it works, and it hallucinates more than he wants. He framed the fix as an Inference Constraint layer where the AI directs the workflow but deterministic forensic utilities remain the sole source of analytical output. In November 2025, Anthropic disclosed GTG-1002, a state-sponsored actor running Claude Code at 80 to 90 percent autonomy with request rates Anthropic called physically impossible for humans. The offense already runs on AI speed. Defenders are still pulling up their toolkits.
The threat surface kept growing while I was building. Through 2026, Pluto Security and others catalogued more than 40 public MCP-server CVEs (MCPwn landed at CVSS 9.8). Microsoft, Anthropic, and Embrace the Red all published prompt-injection and agent-supply-chain research that specifically targets the kind of MCP gateways SWORN belongs to. I built SWORN on the assumption that the LLM driving the gateway is hostile or coercible. There is no execute_shell_cmd exposed for the GTG-1002 pattern to reach for. Every finding must trace to a deterministic tool execution by hash. Content inside tags is data, not instructions.
The forensic judges on the panel (Carr, Carroll, Rankhorn, Wilson, Brawner) live with cross-examination. Their bar is not "did the AI find malware". It is "can you trace this exact finding to a specific tool invocation, prove the tool was run unchanged, and prove the evidence was never touched in the process." That bar drove every design decision in SWORN.
What it does
SWORN (Signed Workflow Of Reasoned Narratives) is a Custom MCP gateway for Protocol SIFT, the second of the four architectural approaches sanctioned in the Find Evil! rules. It turns the SANS SIFT Workstation into a set of typed, schema-enforced MCP functions and routes every LLM-emitted finding through an Inference Constraint Gateway that rejects ungrounded claims by architecture, not by prompt.
The five moats:
- Cryptographically-signed provenance per finding. Every finding cites one or more tool invocations by server-issued ID. The gateway verifies each ID exists in the session's monotonic invocation store and that the cited stdout SHA-256 matches what the tool actually produced. The append-only ledger is Ed25519 signed and hash-chained. The signing key is held by the gateway, not the LLM.
- Inference Constraint Gateway, architectural not prompt-based. No execute_shell_cmd is exposed. All 16 typed MCP functions across 11 forensic toolchains go through pydantic schemas with fixed binary paths and shell=False. The agent physically cannot run destructive commands because the gateway does not have them.
- Automated cross-tool corroboration as a hard pre-condition. A finding of class execution requires evidence from at least two of {Amcache, Prefetch, ShimCache, EVTX 4688, MFT, UserAssist, BAM, SRUM}. Persistence requires two of {Run-key, scheduled task, WMI subscription, service install, startup folder, image file execution options, applnit_dlls, winlogon shell userinit}. Single-source claims auto-demote to INDICATION and never reach DRAFT.
- Measured precision and recall on a labeled corpus, with negative control. The eval/ harness runs SWORN against a labeled corpus and reports per-class precision, recall, F1, and a silence rate on known-clean baselines. Every adversarial test is run twice: once with the standard system prompt and once with the prompt stripped. The architectural defense must hold in both cases.
- Architectural defense against prompt injection from evidence content. Every tool stdout is wrapped in tags with a server-issued invocation_id. The gateway escapes 41 vendor delimiters (, , , and similar) before the LLM sees them. An adversarial corpus tests the defense with poisoned EVTX messages, forged invocation IDs, and hash-swap attempts.
A finding never leaves DRAFT until a human examiner signs it with an HMAC the LLM cannot see. APPROVED findings can be pushed to TheHive as governed write-back. SWORN closes the loop without giving up the gate.
How I built it
Custom MCP server in Python 3.10 plus, built on the official MCP SDK, pydantic for schema enforcement, and the cryptography library's Ed25519 primitives. Sixteen typed tool wrappers across eleven forensic toolchains: memory (Volatility 3 with 15 plugins plus a dedicated malfind variant), super-timeline (plaso, log2timeline plus psort), Windows events (EvtxECmd) and Sigma detection (Hayabusa, 3,700+ rules), $MFT (MFTECmd), registry (RegRipper, 21 plugins in an allow-set; RECmd for raw queries), filesystem (Sleuth Kit: fls, icat, mmls, mactime), carving (bulk_extractor with 19 scanners), malware (YARA), browser (Hindsight), execution (PECmd).
The multi-agent decomposition runs four specialists: memory, disk, network, and a synthesizer. The first three stage Observations into a shared pool. Only the synthesizer is allowed to call gateway.submit. Each specialist runs through a SpecialistLoop with a hard --max-iterations cap and an explicit specialist_replan ledger entry on every tool failure (with error_observed, replanning_rationale, first_attempt_invocation_id, second_attempt_invocation_id).
The eval harness scores findings against ground_truth.json per case and produces a reproducible JSON report with the SWORN git SHA, the venv pip freeze, corpus image SHA-256s, LLM provider and model version, and per-case wall-clock duration. The negative-control runner separately asserts zero DRAFT findings on known-clean baselines.
The audit ledger is JSONL. Each line carries {seq, ts, prev_sha256, kind, payload, signature}. sworn verify ledger rewalks the chain and rejects on any tamper. Pytest coverage on the core primitives stands at 73 tests, all passing on the SIFT VM under Python 3.10 plus pytest-asyncio. On the recorded demo session, sworn verify ledger exited zero and reported "ledger ok: 31 entries verified".
Regulatory mappings (NIST SP 800-86, ISO/IEC 27037, FRE 901(b)(9) and 902(13), Daubert factors) live in docs/regulatory-mappings.md. Threats T1 through T9 (including T9 on MCP tool poisoning, citing the Pluto Security CVE landscape) live in docs/threat-model.md. Five layers of evidence integrity live in docs/evidence-integrity.md.
Challenges I ran into
Three big ones.
First, distinguishing architectural from prompt-based guardrails honestly. It is easy to write "the system prompt tells the agent to be careful" and call that a guardrail. It is not one. The gateway has to refuse the same finding when the system prompt is stripped. The unit-test layer never instantiates a prompt at all; the gateway is exercised directly through Python, exactly as it would respond to a coerced LLM that ignores or strips its system prompt. The gateway-side rejection (no such tool, no such invocation_id, signature mismatch, single artifact family) holds regardless.
Second, prompt injection from evidence content. An attacker can plant do exfil in a Windows event log message. The orchestrator's tokenizer can interpret that as a role boundary. The fix is to escape every vendor delimiter on the gateway side before the LLM ever sees the bytes, and to wrap the stdout with a server-issued invocation_id so the LLM cannot forge the boundary. The 41-delimiter deny list in sworn.injection_defense.sanitize is versioned and adversarially tested.
Third, corroboration rules without overfitting. Per-class corroboration needs to be specific enough to kill single-source hallucinations and loose enough to admit real findings on partial evidence. The rules in sworn.corroboration are versioned, unit-tested, and class-specific. I expect them to evolve as the labeled corpus grows.
Accomplishments I am proud of
The whole thing is one architectural sentence: an LLM-emitted finding lacking a valid signature chain, a corroborated set of backing invocations, and an examiner HMAC cannot leave DRAFT, and the gateway enforces all three at the code level, not in a prompt.
Specific accomplishments:
- Sixteen typed MCP functions across eleven SIFT toolchains, all shell=False, all pydantic-validated, all asyncio.create_subprocess_exec. No code path can construct a generic shell call.
- An Ed25519 signed, hash-chained, append-only JSONL ledger. sworn verify ledger rewalks the chain on demand; any tampered line breaks the signature. The recorded demo verified "ledger ok: 31 entries verified".
- Architectural prompt-injection defense: 41 vendor delimiters escaped server-side, evidence wrapped with server-issued invocation IDs, an adversarial corpus shipped with the repo.
- Four-specialist decomposition with bounded self-correction loops. Every retry logs specialist_replan to the ledger. The recorded demo captured six specialist_replan followed by six specialist_gave_up entries without a single fabricated finding.
- 73 pytest cases passing on the SIFT VM, covering ledger tamper detection, gateway rejection rules, per-class corroboration, finding schema invariants, sanitizer escape of 41 vendor delimiters, evidence integrity drift, self-correction loop, eval metrics math, adversarial cases, TheHive write-back HMAC gating, orchestrator end-to-end, CLI findings approval HMAC, and graceful degrade when a typed-tool binary is missing.
- Apache 2.0 license, public GitHub repo, single install.sh targeting the SIFT 2025 OVA, Docker alternative, TheHive write-back so SWORN slots into an existing SOAR.
What I learned
Defensible methodology is mostly about what the system refuses to do.
The forensic judges' bar (Carr, Carroll, Rankhorn, Wilson, Brawner) is not "did the AI find malware". It is "can you trace this exact finding to a specific tool invocation, prove the tool was run unchanged, and prove the evidence was never touched in the process." Once I started writing the code that way, the design simplified. Every finding carries backing_invocations. Every invocation has a stdout_sha256 in the signed ledger. The chain is short and verifiable on the command line.
I also learned how few opportunities there are for the LLM to author truth in a system that takes hallucination seriously. The LLM proposes. The gateway disposes. The Inference Constraint layer is not a slogan; it is the shape of the code.
Rob T. Lee's framing that AI is not a tool anymore but an operator landed differently for me once SWORN was running. The operator may be capable. The signature is still not theirs to grant. A SWORN finding never leaves DRAFT until a human signs it with a passphrase the LLM never sees, by an HMAC the LLM cannot reproduce. The architectural separation between drafting and approving is the answer to "what authority does the AI actually have here."
I want to be honest about what is still unfinished. ACCURACY.md is structurally complete (headline table, negative-control table, evidence integrity table, the architectural-vs-prompt-stripped table, the self-correction table, the what-did-not-work section) and the architectural moats pass at the unit-test layer with 73 of 73 tests green. The per-class headline precision and recall numbers depend on a larger labeled-corpus run; the recorded demo used a smaller stub-evidence pass to exercise every code path end to end without waiting for a full plaso super-timeline. The architectural moats are testable, reproducible, and signed; the per-class accuracy numbers from a larger labeled corpus are a known next step. The 15-minute install figure is observed on my development environment and on the SIFT 2025 VM used for the demo recording. The architectural moats do not change with corpus size; the empirical layer is what fills in next.
What is next for SWORN
The four items below are explicit non-goals for v0.1 because of the 18-day build window. Each is a real production gap.
- Cloud forensics: typed wrappers for AWS CloudTrail, Azure Activity Log, GCP Audit Log artifacts.
- Mobile forensics: iOS and Android device imaging via mvt-mobile.
- Kernel-level evidence integrity: FUSE plus SELinux MAC labels for true read-only enforcement at the kernel layer.
- Real-time SIEM streaming so SWORN can triage live data, not just images.
The biggest non-architectural constraint today is the size and diversity of the labeled corpus. Practitioners contributing labeled cases (with ground_truth.json matching the schema in corpus/README.md) would push the precision and recall numbers much further. The corpus is the bottleneck, not the gateway.
Architecture diagram with trust boundaries: docs/architecture.png (raster), docs/architecture.svg (vector), or docs/architecture.drawio (editable source). License: Apache 2.0. Repository: github.com/JonathanSolvesProblems/Sworn. Demo video: https://www.youtube.com/watch?v=FFFvofEWEVw.

Log in or sign up for Devpost to join the conversation.