-

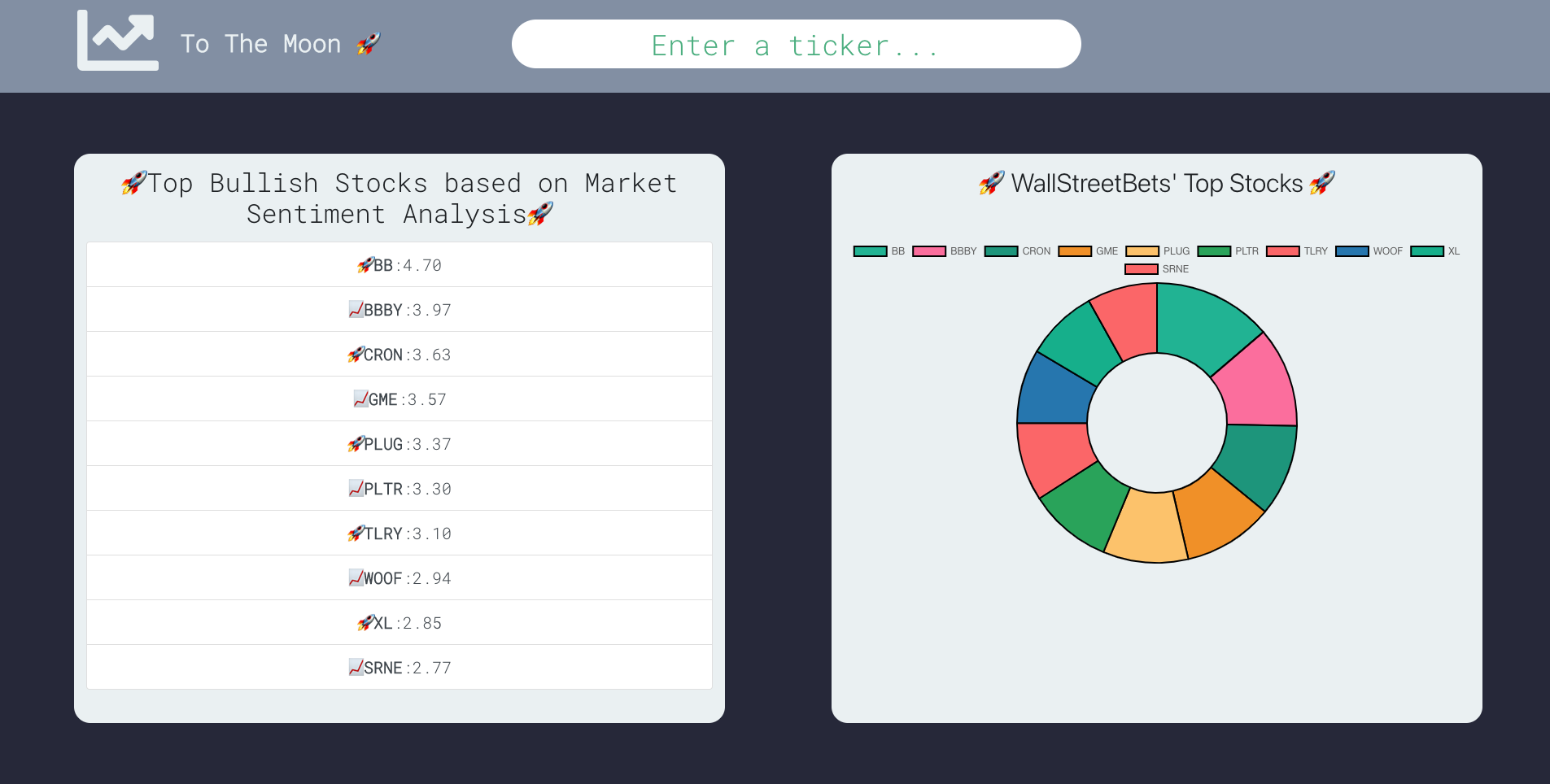
Top bullish stocks and r/wallstreetbets portfolio
-
Analytics on each stock and all of the aggregated comments (slight profanity from comments)
-

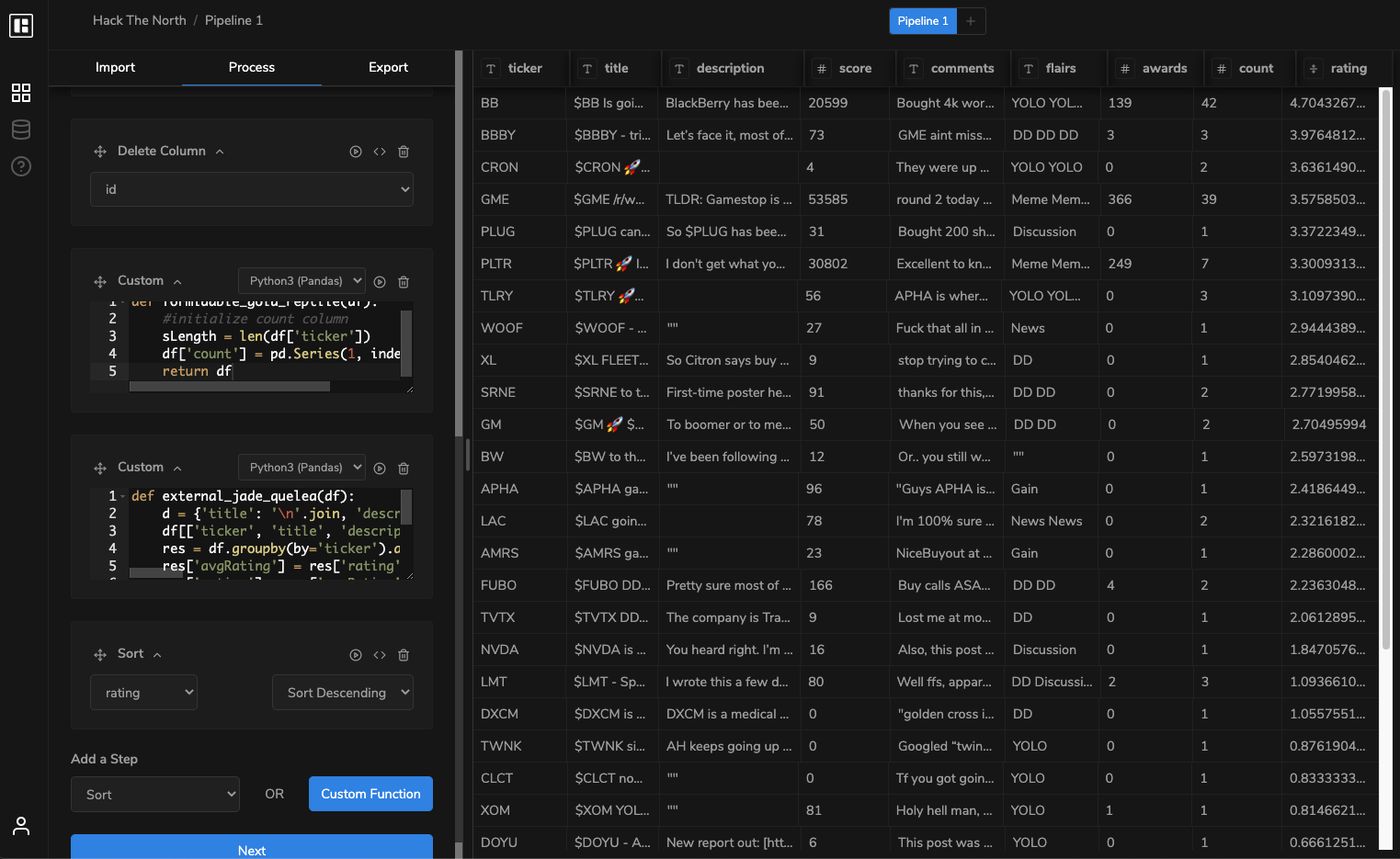
Dropbase Data Pipeline
-
Scraping r/wallstreetbets (slight profanity from comments)

Video
Please refer to this link for our videos!
Inspiration
When a person wishes to enter the world of personal finance and investing, they can often be greeted with a sea of information. What's a ticker? Where can I buy stocks? When should I buy and sell? These questions are daunting, but as all seasoned traders know there exists a lighthouse to guide investors in this complex sea of information: r/wallstreetbets. As aspiring investors ourselves, we find this subreddit to be the pinnacle of high-quality, unbiased information, and as such, it seemed like a no-brainer for us to analyze this content.
What it does
With "To the Moon" we compile all the accurate and well-thought-out information from this glorious forum into a concise, easy-to-digest web application that rates stocks discussed on r/wallstreetbets based on market sentiment achieved through natural language processing algorithms. We provide information such as the list of the stocks currently being discussed, ordered from most bullish to most bearish, and how a portfolio of r/wallstreetbet's favourite stocks would look like. A user can also search up each individual ticker directly to find more information on the specific stock's performance on the subreddit.
How we built it
Using PRAW library on Jupyter Lab, we scrape through r/wallstreetbets and retrieve post data such as titles, comments, flairs, scores, awards, and most importantly, the amount of 🚀 and "YOLO"s. From this, we create a data pipeline using Dropbase to clean up and process the data using Google Cloud's natural-language sentiment analysis. We consolidate all of the posts about a certain stock into one row and an aggregated rating. This data is loaded onto a Postgres database, where we designed our own API to fetch the necessary information using a Flask backend. With this rating and a variety of other stock information data, we are able to create data visualizations and provide analytics on each individual stock on our React front-end.
Challenges we ran into
Our main challenge was learning and understanding how pipelines work on Dropbase, and how to interact with the API. With the help of the incredibly supportive team, we were able to debug all of the problems that we were facing and set up our pipeline (as well as fine-tune it however we wanted). Another challenge we ran into was designing our backend to decide which tasks go in the scraping or data processing stages. Originally, we had our Google Natural Language Processing being performed after we retrieved the data from the Postgres DB, but that proved to take very long for the endpoint to be responsive (and did not fulfill AJAX principles). As such, we decided to move the NLP to the data scraping stage and process it before feeding it through the Dropbase pipeline, which helped significantly.
Accomplishments that we're proud of
- Our team is incredibly proud of being able to stitch together 3 APIs that none of us have worked with before, specifically: Dropbase, Google Cloud NLP, and PRAW (with Reddit) for scraping purposes.
- Our ratings algorithm based on NLP and a variety of other variables provided fairly realistic ratings (based on the current performance and popularity of the stocks).
- Setting up an efficient data pipeline with Dropbase to effectively import, process (clean), and export data to a database to retrieve in our web-app.
What we learned
- Scraping data, processing data in a pipeline, performing analysis on data and putting data in visualizations.
- How powerful Dropbase data pipeline is, and how many useful functionalities that it provides
- How easy it is to use Google Cloud's Natural Language Processing API, incredible documentation
- r/wallstreetbets users truly embrace their freedom of speech and love to use condescending metaphors, as well as the 🚀 emoji.
What's next for "To The Moon"
- We wish to construct an actual portfolio using r/wallstreetbets data and seeing how it performs compared to common indexes such as the S&P 500.
- Further improving our rating system, using better machine learning models and figuring out a way to scrape in a larger data set.
- Graphing data against time, determining the differences and overlaying the performance of the stock against the rating of the stock.
Built With
- css
- dropbase
- flask
- html
- javascript
- jupyter-notebook
- postgresql
- python
- react
- shell
- sql











Log in or sign up for Devpost to join the conversation.