-
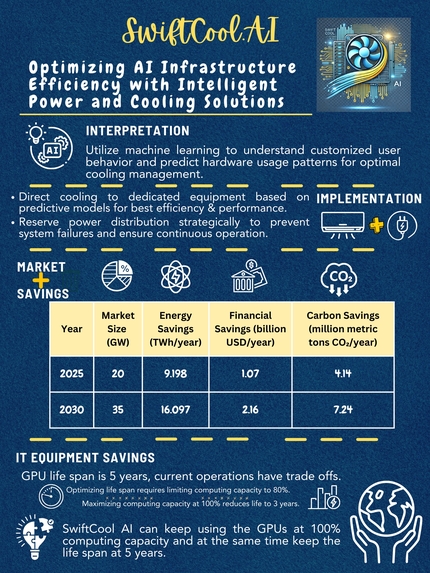
SwiftCool AI Project Overview & Pitch
-
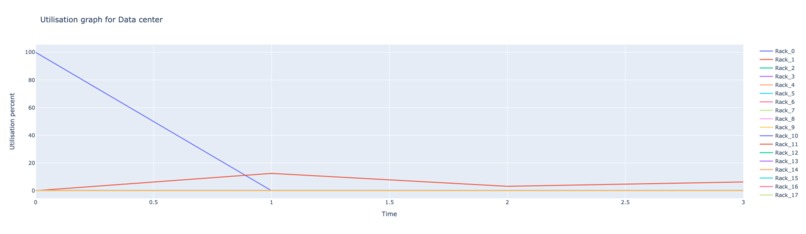
End output to control the cooling systems
-
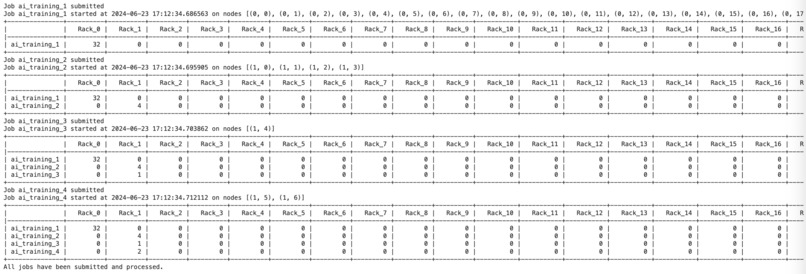
End output to predict the job allocation
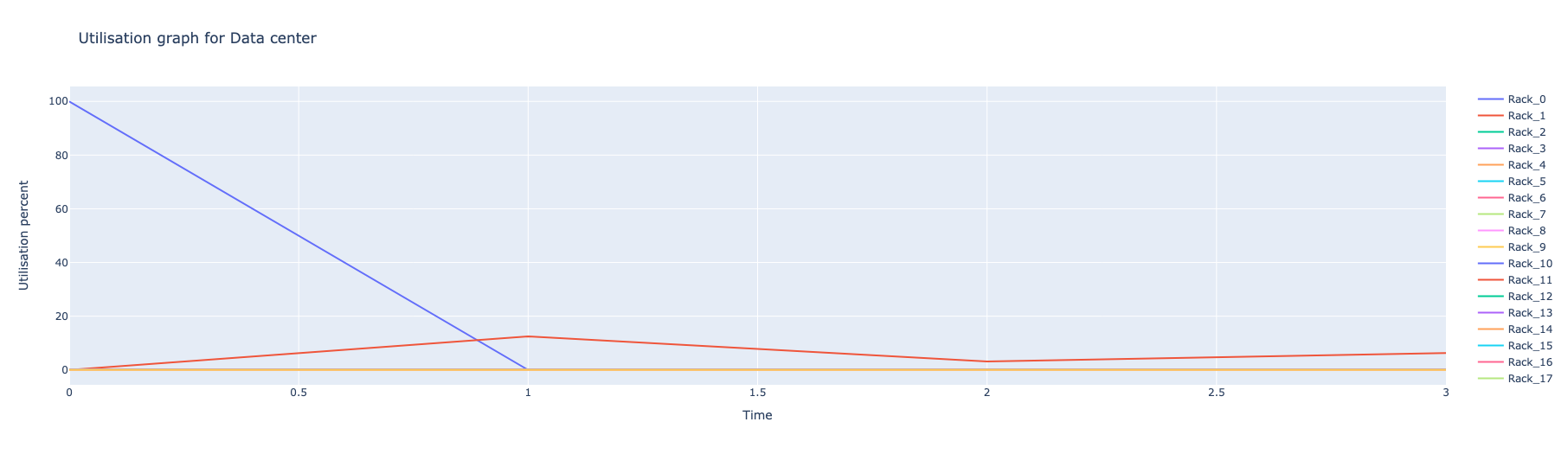
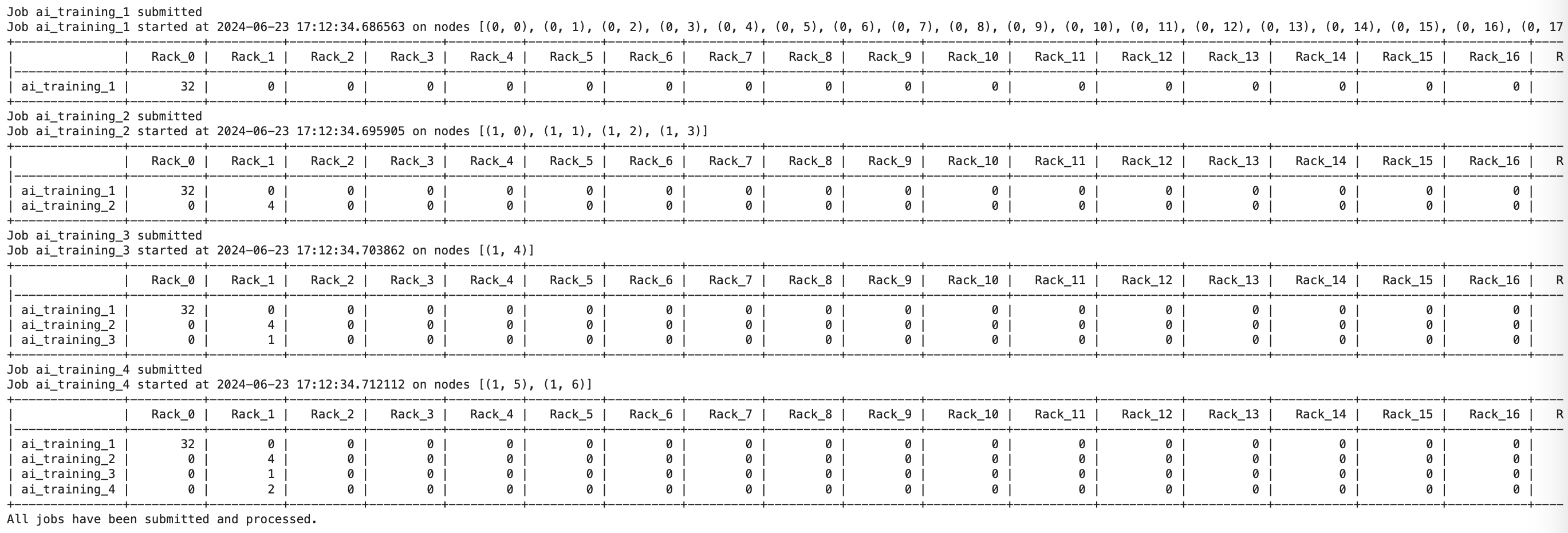
Project Story: Proactive, AI-Driven Cooling and Power Management
About the Project
Inspiration and Market Validation
Our project was inspired by insights gained from the NSF ICorps course in May, where we received strong market validation for the problem we aimed to solve. To ensure we were addressing a real need, we conducted over 20 customer interviews with representatives from big tech firms, industry experts, and data center professionals who specialize in cooling and power distribution services. These interviews confirmed that the problem of inefficient cooling and power management in data centers is prevalent and impactful.
Learning and Development
Throughout this project, we learned extensively about the transition from CPUs to GPUs in data centers and the associated challenges in cooling and power distribution. Traditional air-cooling systems are becoming inadequate as data centers shift towards liquid cooling to manage the increased heat output from GPUs. Despite this transition, even large tech companies are still experimenting with and refining liquid cooling systems. This gap in the market presents an opportunity for innovative solutions like ours.
Building the Project
Our hackathon project aimed to create an MVP that leverages AI to make cooling and power management predictive rather than reactive. We used SLURM, a workload manager and job scheduling system, to gather data about GPU availability and job scheduling. Our system predicts when and where jobs will run and proactively triggers the cooling systems before the GPUs heat up, thereby optimizing cooling efficiency.
Challenges Faced
We faced several challenges during the development of this project:
- Data Collection: Gathering accurate and comprehensive historical job data, node availability, and job scheduling logs from SLURM was time-consuming and required meticulous attention to detail.
- Model Accuracy: Building a predictive model that could accurately forecast job run times and node allocations was complex. We tested various machine learning models, including Random Forest, Gradient Boosting Machines, LSTM, and GRU, to improve prediction accuracy.
- Integration with Existing Systems: Integrating our predictive system with existing data center infrastructure, which traditionally relies on reactive cooling mechanisms, required careful planning and implementation.
Implementation Details
Steps to Implement the Project
Data Collection:
- Historical Job Data: Collect data on job submissions, including job ID, submission time, requested resources (CPU, memory, GPUs), priority, and actual start and end times.
- Node Data: Gather information on node availability, current workload, and resource usage.
- Job Scheduling Logs: Extract SLURM scheduling logs that detail job allocation and execution.
Feature Engineering:
- Create Relevant Features: Include features such as time of submission, day of the week, job priority, resource requirements, and node state (idle, allocated).
- Time Series Features: Use lag features (e.g., previous job allocations) and rolling statistics (e.g., average load in the past hour).
Model Selection:
- Classification Models: Random Forest, Gradient Boosting Machines, and Logistic Regression for predicting server allocation.
- Time Series Models: LSTM and GRU for predicting the time of allocation.
- Regression Models: Linear Regression and Decision Trees for predicting the time until allocation.
Predictive Model Approach:
- Data Collection: Gather historical scheduling data from SLURM logs, including job submissions and their attributes, node allocations, and resource usage.
- Feature Engineering: Develop features related to job priority, requested resources, expected runtime, and node state.
- Modeling: Use a classification approach to predict the node allocation for a job or a regression approach to predict resource allocation probabilities and select the node with the highest probability.
Results and Benefits
By implementing this predictive cooling and power management system, we anticipate the following benefits:
- Increased Cooling Efficiency: Proactively triggering cooling systems based on job predictions reduces the power required for cooling by at least 10%, resulting in significant cost savings.
- Extended Equipment Life: Optimized cooling management increases the lifespan of data center equipment by reducing thermal stress.
- Environmental Impact: Reducing the power required for cooling contributes to lower overall energy consumption, aligning with global sustainability goals.
Future Plans
Post-hackathon, we plan to further refine our MVP and seek early adopters to implement this solution. The transition to GPU-based data centers is an ongoing trend, and our proactive cooling and power management system is well-positioned to address the associated challenges. By continuing to improve our predictive models and integrating more advanced AI techniques, we aim to revolutionize data center operations and significantly reduce their environmental footprint.
Built With
- colab
- numpy
- pandas
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.