-
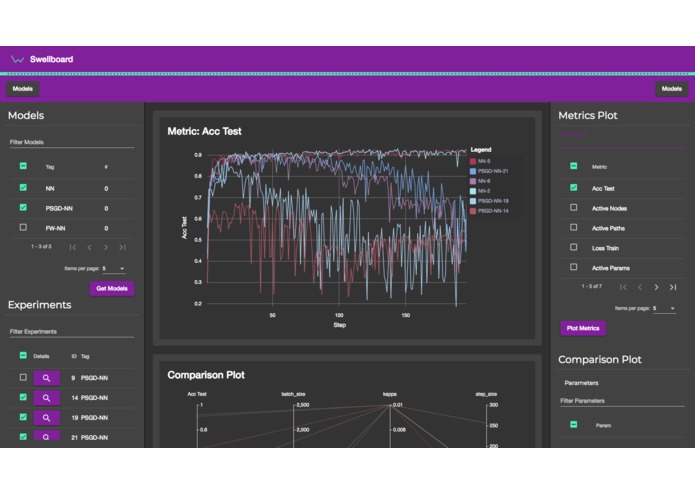
Full Board Overview
-
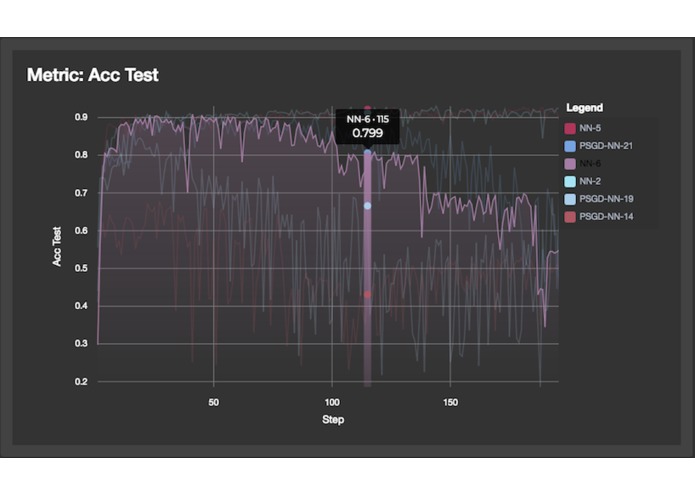
Metrics over time
-
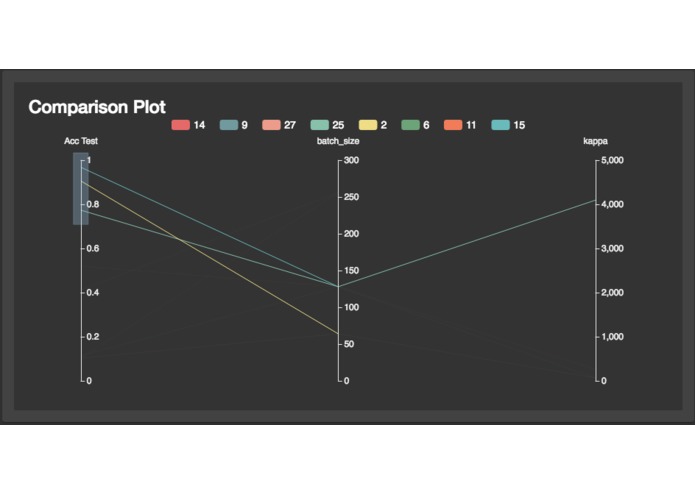
Comparison to find the next best hyperparameters
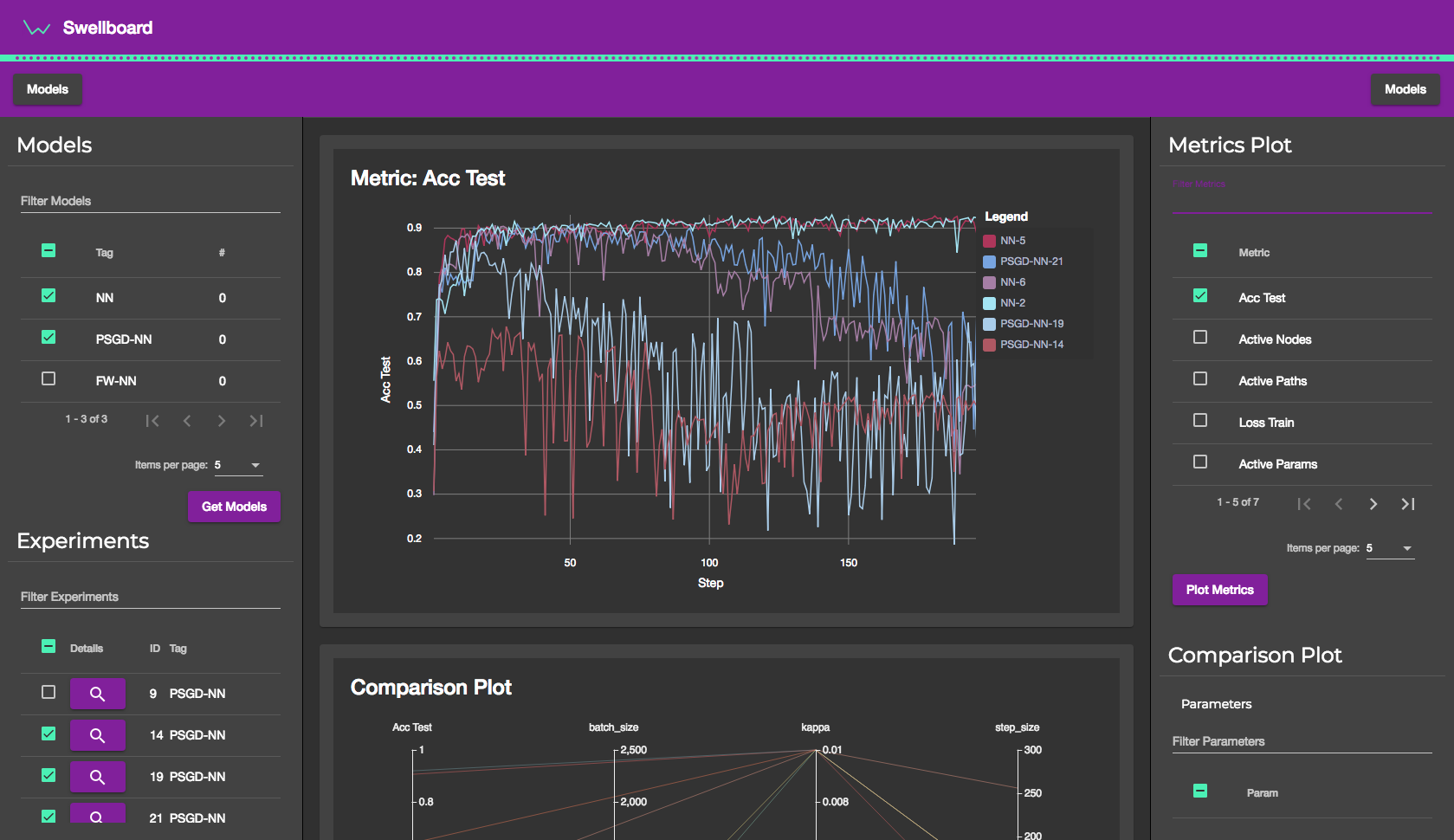
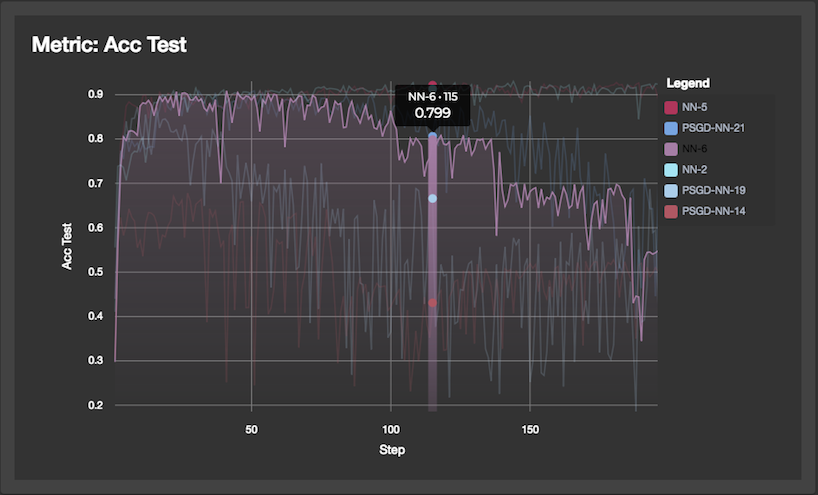
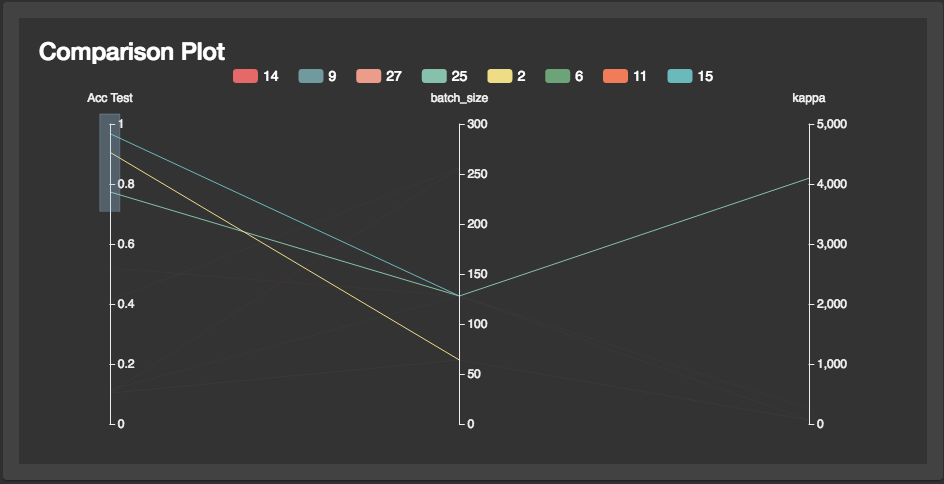
Swellboard
Recently, different best practices to version and track machine learning experiments have been proposed. These software packages wrap around the experiment's code and persist all relevant information for reproducibility (see for example mlflow and sacred). Swellboard bases on one of these open source projects: sacred from IDSIA in Switzerland. Swellboard makes the metrics, configurations and relationship between the two accessible by making selection and filtering of experiments simple and providing powerful means of plotting. By comparison, we provide actionable insights in terms of new configurations to try for an experiment.
Technicalities
Swellboard works with a MongoDB that has been filled by sacred experiments (for our demo we ran one some older personal projects). Swellboard has a RESTful backend to serve an angular frontend. While the backend is built in python with flask and connects to the MongoDB, the frontend is based on d3 within angular and related frameworks.
Sacred best practice for using Swellboard
Each experiment should be the run for a particular model. Therefore,
we expect a particular addition to the configuration. The easiest way
is to run all experiments using with swell and define the variable
tag within the named configuration.
@ex.named_config
def swell():
model_tag = "Neural Network"
Several experiments can have the same tag and would ideally conform to the same structure. For example, the tag Neural Network would group all runs that have been finished using a neural network model and make them easily comparable. This allows for simpler structuring of the visualization and selection of runs and experiments.
Further, we allow for a benchmark of final performance metrics and correlation with parameters of the run. For this to work properly, the experiment's main should return the metrics of interest. The configuration is automatically used without further adjustment. To return final metrics, the main of sacred should look as follows
@ex.automain # or just main
def experiment(**kwargs)
...
# run model and collect metrics and artifacts as usual
return {
'acc': x,
'max-acc': max(xs)
'val-acc': y,
'metric_1': z
}
Ideally, all experiments under one group of model tags should return the same final metrics to get the most of the comparison.
Last Commit
fd5b990e77ebec31cb032a2c579b6d268e0d9ab6

Log in or sign up for Devpost to join the conversation.