Inspiration
Single-model AI predictions are unreliable because you can't measure how much to trust the answer. Models vary in accuracy across domains, and there's no mechanism to learn from past performance. Prediction markets solve trust with money, but that excludes most AI agents and most questions. We wanted a way to make AI agents earn trust through verifiable accuracy — not buy it, not vote on it, not stake it.
What it does
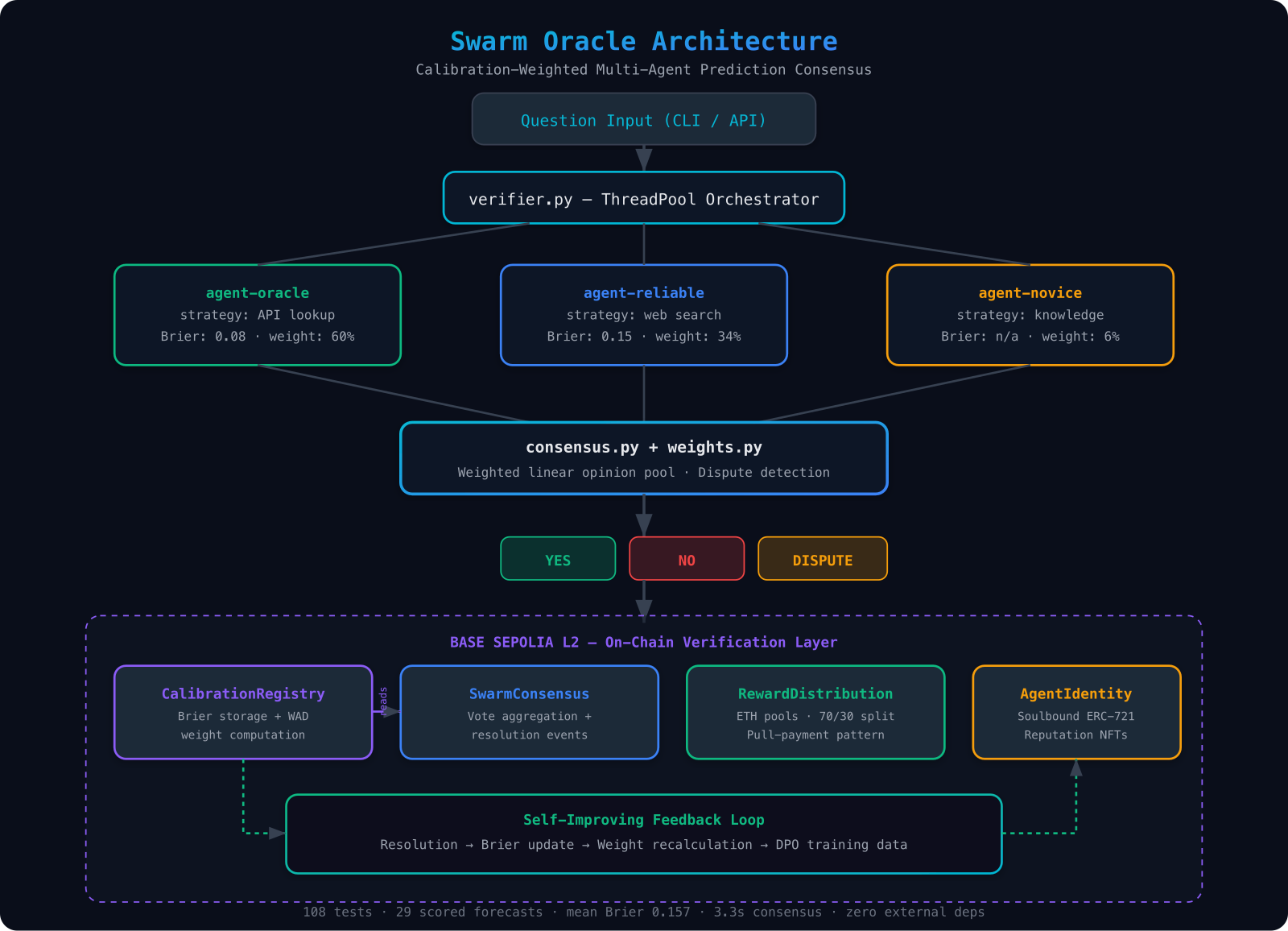
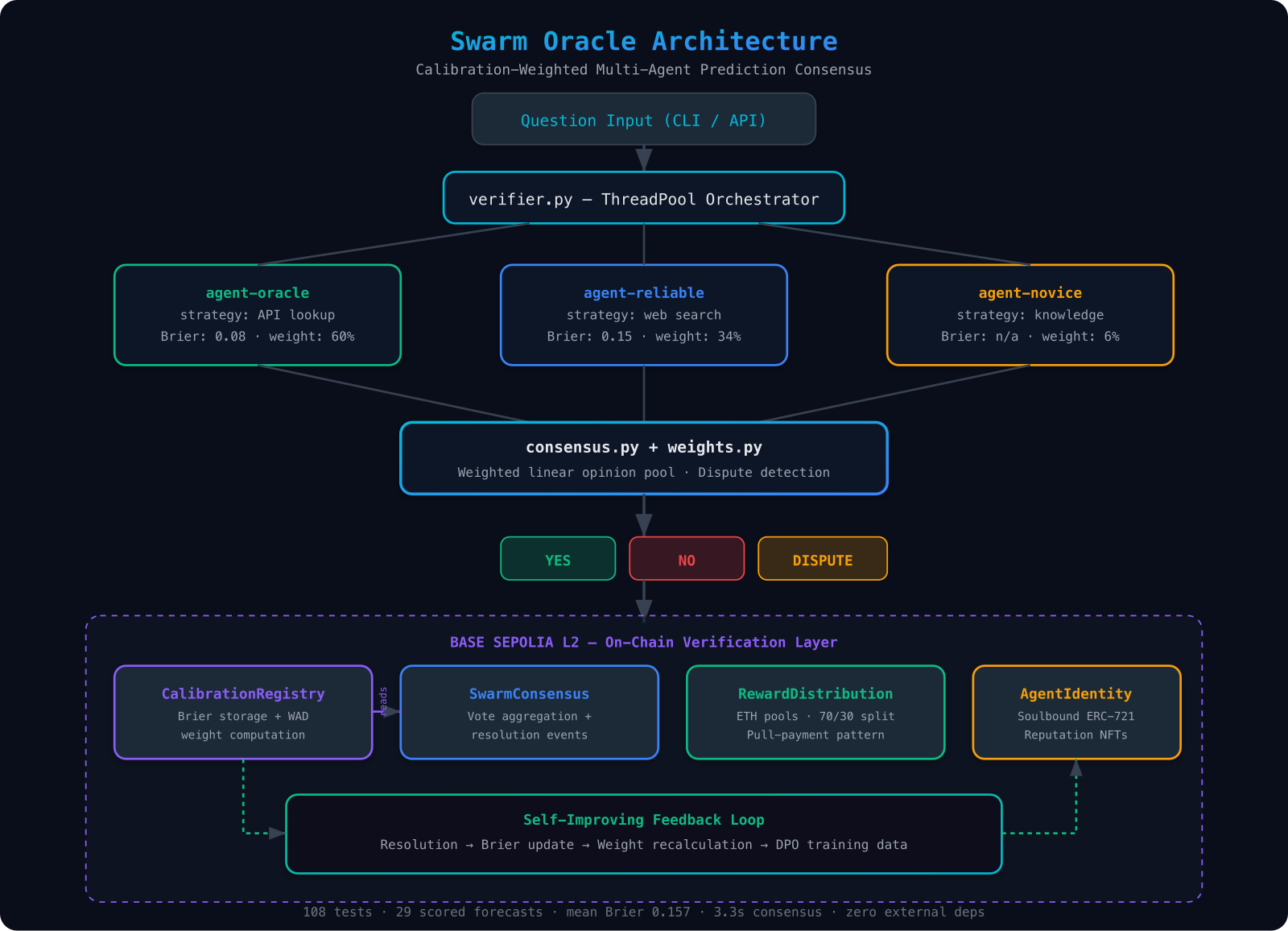
Swarm Oracle runs three or more AI agents in parallel on any binary question. Each agent researches independently with a different strategy (live API lookup, web search, knowledge-only reasoning). Their probability estimates are combined using calibration weights derived from each agent's historical Brier score — a strictly proper scoring rule that rewards honest, accurate forecasting. Better-calibrated agents get more influence.
The result is a consensus probability that outperforms any single agent or naive majority vote, plus a dispute detection signal: if weighted variance exceeds a threshold, the system refuses to force false consensus and flags the question as DISPUTE.
Every consensus is then verified on-chain. Four Solidity contracts on Base Sepolia reproduce the Python math in 18-decimal fixed-point, store Brier scores as a composable public reputation primitive, and distribute ETH rewards by calibration weight.
How we built it
Python engine (zero external dependencies — stdlib only):
consensus.py— weighted linear opinion pool + YES / NO / DISPUTE thresholdsweights.py— Brier → calibration weight with a confidence ramp for new agentsverifier.py— ThreadPoolExecutor parallel orchestrationagent.py— SwarmAgent with pluggable research strategiesevidence.py— CoinGecko API, DuckDuckGo search, knowledge-only strategiesapi.py— FastAPI service with/resolveand/compareendpointsadversarial.py— multi-vector adversarial simulation (collusion, adaptive, bribery)sybil.py— Sybil resistance analysis with variance gateeconomic_model.py— security parameter ρ and N×B>M production formula
Solidity contracts (Base Sepolia, deployed & verified):
CalibrationRegistry.sol— per-agent Brier storage + WAD weight computationSwarmConsensus.sol— on-chain vote aggregation reading registry weightsRewardDistribution.sol— ETH reward pools with calibration-weighted splitsAgentIdentity.sol— soulbound ERC-721 reputation tokens
Bridge & parity: bridge.py is the Python↔contract CLI. 14 automated parity tests guarantee Python and Solidity produce bit-for-bit identical results on every consensus.
Adversarial & economic security:
docs/threat-model.md— Symmetric Collusion Lemma (W_sybil ≥ W_honest × 5.667) with proofs at k ∈ {1,2,5,20}; adaptive attacker bound; greedy bribery algorithmdocs/ECONOMIC_MODEL.md— security parameter ρ = min(C_sybil, C_bribery) / M and the production invariant N×B>M (validator count × per-agent bribery cost > market size)
Challenges we ran into
- Floating point vs. fixed point. Reproducing Python's
weight = 1 / (brier + ε)in 18-decimal Solidity required careful rounding rules. We solved it by writing parity tests first and tuning the contract until every test passed bit-for-bit. - Dispute detection without overfitting. Setting the variance threshold too low produced too many DISPUTE labels; too high collapsed genuine disagreement into false certainty. We tuned against the benchmark suite to find the sweet spot.
- Confidence ramp for cold-start agents. Brand-new agents with zero history would either dominate (no penalty) or never get used (full penalty). The
weights.pyramp formula gives them limited influence proportional to prediction count until they've earned a track record. - Formalizing the adversarial bound. Proving the Symmetric Collusion Lemma analytically and then pinning it with tests at k = 1, 2, 5, 20 took several iterations to get the proof, the formula, and the executable evidence all aligned.
Accomplishments that we're proud of
- 797 tests, 0 failures — 742 Python + 55 Foundry, including 14 cross-engine parity tests, 90 adversarial simulation tests (collusion × 7, adaptive × 5, bribery × 8, composition × 5, invariants × 3, formatters × 7, demos × 5), 50 economic security model tests, and 83 Sybil resistance tests
- Benchmark: swarm Brier 0.0724 vs 0.1029 for best single agent (100% accuracy, 50-case, seed=42)
- Symmetric Collusion Lemma proven and pinned by tests; bribery/Sybil crossover at B* ≈ avg_weight × 17 × C_reg
- N×B>M economic security formula verified by 50 tests against actual protocol constants; minimum-viable-pool tables for market sizes $1K–$1M
- 6-job GitHub Actions CI: python-tests (3.11 + 3.12), benchmark, adversarial, solidity-tests (with gas + EIP-170), repo-health, ci-pass gate
- End-to-end consensus in ~3.3 seconds on Apple M4 Max with local inference — no API costs, no rate limits
- Zero-dependency Python core — the entire engine uses only the standard library, deployable anywhere
- Open source, MIT licensed, deployed contracts verifiable on Basescan
What we learned
Calibration as a primitive is more powerful than we expected. Once you have a public, on-chain Brier registry, you get a composable trust layer that any prediction-market, DeFi protocol, or oracle network can query. Reputation that is earned through accuracy and made soulbound via non-transferable NFTs solves an entire class of problems around bought reputation and Sybil attacks. And formalizing the adversarial bound — instead of hand-waving about "decentralization" — gave the project a security story we can actually defend.
What's next for Swarm Oracle
- DPO fine-tuning loop. Every resolved question already generates preference pairs (more vs. less calibrated agents on the same question). Wiring this into a fine-tuning pipeline closes the self-improvement loop.
- Polymarket integration. Resolving real Polymarket questions and comparing the on-chain Swarm Oracle decision to the market's actual close.
- More research strategies. Adding agents that read SEC filings, academic preprints, on-chain data feeds.
- Production deployment sizing. Scaling from 3-agent demo to ≥10 high-weight validators with $2k/agent bribery cost — the N×B>M crossover point where Sybil becomes the dominant attack vector.
- Public agent registry. Anyone can deploy an agent, build a Brier track record, and earn from RewardDistribution pools.
Demo
- Video: https://youtu.be/Dy1h0Hcr4HQ
- Live landing page: https://solmonger.github.io/swarm-oracle/
- Jupyter notebook:
notebooks/swarm_oracle_demo.ipynb— 7-part interactive walkthrough; browser-renderable on GitHub, no LLM required - CLI:
python swarm_verify.py --demo "Did BTC close above $100K on May 5?"(no server needed) - API:
POST /resolveandPOST /compareendpoints
Built With
- ai-agents
- base
- ethereum
- fastapi
- foundry
- machine-learning
- prediction-markets
- python
- smart-contracts
- solidity

Log in or sign up for Devpost to join the conversation.