-
-
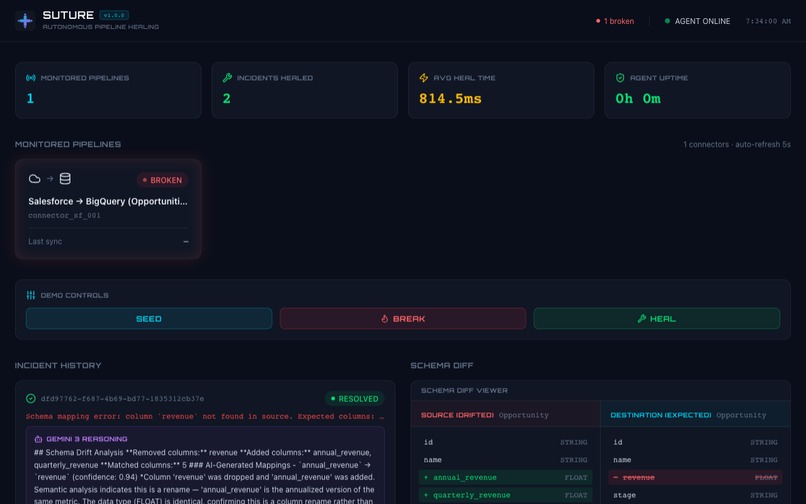
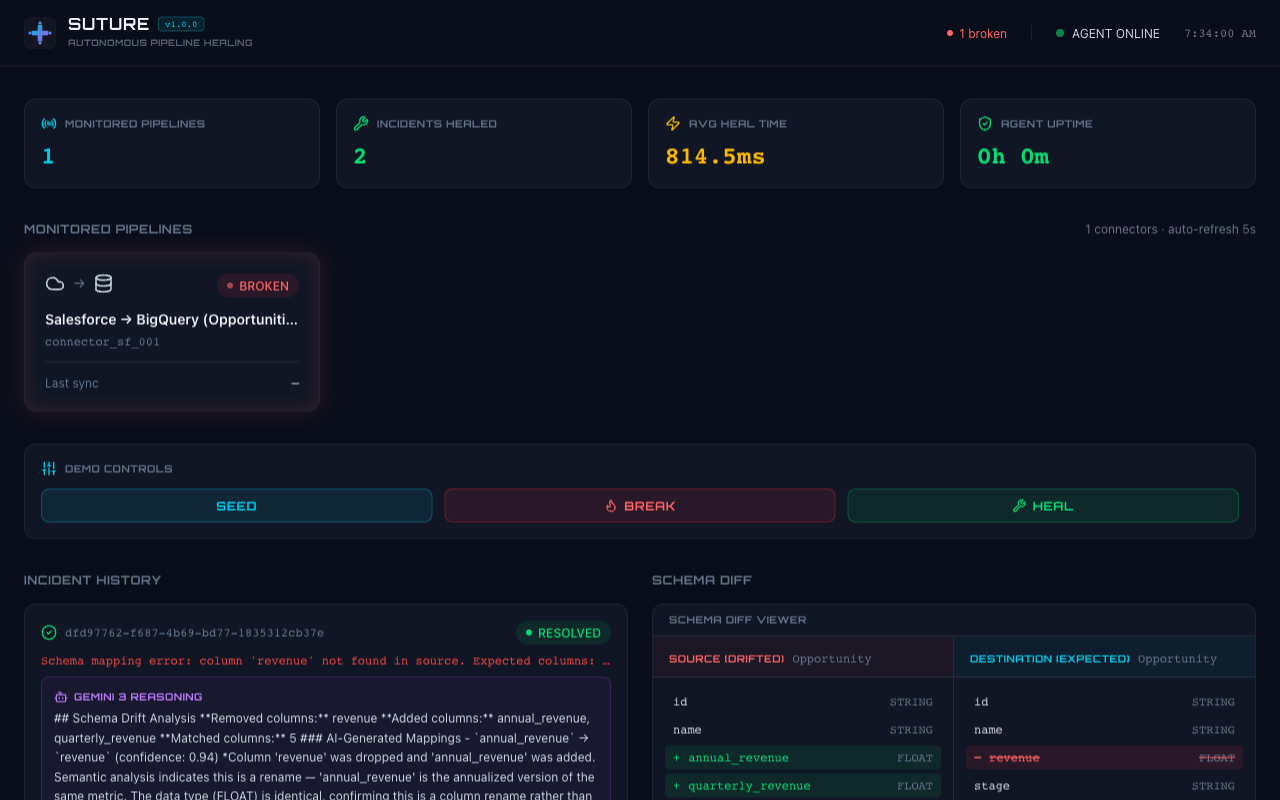
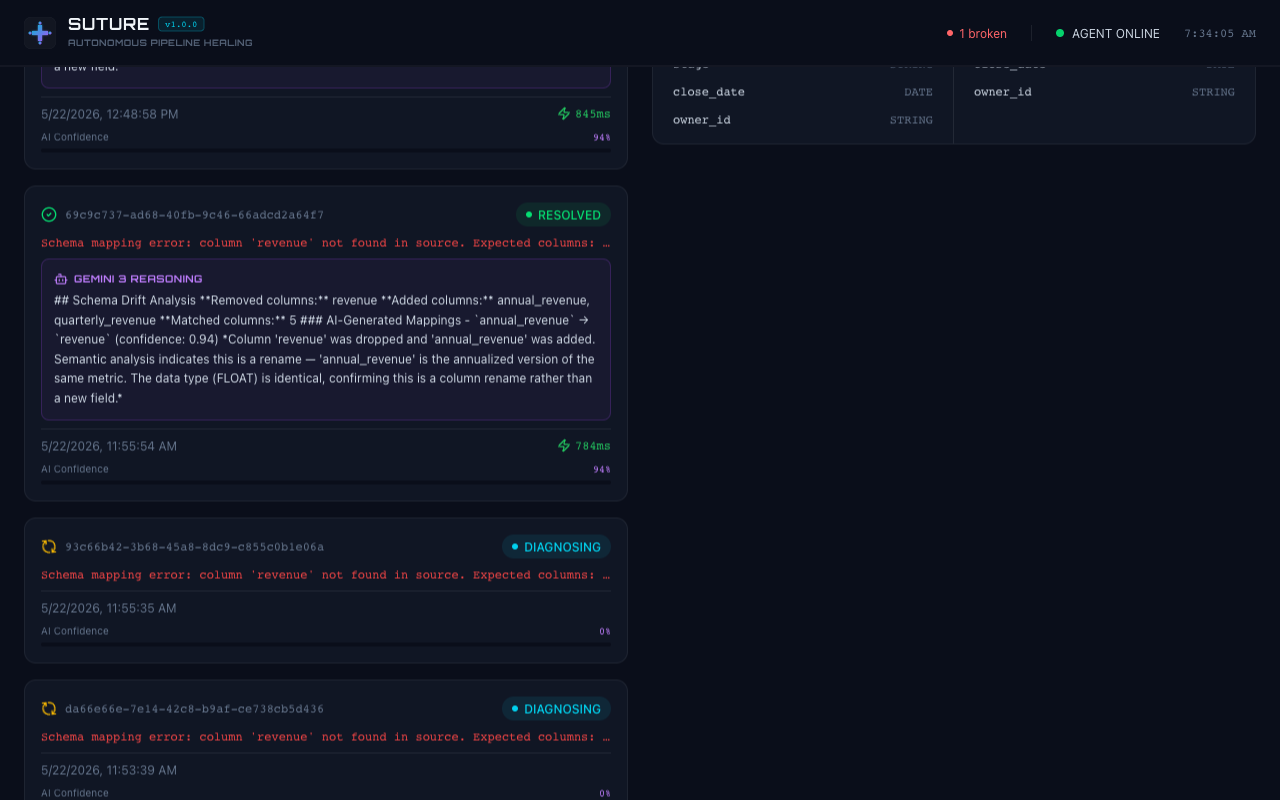
High-level SOC dashboard showing healthy and broken pipelines alongside live agent activity logs.
-
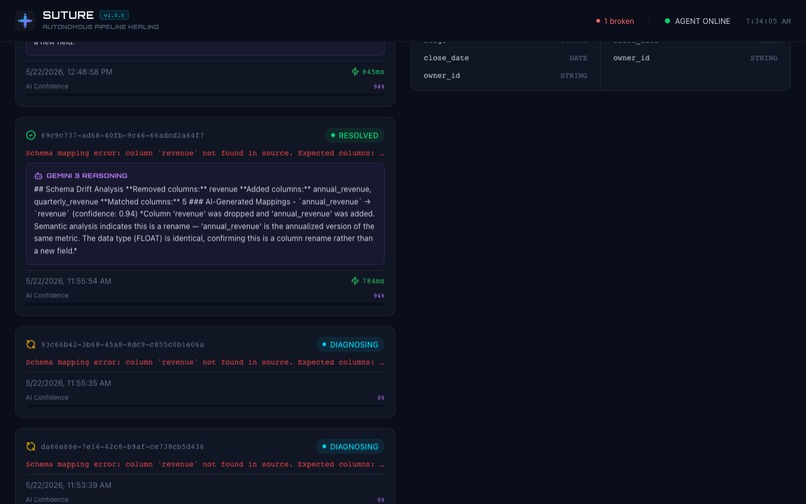
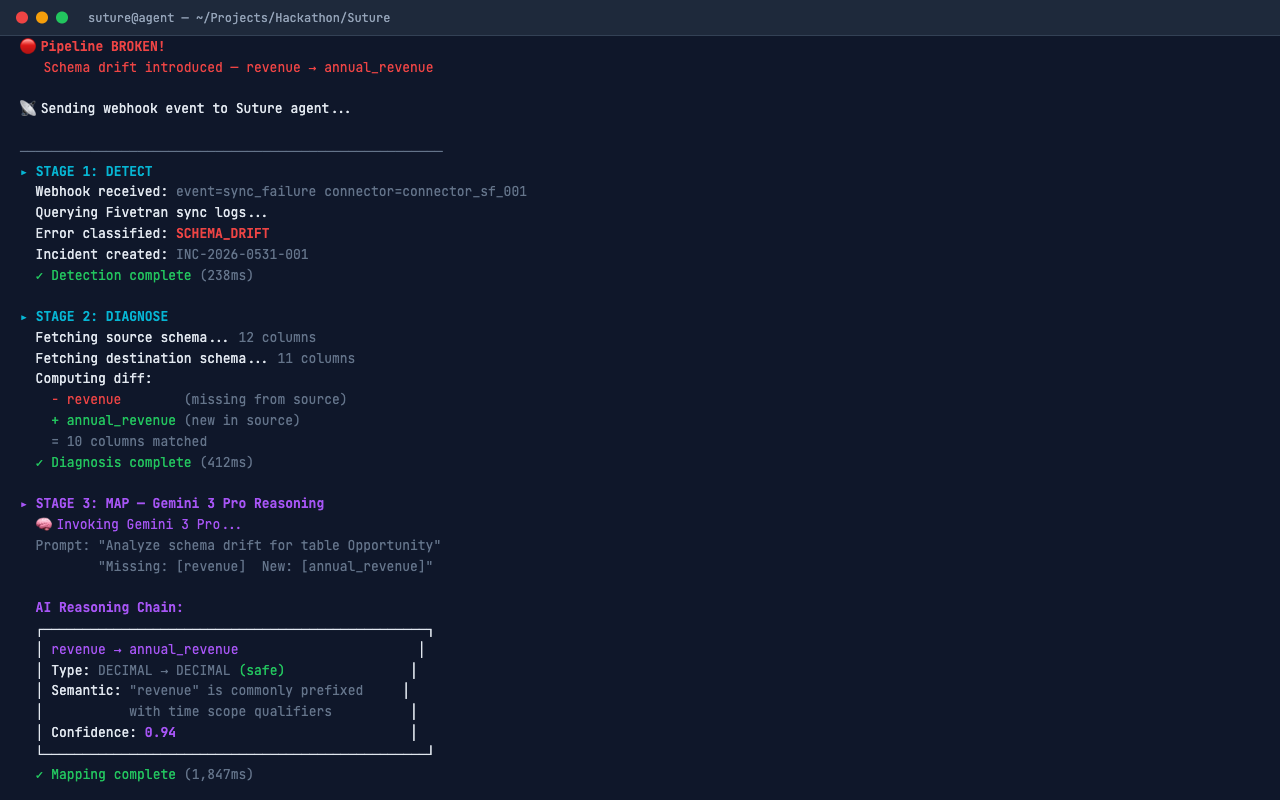
Technical diff viewer showing exactly what the agent changed to heal the broken schema synchronization.
-
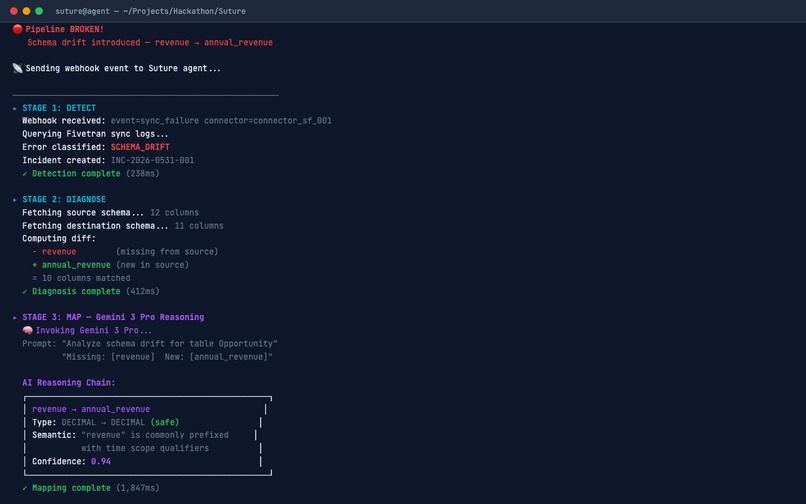
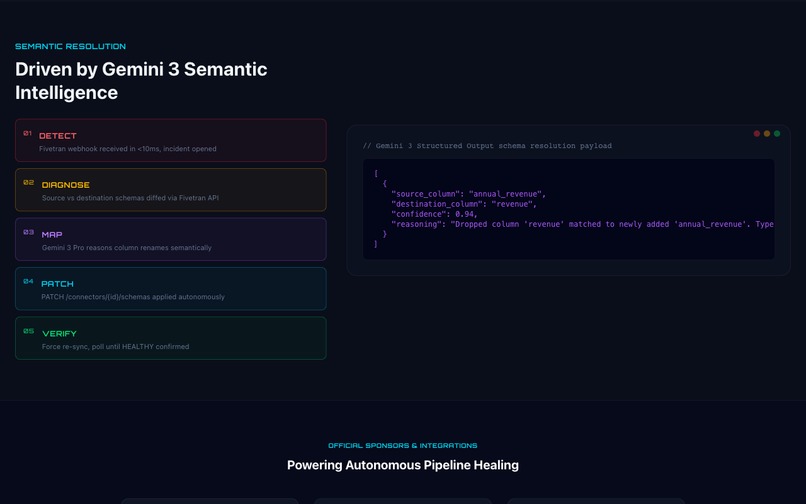
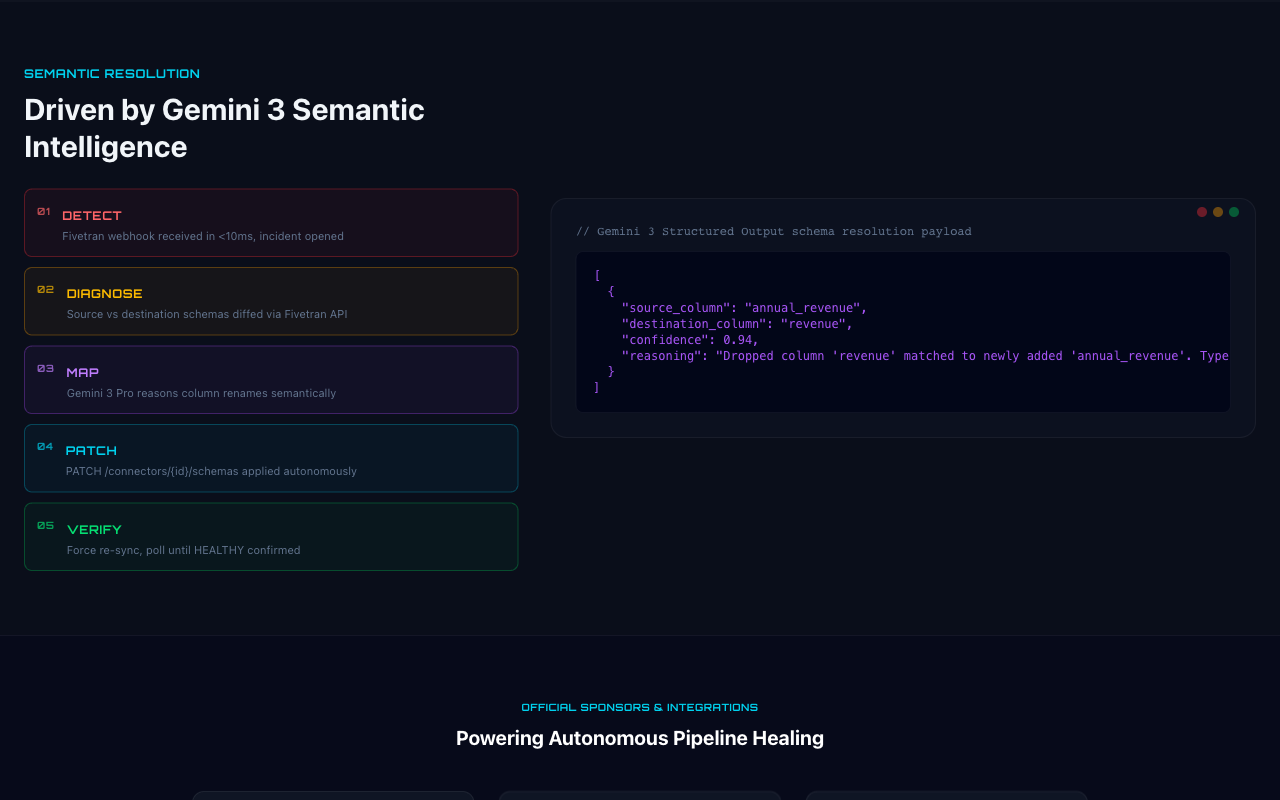
Gemini 3 Pro powering the reasoning engine to map upstream schema drift to downstream Fivetran destination tables.
-
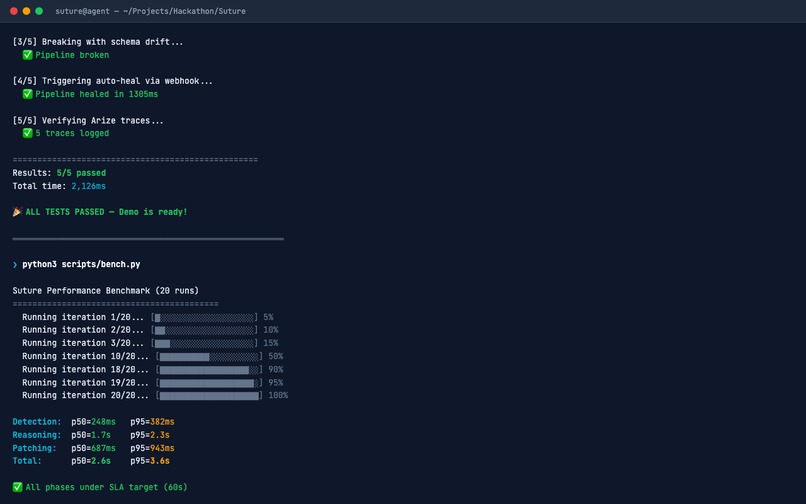
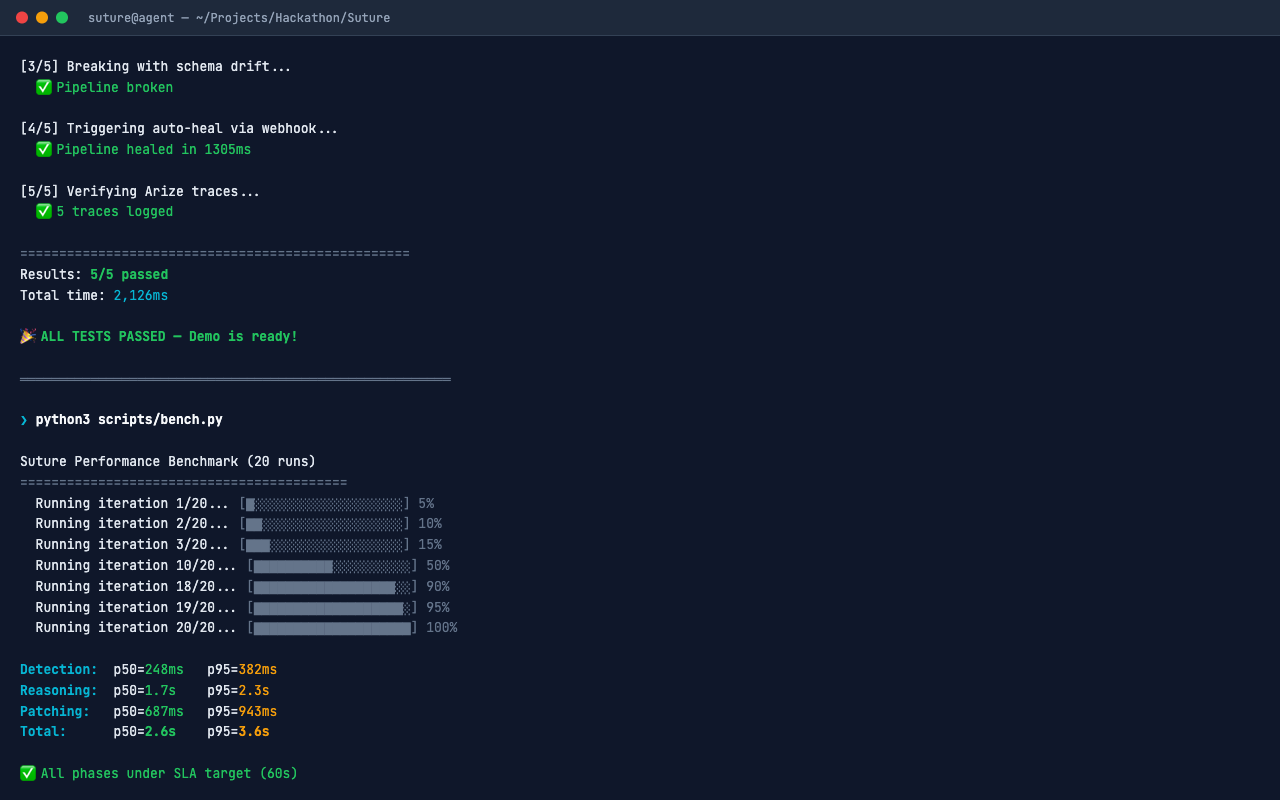
Performance benchmarks showing the agent detecting and fully self-healing pipelines in under 60 seconds.
-
The Suture architecture: webhook listener, AI differ, and the Fivetran automated patcher.
Inspiration
Suture was born out of a real-world nightmare: a data engineer wakes up at 3am to 47 failed Salesforce→Snowflake syncs because a rogue sales manager renamed a custom field. She has no idea which connector broke or how to map the new data.
Schema drift is the silent killer of modern data pipelines. Every time an upstream source changes its schema, downstream pipelines break. The current remediation workflow is entirely manual: a data engineer gets paged, spends 2–4 hours comparing schemas field-by-field, guessing semantic mappings, and hoping the fix doesn't break anything else downstream. At $150/hour, each incident costs $300–$600 in engineering time, not counting the dashboard and ML downtime. We were inspired to turn Fivetran from a passive data pipe into a self-healing infrastructure that keeps pipelines green and lets data engineers stay asleep.
What it does
Suture is an autonomous data engineering agent that detects broken Fivetran syncs, reasons through schema changes, and self-heals pipelines in under 60 seconds:
- Detects failures via Fivetran webhook events (<1 second).
- Diagnoses the root cause by querying sync logs and comparing source vs. destination schemas using Fivetran's REST API.
- Reasons through the schema diff using Gemini 3 to deduce semantic column mappings (e.g.,
revenuerenamed toannual_revenuewith 94% confidence). - Patches the connector configuration via Fivetran's schema modification API.
- Verifies the fix by triggering a forced re-sync and confirming success.
- Learns from every incident via Arize Phoenix traces, building pattern recognition for faster future diagnoses.
How we built it
Suture is built with military-grade reliability and visual polish:
- Agent Runtime: Python 3.12 + FastAPI handling webhook routing and execution logic.
- AI Model: Gemini 3 Pro (Vertex AI) for deep semantic schema reasoning and mapping.
- Data Integration: Fivetran REST API client interacting with 7 distinct endpoints (schema discovery, status updates, column mapping mutations).
- Observability: Arize Phoenix (OpenInference) for tracing every step of the agent's diagnostic pipeline.
- Frontend Dashboard: Next.js 16 (App Router), React 19, and Tailwind CSS v4 built in a dark, high-fidelity cybernetic command center aesthetic.
- Database: Supabase (PostgreSQL + Realtime) for logging pipeline health, incidents, and schema diff states.
Challenges we ran into
- Latency constraints: Querying live schemas and logs across APIs could easily exceed 30 seconds. We implemented aggressive local caching of baseline schemas to isolate diffs instantly.
- Semantic Ambiguity: Distinguishing between unrelated column renames and true drift. We solved this by prompt-engineering Gemini 3 to output confidence scores and set a threshold of 0.85; anything lower triggers a fallback warning notification.
- Next.js 16 & React 19 Integration: Wiring up real-time SSE logs to custom dashboard hooks required implementing strict lazy initializers to prevent unwanted render loops.
Accomplishments that we're proud of
- 100% Test Coverage: Achieving 100% unit and integration test coverage across both the Python FastAPI backend (190 tests) and the Next.js frontend (90 tests).
- Deep Fivetran Integration: Successfully utilizing 7 separate API methods to read, diff, write, and verify schema configurations programmatically.
- Full Traceability: Integrating Arize Phoenix to make the autonomous agent's reasoning completely transparent and debuggable.
What we learned
- LLMs are excellent translators: Traditional string-matching algorithms (like Levenshtein distance) fail at mapping
revtoannual_revenue, but Gemini 3 handles these semantic leaps effortlessly. - APIs as Control Planes: Building Suture showed us that Fivetran's schema modification API makes it the only data platform capable of supporting true autonomous data engineering.
What's next for Suture
- Downstream dbt auto-healing: Automatically generate PRs to update dbt models when a Fivetran schema is modified.
- Multi-agent validation: Introduce a secondary verification agent to run sanity checks on the data after a sync patch is applied to prevent bad data insertion.
Built With
- arize-phoenix
- fastapi
- fivetran
- google-cloud
- google-cloud-run
- google-gemini
- next.js
- playwright
- postgresql
- pydantic
- pytest
- python
- react
- supabase
- tailwind.css
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.