
Inspiration
While coming up with an idea to create for this hackathon, we ran into a new article by Forbes which outlined research being done by the University of Cincinnati to predict crime based off of data from tweet locations. This tool identifies trends in the data to predict which locations are most likely to have criminal behavior. As a group we came up with an idea to use the text in the tweets instead of the location of the tweet. We did some research and found that many crimes, suicides, acts of terror are committed after making posts of their manifestos on social media. So, we decided to create a twitter based tool that identifies a users psychological behavior from their tweets. This would be useful for law enforcement authorities to keep a watch on users that may be of concern.
What it does
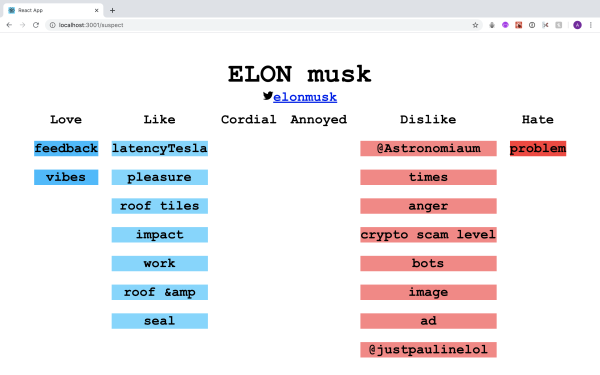
The suspect analysis tool aims to help identify potential criminal behavior of a twitter user based on their twitter posts. This tool is meant to be used as an aid by law enforcement authorities to identify and monitor behavior of potential suspects. Using the natural language processing API from google cloud, we are able to categorize the persons behavior from their posts in six different categories; Love, like, cordial, annoyed, hate, dislike. Based on these categories we can identify a suspects psychological state and generate a report.
How we built it
There were several API's and frameworks that we had to use in order to build this tool. Initially we had to find a way extract the tweets from a twitter users profile using the profile name. This was done using the Twitter API and tweepy library for python. Each tweet made by the user is stored in dictionary that maps the users name to an array of their tweets. This data set was then uploaded to MongoDB where the other frameworks can retrieve the data from. We used MongoDB so that if a twitter user is searched more than once, the tweet data will already be readily available, that way we only need to update the data for each user rather than researching their twitter feed.
Challenges we ran into
The challenges we ran into included deploying a flask web server on a Linux VM, which we overcame by using the Google App Engine. Other challenges included: connecting our React Front End with a MongoDB back-end with an NLP library. This required us to experiment with different sentiment analysis tools, ranging from Google NLP services to IBM Watson. The configurations required to tailor our inputs across various platforms and while scraping the twitter API required us to experiment with it.
Accomplishments that we're proud of
We are proud of our final project, because it is functioning as designed. When this hackathon started we didn't know each other so were also able create new connections during this hackcthon. While working together we got to know each other strengths and weaknesses so, split the work based on which technologies each person knew. As a result of that we were able to efficiently work together to create out final project.
What we learned
Prior to this hackathon we weren't familiar with the technologies that were required to make a working model for our idea. So, in order to continue with our idea, we attended the workshops for React and Framework for Tackling AI/ML Challenges. We also watched tutorials to learn about how to integrate google cloud platform with MongoDB, Twitter API, Flask and React. Overall, every group member will be leaving this hackathon with a new skill set under their belt!
What's next for Suspect Analysis
In the future, Suspect Analysis can be used by law enforcement agencies to track suspects that may pose a possible threat. We would also like to use other social media platforms such as Reddit, Facbook, Youtube etc. to get a larger data set. Aside from using this tool for identifying suspects, this can be used in a professional work environment to analyze potential candidates for a job to get an idea of whether or not they are fit psychologically for the working environment of the company.

Log in or sign up for Devpost to join the conversation.