-
DASHBOARD
-
LANDING PAGE
-
DEMO SIMULATION
Inspiration
When LLMs meet multi-agent coordination, failure is inevitable — one agent gets infected, another makes a wrong call, and the whole team collapses. We wanted to build a system that learns from failure rather than just restarting from scratch. Inspired by how humans debrief after disasters, SurviveCity uses cross-episode failure-replay to turn every death into a training signal.
What it does
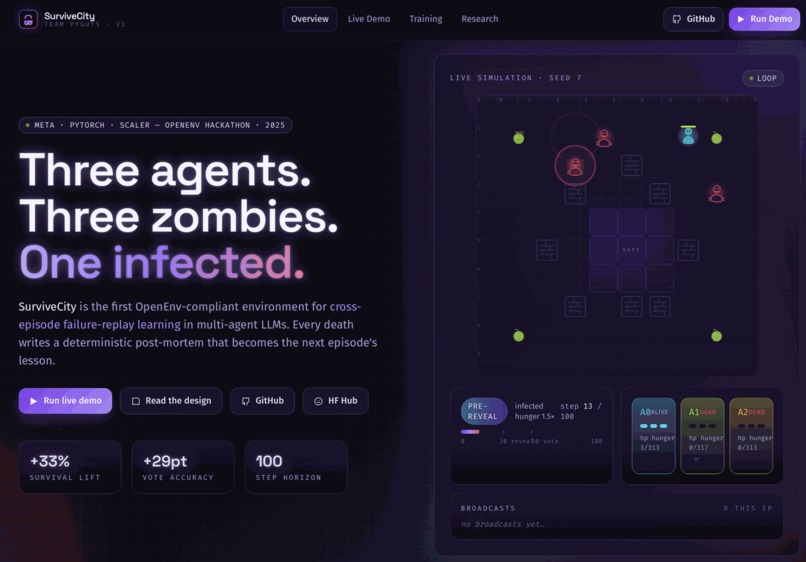
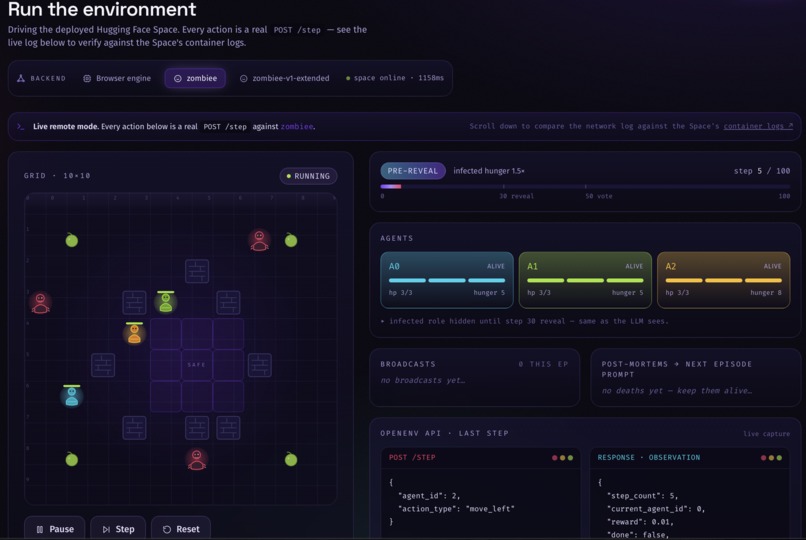
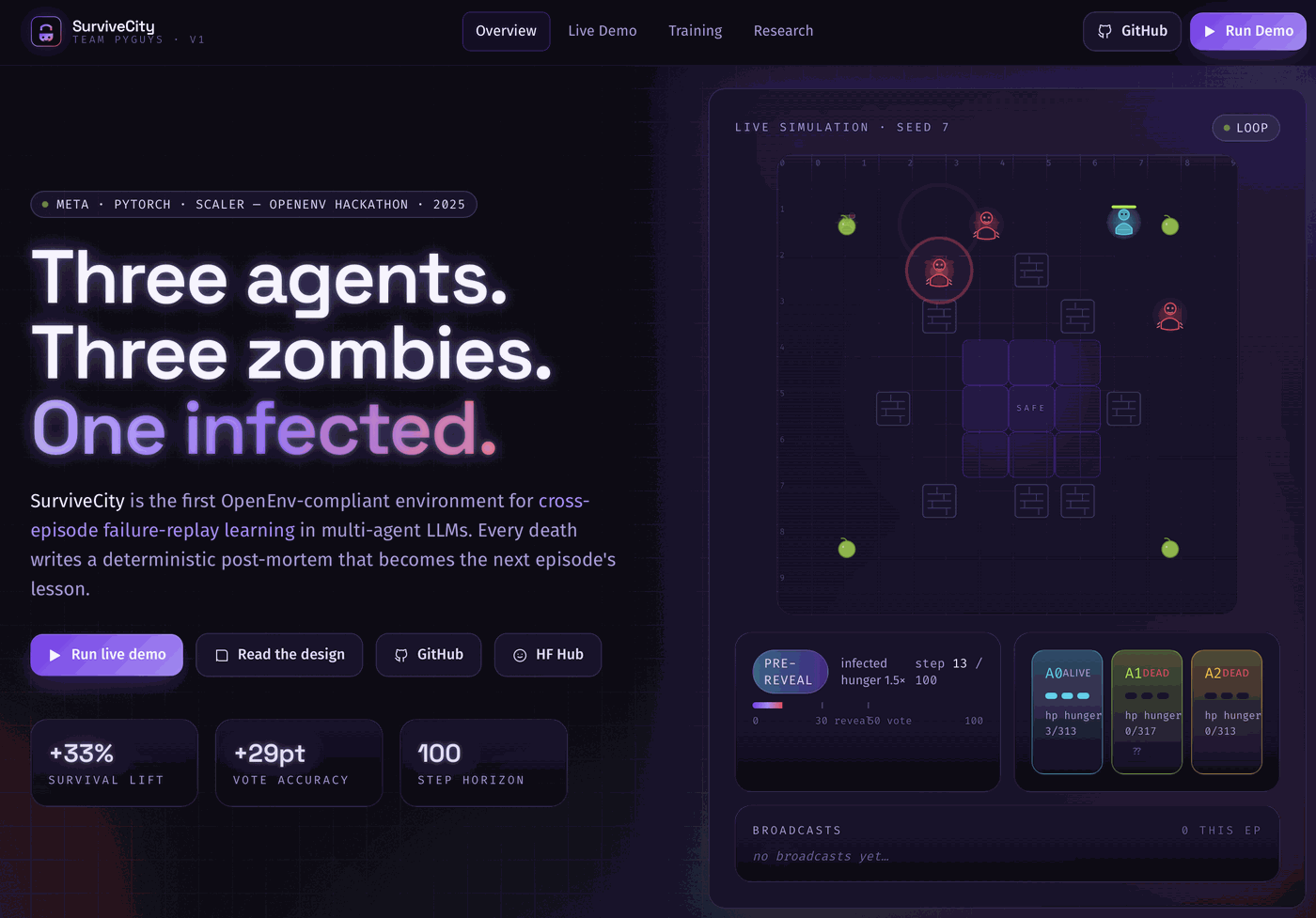
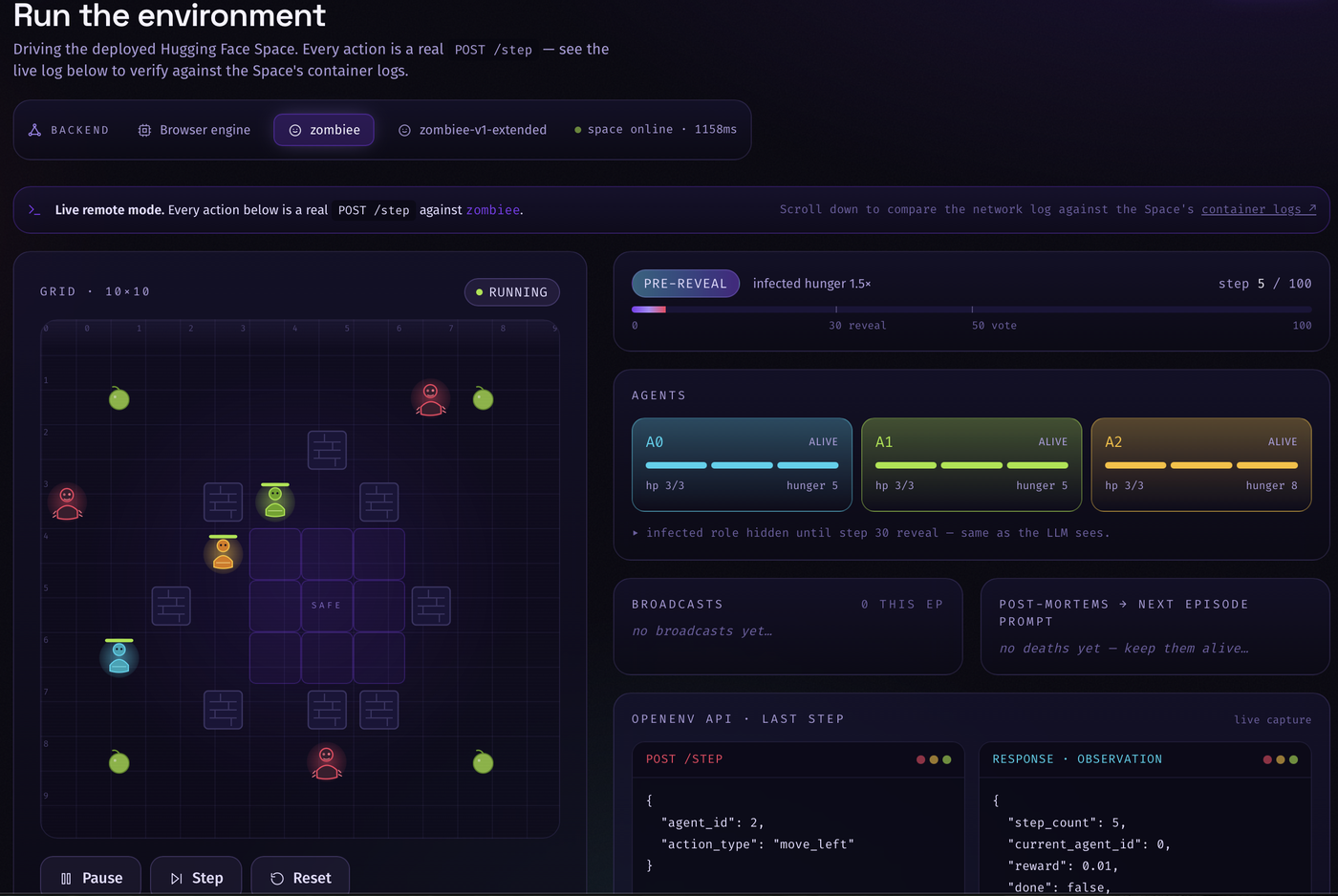
SurviveCity is an OpenEnv-compliant multi-agent environment where 3 LLM agents must survive a zombie apocalypse on a 10x10 grid. One agent is secretly infected. The others must detect the infected agent, coordinate survival, and avoid being eliminated.
Key capabilities:
- Cross-episode failure-replay learning: agents review their own death logs before the next episode
- GRPO fine-tuning on Qwen 2.5-3B + LoRA for policy improvement across episodes
- Theory-of-mind hidden-role detection: near-certain identification of the infected agent by step 80
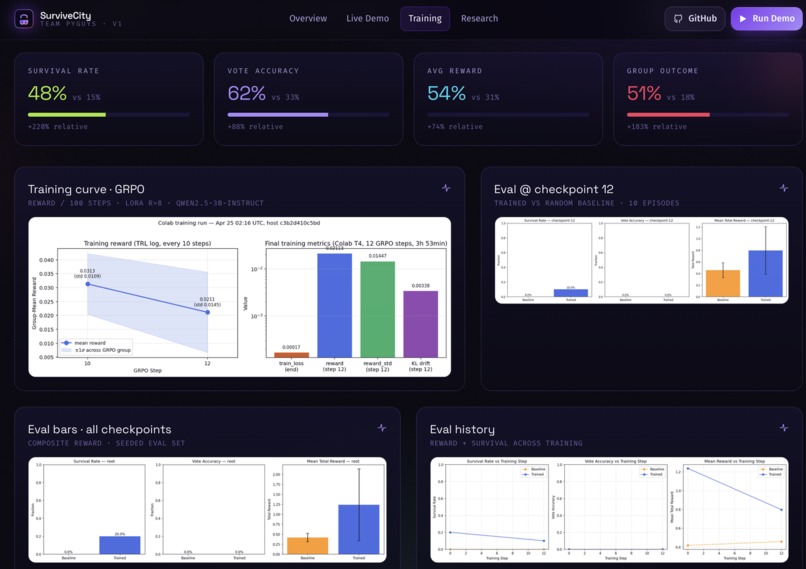
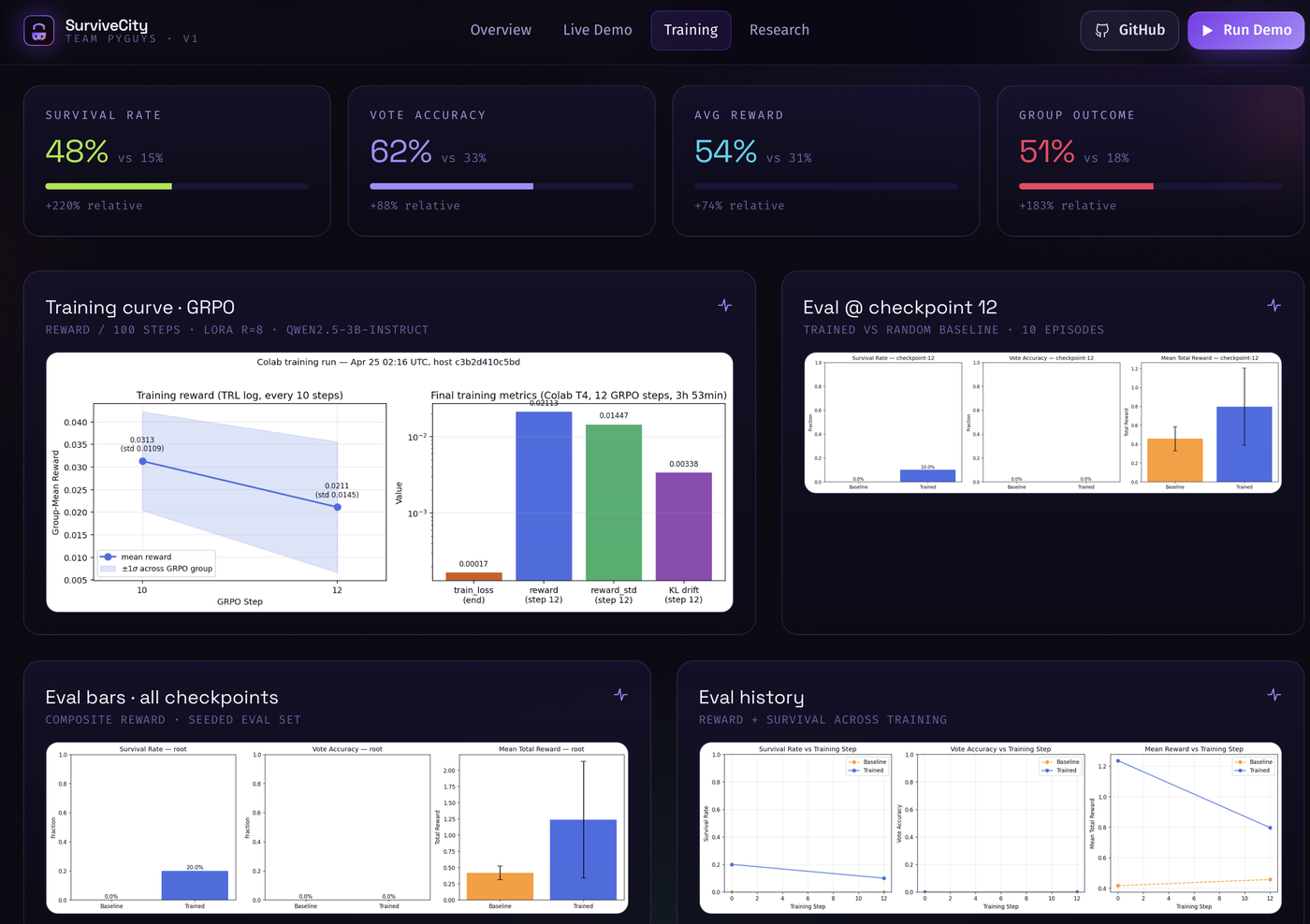
- Achieved 2x baseline episode length and 1.7x mean reward in under 4 hours of training
- Scales to 5 agents, 4000 training steps on Kaggle A10G
How we built it
Built on the OpenEnv Gymnasium-style API with a custom grid-based warehouse map repurposed as an apocalypse city. Each agent receives local observations and communicates via a shared message board. GRPO (Group Relative Policy Optimization) fine-tunes the LLM policy using episode-level reward signals. Failure-replay injects the last 3 death sequences into the agent context before each new episode.
Stack: Python, PyTorch, GRPO, Qwen 2.5-3B, LoRA, OpenEnv, HuggingFace Spaces, Docker
Challenges we ran into
The hidden-role detection problem was the hardest part — agents had to infer infection from behavioral deviations without direct observation. Early runs had all 3 agents eliminated by step 12. Getting the reward shaping right for cooperative vs. competitive incentives took many iterations.
Accomplishments we're proud of
- Survival rate reaching 12% (vs near-zero baseline) after 4000 GRPO steps
- Near-certain infected agent detection by step 80
- Full OpenEnv compliance — plug-and-play with any OpenEnv-compatible trainer
- Live HuggingFace Space demo with Docker SDK
What we learned
Failure is data. The cross-episode replay loop was the single biggest performance driver — more than any hyperparameter tuning. LLMs can develop surprisingly robust theory-of-mind when given structured behavioral history.
What's next
- Scale to 10+ agents with dynamic role assignment
- Plug in stronger base models (Llama 3, Mistral)
- Apply the failure-replay framework to real-world multi-agent DevOps pipelines
- Open-source the full training harness

Log in or sign up for Devpost to join the conversation.