-
-

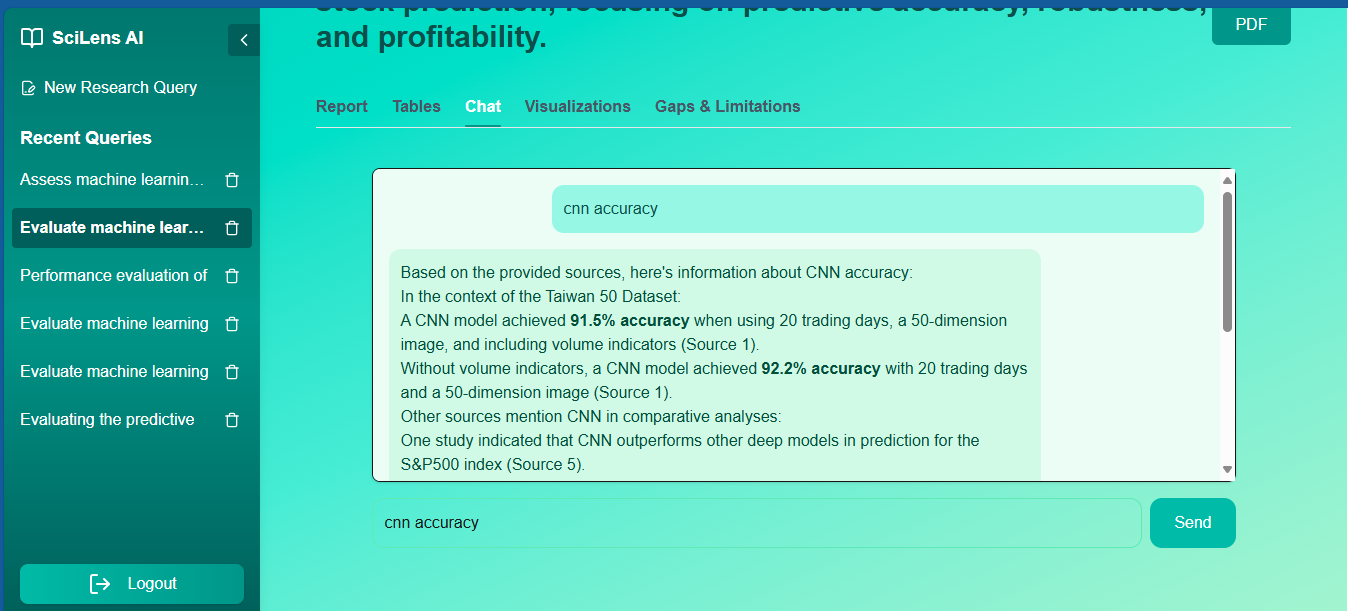
SciLens ChatBot
-
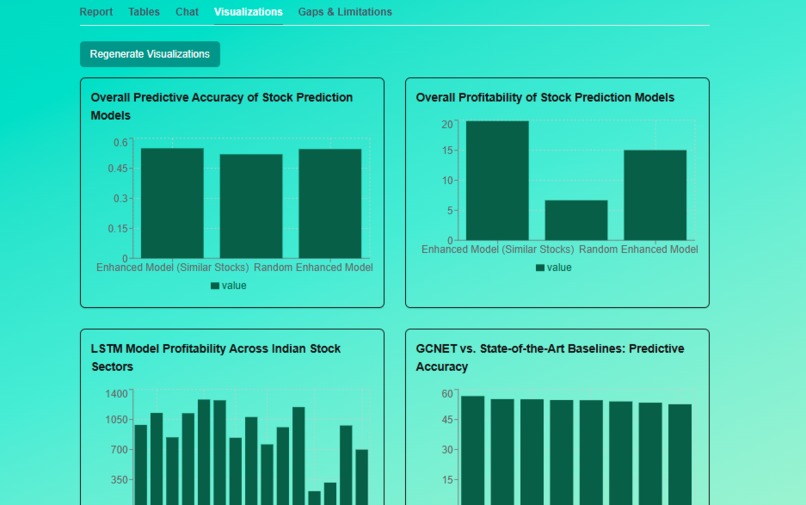
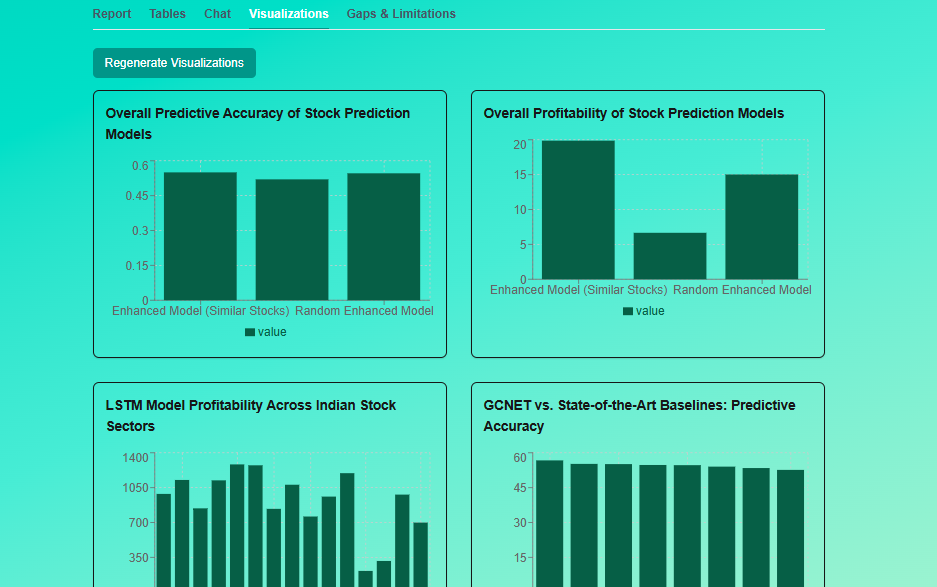
SciLens Visulaization for Quantitative Information
-

SciLens Automated Report Summary

🚀 SciLens Project Story
🌱 Inspiration
The spark for SciLens came from a painful but eye-opening classroom moment.
Our lecturer once gave us a task: “Research AI for stock prediction and prepare a short report.” We scrambled to gather papers, but quickly hit walls:
- We couldn’t extract relevant performance evaluations (like CNN vs LSTM accuracy).
- We didn’t structure findings into clear sections.
- And worst of all — we forgot to cite sources properly.
Our lecturer wasn’t impressed and threatened to give us a zero.
That moment made us realize the true challenge of research isn’t just finding papers — it’s turning them into structured, explainable insights with reliable citations. That’s when we imagined SciLens:
An AI assistant that transforms overwhelming research into clarity, powered by TiDB’s serverless intelligence.
📖 What it does
SciLensAI is an AI-powered research companion that:
- Fetches and analyzes research papers.
- Generates structured reports with Introduction, Key Findings, and Conclusion.
- Builds comparison tables (e.g., CRISPR vs RNAi).
- Extracts numbers to create automatic visualizations.
- Provides a chatbot with RAG (Retrieval-Augmented Generation) that cites real sources.
All of this is backed by TiDB Cloud Serverless, which acts as the memory backbone: storing embeddings, retrieving relevant context, and ensuring scalability.
🛠️ How we built it
- Document Ingestion
- Upload PDFs, Word, or PowerPoint files.
- Extract and chunk text.
- Generate embeddings using Gemini models.
- Store embeddings in TiDB’s vector store.
- Hybrid Search
- Combine semantic vector search + keyword search.
- Ensures results are accurate and context-rich.
- Report Generation
- AI agent retrieves relevant chunks.
- Outputs structured Markdown with inline citations and references.
- Advanced Features
- Comparison tables with pros/cons.
- Automatic plots from extracted numbers.
- Frontend
- Built in Next.js + TailwindCSS with teal/emerald theme.
- Google OAuth for secure sign-in.
⚡ Challenges we ran into
- Scaling embeddings and keeping retrieval queries fast in TiDB.
- Enforcing structured AI outputs instead of freeform hallucinations.
- Extracting tables and numerical values cleanly from unstructured text.
- Balancing time between backend innovation and frontend polish.
🏆 Accomplishments that we’re proud of
- Turning a frustrating classroom failure into a fully working research platform.
- Seamlessly integrating TiDB Cloud Serverless as both a vector store and a scalable knowledge engine.
- Delivering features beyond simple search: structured reports, visualizations, tables, and RAG-powered chat.
📚 What we learned
- How RAG + vector databases fundamentally change the reliability of AI assistants.
- Why citations and references are non-negotiable in research contexts.
- That TiDB’s hybrid transactional + analytical engine makes it ideal as both a memory layer and a retrieval engine.
- The value of building modular AI pipelines: ingestion → organization → generation → explanation.
🔮 What’s next for SciLens
We’re just scratching the surface. Next, we want to:
- Support image and figure extraction from PDFs.
- Enable table parsing for more structured data retrieval.
- Scale up to handle massive paper collections.
- Add richer embedding and retrieval pipelines for multimodal inputs.
- Expand visualization features — turning research into charts, graphs, and networks automatically.
And through all of this, TiDB Cloud Serverless remains at the core — giving us scalable storage, fast vector search, and the reliability to keep pushing boundaries.
🌟 Conclusion
SciLens transforms research chaos into structured clarity. With TiDB as its backbone, we built not just a tool — but a workflow for the future of learning and discovery.
What started as a near-zero grade turned into a vision:
Helping students and researchers save time, stay accurate, and unlock deeper insights — with AI + TiDB powering every step.

Log in or sign up for Devpost to join the conversation.