-
-

Query Tool for powerful navigation of datasets
-

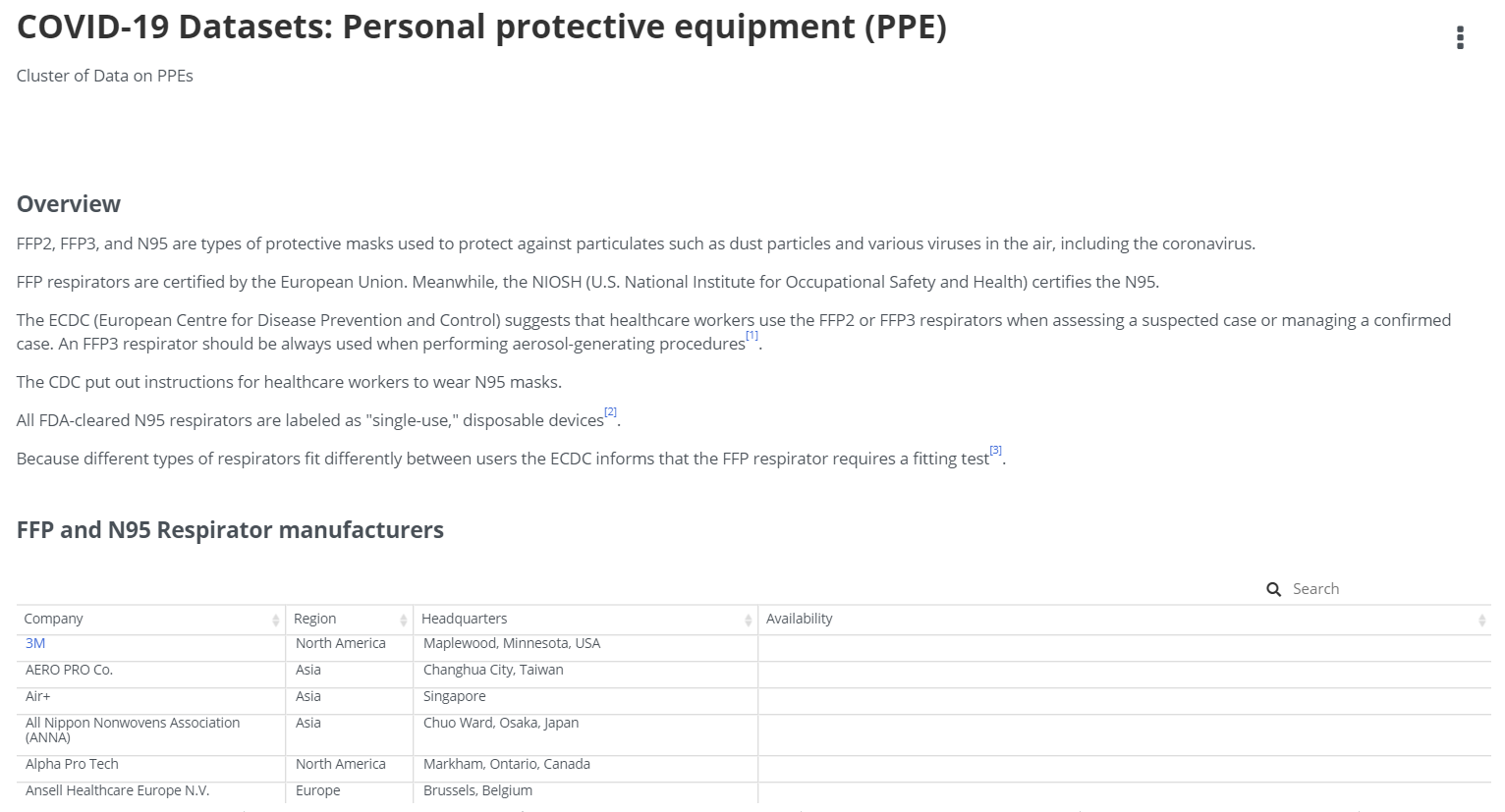
PPE data cluster -- aggregated from multiple resources and availability verified at the source (supplier website)
-

Availability verified from source


UNITING A FRACTURED INFORMATION LANDSCAPE
How are we staying up to date with COVID-19: Reliable information in times of disruption
Right now, accurate, up-to-date, and reliable supply chain information is absolutely essential but also difficult to obtain, organize, and maintain.
We are creating a research platform for COVID-19. We build AI models that help humans collect, organize, and maintain knowledge bases on supply chain.
OUR USERS: KNOWLEDGE-WORKERS
Our users need to find, integrate, and share supply chain information. They are both humans, and robots (APIs).
They have an interest as part of non-profit organizations, hospitals, health care, life sciences, biotech, and manufacturing.
THE PROBLEM
Imagine that you need to find the manufacturers of PPE in Europe.
How many sources would you need to go through, how many types of formats will you need to work with, and once that information is collected, how quickly will it be out-of-date?
OUR SOLUTION
Our solution is a COVID-19 insight platform that combines a search engine, a knowledge management tool, and smart alerts.
We make it easy to organize research of such information into living documents that collectively become a knowledge database available for public use.
WHAT DOES IT DO
It collects information from a wide array of sources, including news, spreadsheets, supplier databases, supplier websites. It processes free form text, as well as structured data for use in our smart editors.
And finally, we use AI to tag information that is incorrect, inconsistent, or outdated to aid in projects such as effective database maintenance.
• Analyze news, databases, and websites
• Transform the research of supply chain information into living documents and databases
• Share the results of your work
• Set smart alerts for when new data is available
AFTER THE CRISIS
We aim at developing a commercially viable solution that will fit particularly knowledge intensive sectors such as medical research, pharma and CRO (Contract Research Organizations):
AI Discovery
Make insights more easily discoverable: uncover hidden knowledge from your unstructured data stored in your Data Management Systems. Leverage AI to analyze signals from the internet
Automatically process signals from the web to signals related to drug safety (Pharma)
Market Intelligence
Monitor your competition. Analyze R&D activity, product launches, filed patents, news mentions, sentiment, etc. Discover and follow startups and their advancements for business development and M&A.
Knowledge Management
Foster better collaboration and information reuse. Enable knowledge sharing through the implementation of F.A.I.R. data principles.
WHAT DID WE DO DURING THIS WEEKEND
• Gathered feedback from specialists on needs for medical supplies
• Prioritized top data-points of interest for analysis
• Laid out the basis for a model that can extract insights on supply-chain from unstructured data
• Launched the following version 1 of our PPE dataset: https://doqume.com/articles/7237-D
WHAT DO WE NEED TO CONTINUE
Servers: 10000 USD/year will cover computational costs Employees:
○ Two AI-focused developers
○ One front-end developer
○ Product manager/sales/marketing
○ Community manager and scientist
60 thousand Euros will allow us to move forward for four months to complete the steps below.
NEXT STEPS
Milestone #1. May 2020: we aim at building an AI that identifies from the website of suppliers whether they accept orders or not.
Milestone #2: June 2020.
• We aim at covering all supplies relevant to the European market so that our engine could cut by more than half the time medical professionals and institutions spend on researching key suppliers. We want to give back time to both sides of supply and demand. Ideally, if organizations in need of medical supply search, aggregate and maintain that data, we want them to achieve the same results with a fraction of that time.
• Open access through an API for external parties.
• Open community access for suppliers and collaborators to contribute to updating or adding supplier data.
Milestone #3. June through August 2020: bring onboard over 200 separate organizations using and sharing our data and insights. We want to save those teams collectively beyond 30,000 hours of research work.




Log in or sign up for Devpost to join the conversation.