-
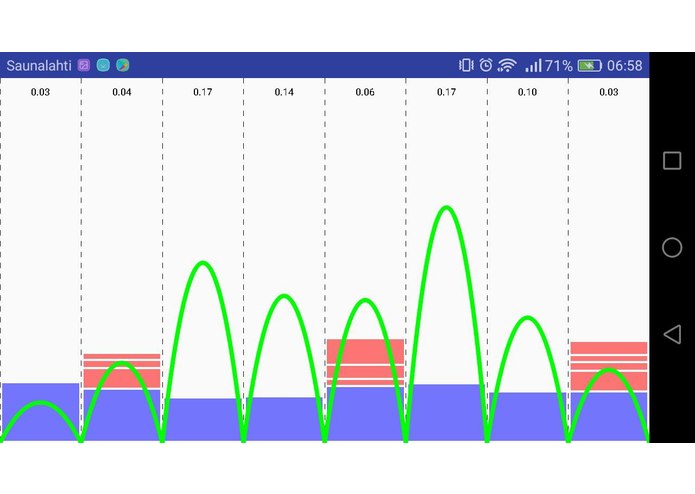
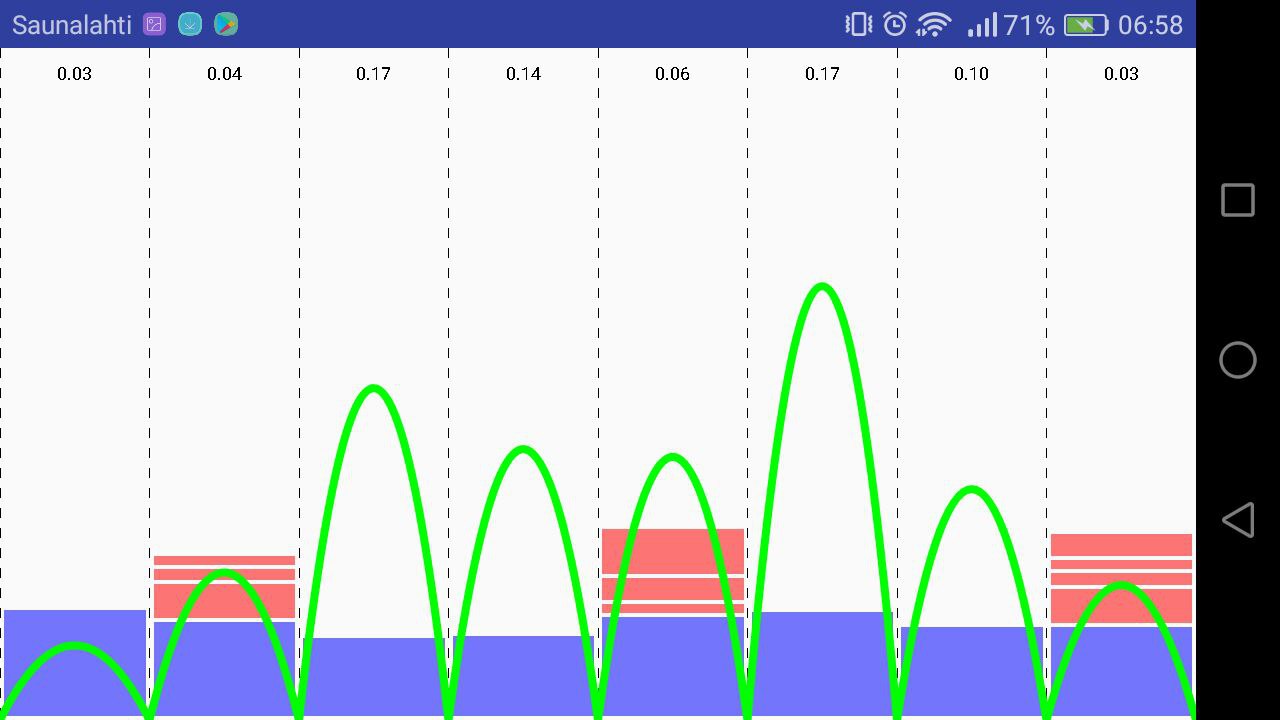
user_interface
-
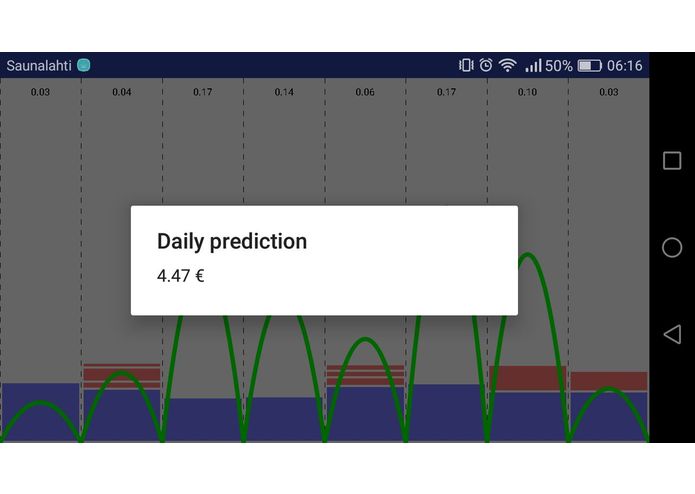
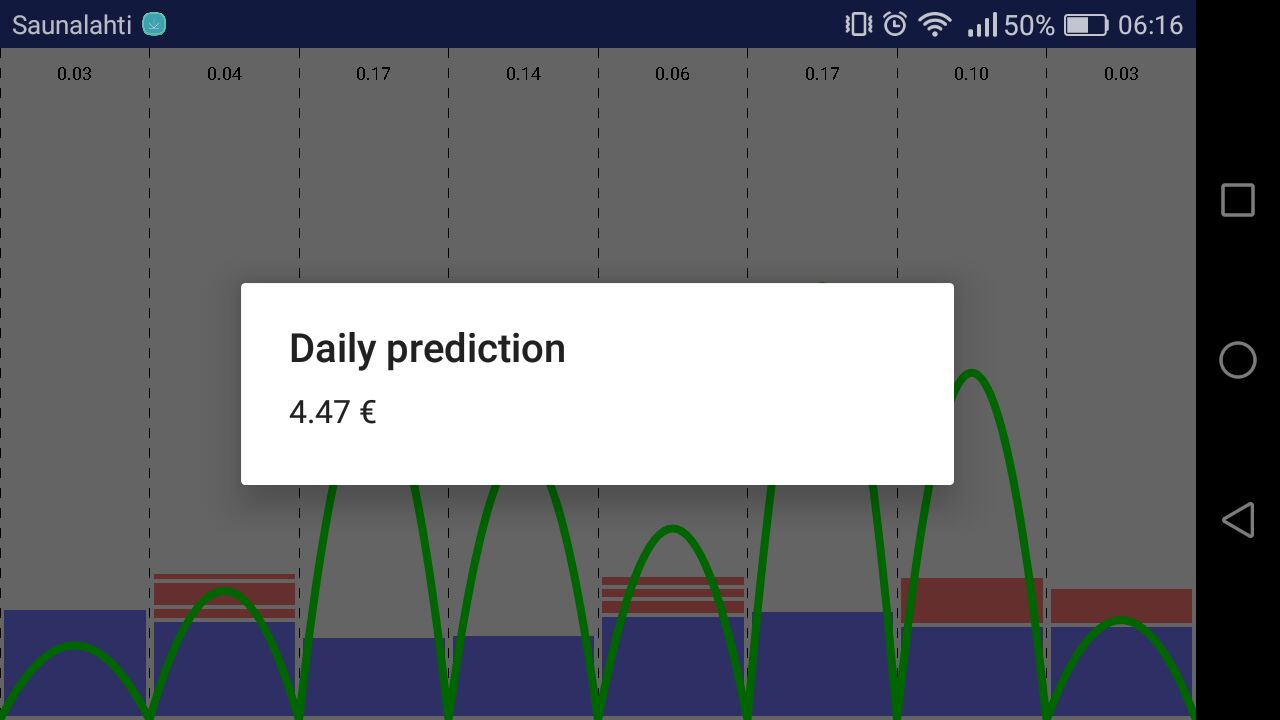
energy_bill_assumption
-
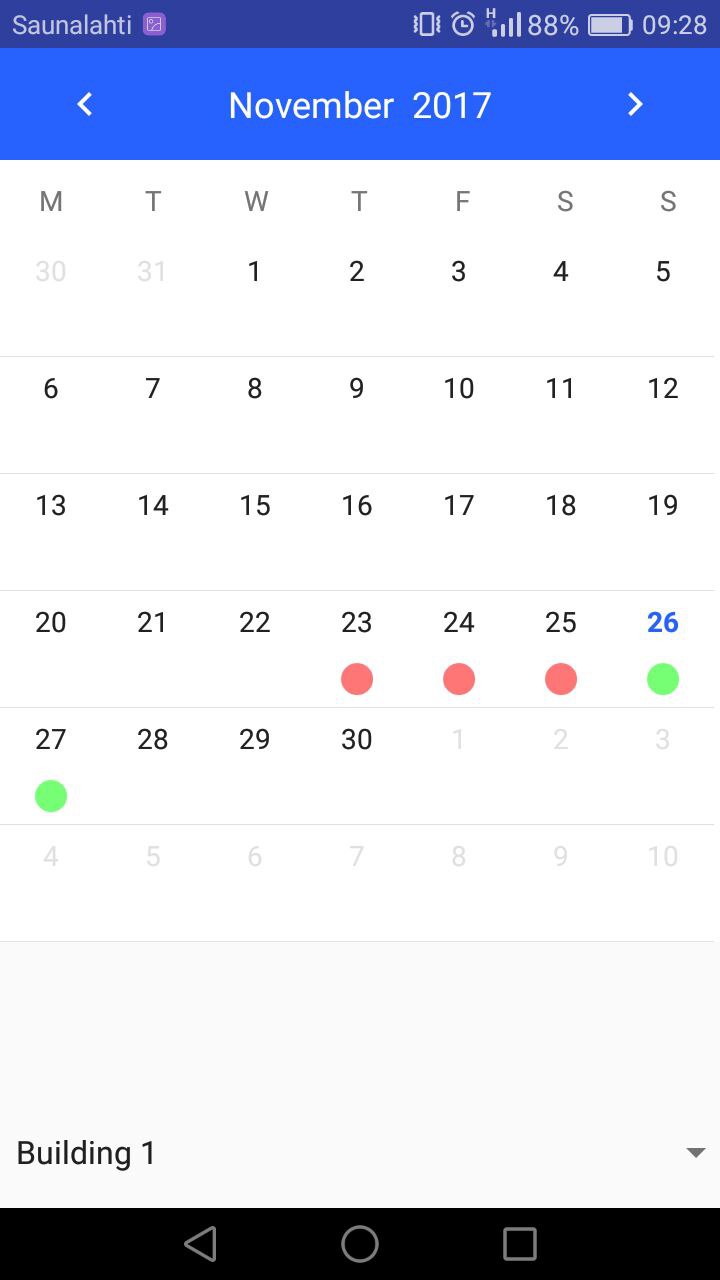
date_building_selection
-
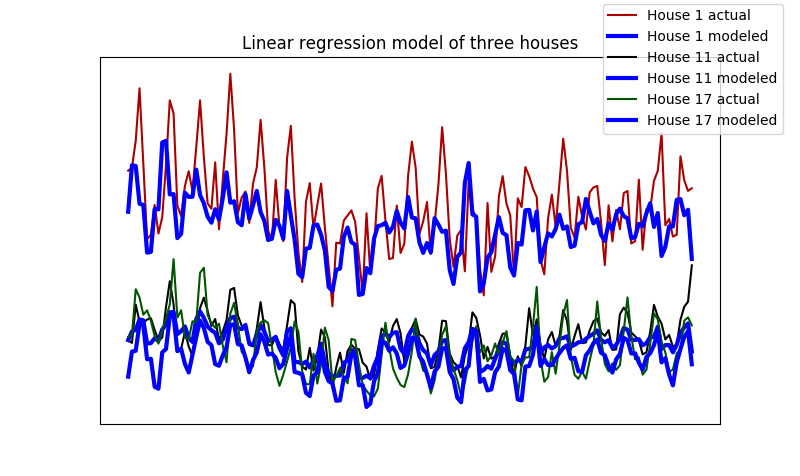
regression_data
About us:
Team members: Semen Uimonen, Alexander Fedulin, Andrey Khitryy, Toni Tukia, Petri Jantunen
We are a group of engineers with backgrounds in electrical engineering and automation and applied mathematics and computer science.
Introduction:
We chose the intelligent buildings track and smart electricity challenge.We decided to think outside of the box and try to impact the user behaviour. The pre-story goes like this:
Presently, the demand for electricity is not uniform and is strongly skewed towards times when large number of appliances are simultaneously in use. Basically, these are the times when most of the people come home from work. Simultaneous use of larger number of appliance does not last a very long period of time and, hence, has to be covered with additional generation. These generation sources need to be activated quickly enough, that is why, harnessing the peak of power consumption usually involves gas turbines. It also means extra costs and higher carbon footprint. Energy markets provide regulative measures in terms of increased price. However, not all ordinary consumers are taking this into consideration.
Our app, goals:
Our application provides the customer a possibility, himself, to make an impact in the real world, to feel himself as a part of the change. The goal of the application is to raise awareness of power consumption of ordinary consumers and, alas, help them to make a transition from just consumers to “actuators”. Perhaps presently, not every individual has capability to pay enough attention to improving the carbon footprint, for whatever various reasons, but we feel that applications like this can spark interest and active participation from every day consumers. We believe that consumers can benefit from active participation in optimizing their energy bill. This might help to realize the dependencies of price formation. Even small contribution is a great starting point.
Our app, features:
In our application, the user can participate in optimizing his daily bill using systems advices and price data. It is possible to immediately see, how shifting the time of use of the several power demanding appliances can change the outcome of the energy bill and, hence, decrease the carbon footprint, making a contribution to a cleaner world.
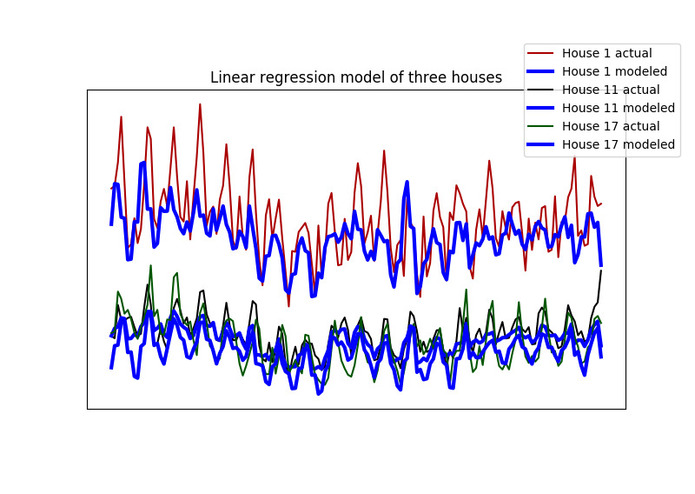
Contributing personal energy consumption data benefits in personalizing the consumption patterns. Using linear regression, power consumption in pair with weather data helps to create daily base consumption patterns of ordinary appliances that are not likely to be shifted to other time periods.
The instantaneous impact of his actions is displayed in the total energy price.
Implementations:
We tried to make a user friendly experience by creating a smooth UI where we divided the day into 8 segments of 3 hours, that are able to fairly represent the market price changes that affect the CO2 emissions.
Base consumption is a product of linear regression, provided consumption data and weather api data.
Energy price data is collected from the Nordpool api.
The application is available for Android devices starting from v4.4
What did we learn besides this project:
During the hack, we tried to create real-time disaggregation data with several algorithms. We tried the disaggregation of power consumption with time-lagged neural networks using total electric power data with the frequency of 0.166… Hz. The initial goal was to train 10 different appliances using the UKDALE dataset. It turned out that within the time limits of Junction, training the networks would have taken too long with the available computational resources. The best results we managed to achieve was the power consumption estimate of the fridge, the figure below. The figure shows the NN estimation of the fridge power consumption (the yellow line) and the actual power consumption of the fridge.
The output of the NN somehow follows the actual value and the mean error was relatively low. However, outliers occurred much and the accuracy is insufficient. Training such a network took something between 5 and 7 hours with laptop having Intel Core i5-6300U @ 2.40 GHz, 8 GB RAM and Windows 7. To achieve better results, we should have need to use bigger data sets and, ideally, higher frequencies, which would have resulted even longer training times.
Additionally, we have spent a lot of time trying to use open source toolkits for disaggregation, among largest is NILMTK. However, lack of metadata and arduous data conversion algorithms made it impossible to train and disaggregate the given data.



Log in or sign up for Devpost to join the conversation.