





Inspiration
When lives are on the line, time is the enemy. Surveillance networks generate terabytes of footage, yet investigators are forced to review it clip by clip, camera by camera. By the time evidence is pieced together, the suspect is gone. Manual workflows are too slow, they cannot keep up with the scale and urgency of modern security. We built Superhuman because surveillance needs to move at machine speed, not human speed.
⚡ TL;DR
- Agent Swarm → Not one agent, but 20+ AI agents in parallel to analyze CCTV feeds and combine results in real time.
- Computer Vision based Video Inpainting → LaMa + Fast Fourier Convolution (FFC) restore occluded/corrupted frames via binary mask detection + homography-based pixel propagation.
- VLM Fusion → OpenCV facial re-ID + LLaVA & GPT-Vision align embeddings with natural-language queries for semantic-visual suspect search.
- Generative AI Layer → Runway Gen-4 predicts trajectories (image → video), ElevenLabs adds voice for news-style alerts.
What we built + how it works
Superhuman is a multi-agent orchestration platform that transforms fragmented CCTV footage into an intelligence system. Instead of a single investigator spending hours on video review, we deploy a swarm of 20+ AI agents in parallel using the Agents-SDK by OpenAI (previously known as Swarm). They process multiple feeds at once, querying Vision Language Models, and fuse results into a single timeline. In minutes, Superhuman delivers visual insights by combining OpenCV's facial recognition and OpenAI's semantic search, to map a suspect’s movements with precision.
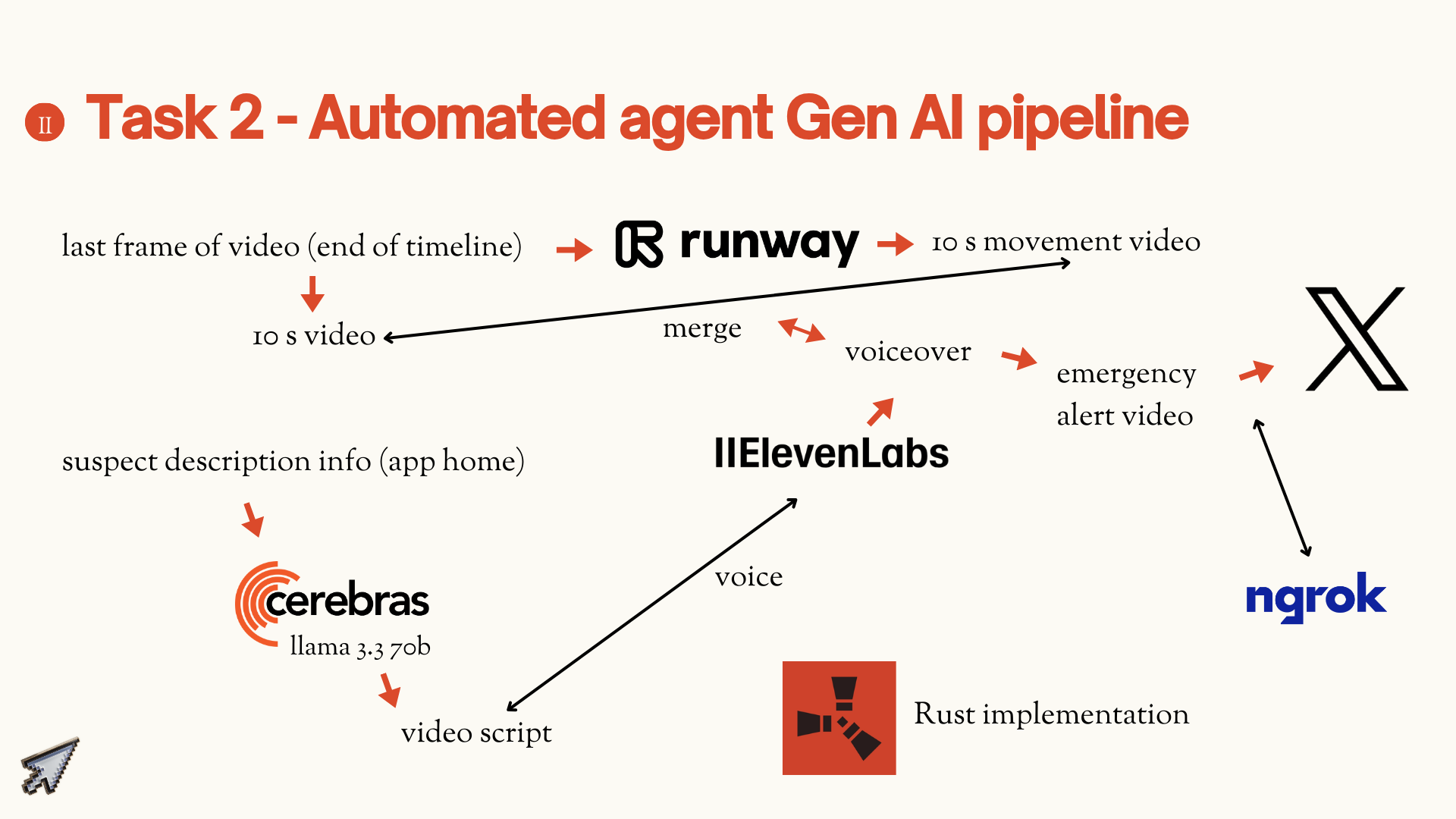
To bridge surveillance with public awareness, we added a generative AI layer. With Runway Gen-4, we can extrapolate a suspect’s likely trajectory from a single image, generating predictive video. Using ElevenLabs, we overlay voice to produce news-style alerts & clips that can be automatically posted to platforms like X (Twitter), ensuring the public can be mobilized instantly. All of these capabilities come together in our investigator dashboard built in Next.js, which runs on Zod-validated workflows. Within a single interface, investigators can find visual clues, explore geospatial traces, and generate alerts. With Cerebras, we run fast LLM inference across the system for querying the timeline, generating news-style alerts, etc.
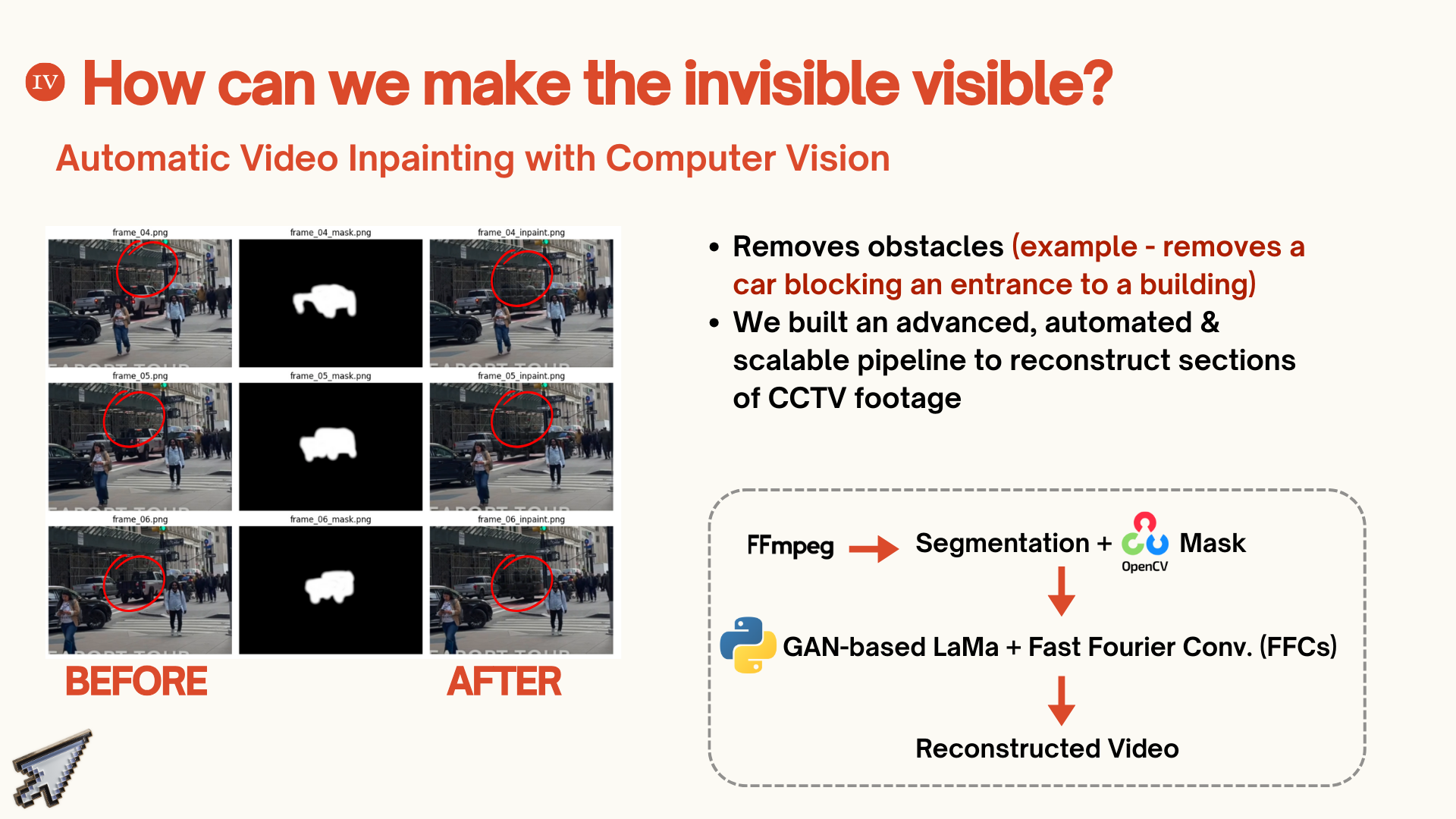
A rather interesting part of this project was working on video-inpainting for scene restoration, which is an important CV technique for our use case. Traditional CCTV analysis collapses when frames are occluded or corrupted: a car blocks the suspect, glare wipes out pixels, or compression errors make footage corrupted. We integrated LaMa with Fast Fourier Convolution (FFC), a cutting-edge inpainting method that reconstructs missing information. Our pipeline automatically generates binary masks to detect obstructed regions, then propagates corrected pixels across adjacent frames using homography-based alignment in Python. The result is footage that can be restored even under notable occlusion.




Challenges we ran into
Some challenges were coordinating agents without deadlocks and stabilizing LaMa + FFC for inpainting across different formats. But there is a clear future challenge as we move from image-based to video-based trajectory prediction: How can we ensure that generative outputs stay accurate without fabricating misleading evidence?
Accomplishments we're proud of + what we learned
Definitely one of our most ambitious software hacks. We learned a lot putting all the pieces together - agent orchestration, LaMa + FFC for video inpainting, OpenCV with LLaVA for suspect search, Google Maps for geospatial data, and Runway + ElevenLabs for multimedia alerts, all tied into a Next.js dashboard.
What's next for Superhuman
1) Can we run inpainting on live camera streams? 2) Include active rerouting - If the camera feed is noisy, we could auto-assign more agents to neighboring feeds / escalate to inpainting first.
Built With
- cerebras
- elevenlabs
- fastfourierconvolution
- gan
- gen-4
- google-maps
- lama
- llama
- llava
- next.js
- ngrok
- openai
- openai-agents-sdk
- opencv
- parallel-agents
- python
- runway
- scene-restoration
- video-inpainting
- vision-language-retrieval
- x
- zod










Log in or sign up for Devpost to join the conversation.