






SuperCompress
AI wastes energy by reading junk. SuperCompress fixes that.
Every agent workflow sends massive context to the GPU: old logs, irrelevant RAG chunks, boilerplate files, stale tool calls, and filler conversation turns. The model pays for every token — in API cost, GPU time, KV-cache memory, electricity, cooling, and carbon.
SuperCompress removes the context that does not matter before it ever reaches the GPU.
Not by blind truncation.
Not by summarizing everything.
By learning what is safe to forget.
Why This Matters
AI scaling is becoming an energy problem.
Every unnecessary token sent to a model consumes compute. At small scale, that looks like a few wasted cents. At agent scale, it becomes millions of useless tokens processed, stored, cooled, and billed.
SuperCompress turns context compression into an environmental primitive:
Do not make the GPU read what the answer does not need.
Every token removed is:
- Less GPU prefill work
- Less KV-cache memory
- Less electricity
- Less cooling demand
- Less CO₂ emitted
- Lower inference cost
The goal is simple:
Make AI cheaper, faster, and cleaner without making it dumber.
The Core Idea
Most compression methods optimize for how much text they delete.
SuperCompress optimizes for what value they preserve.
A normal truncation method might delete the exact line that answers the question just because it appears in the middle of the context.
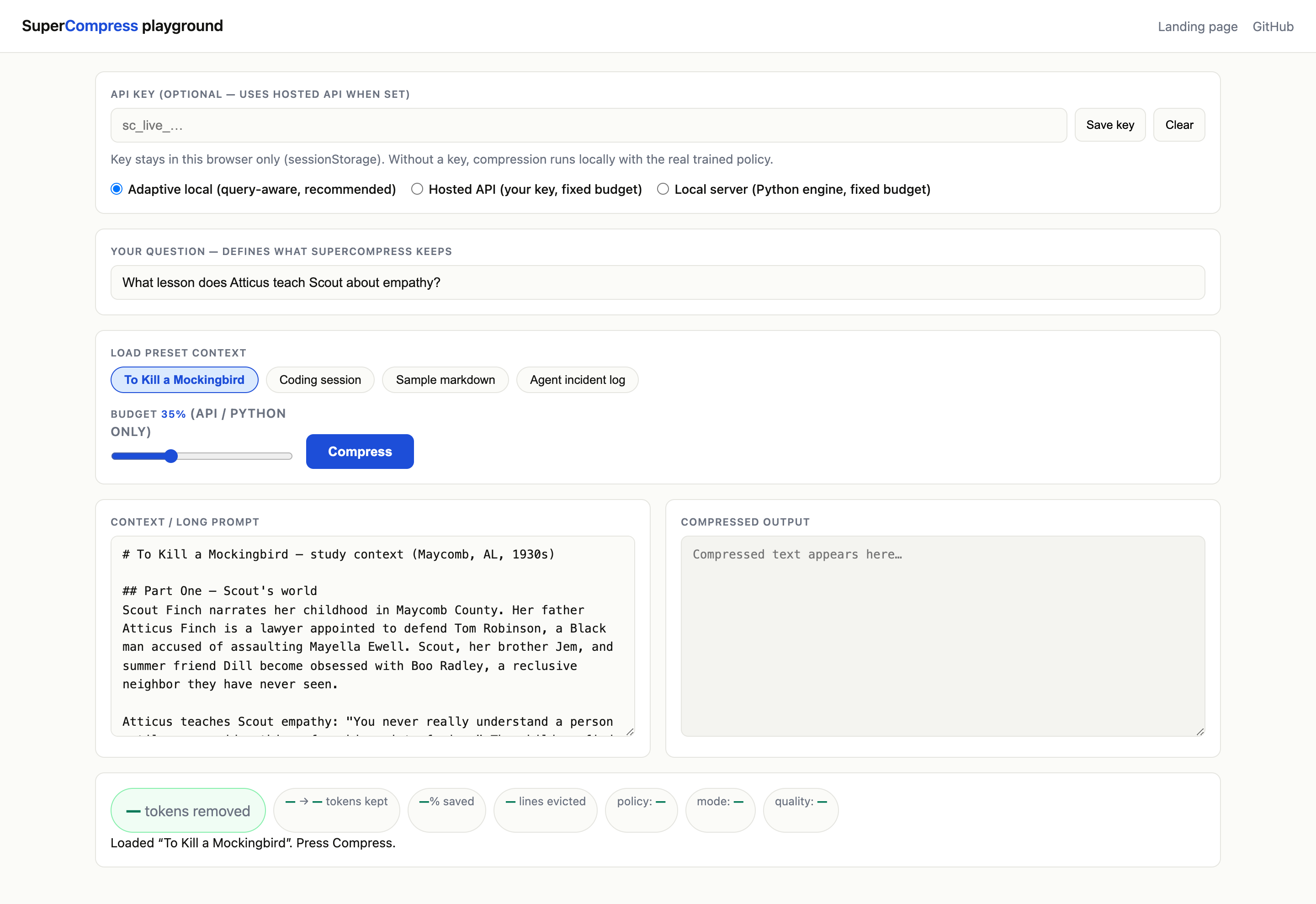
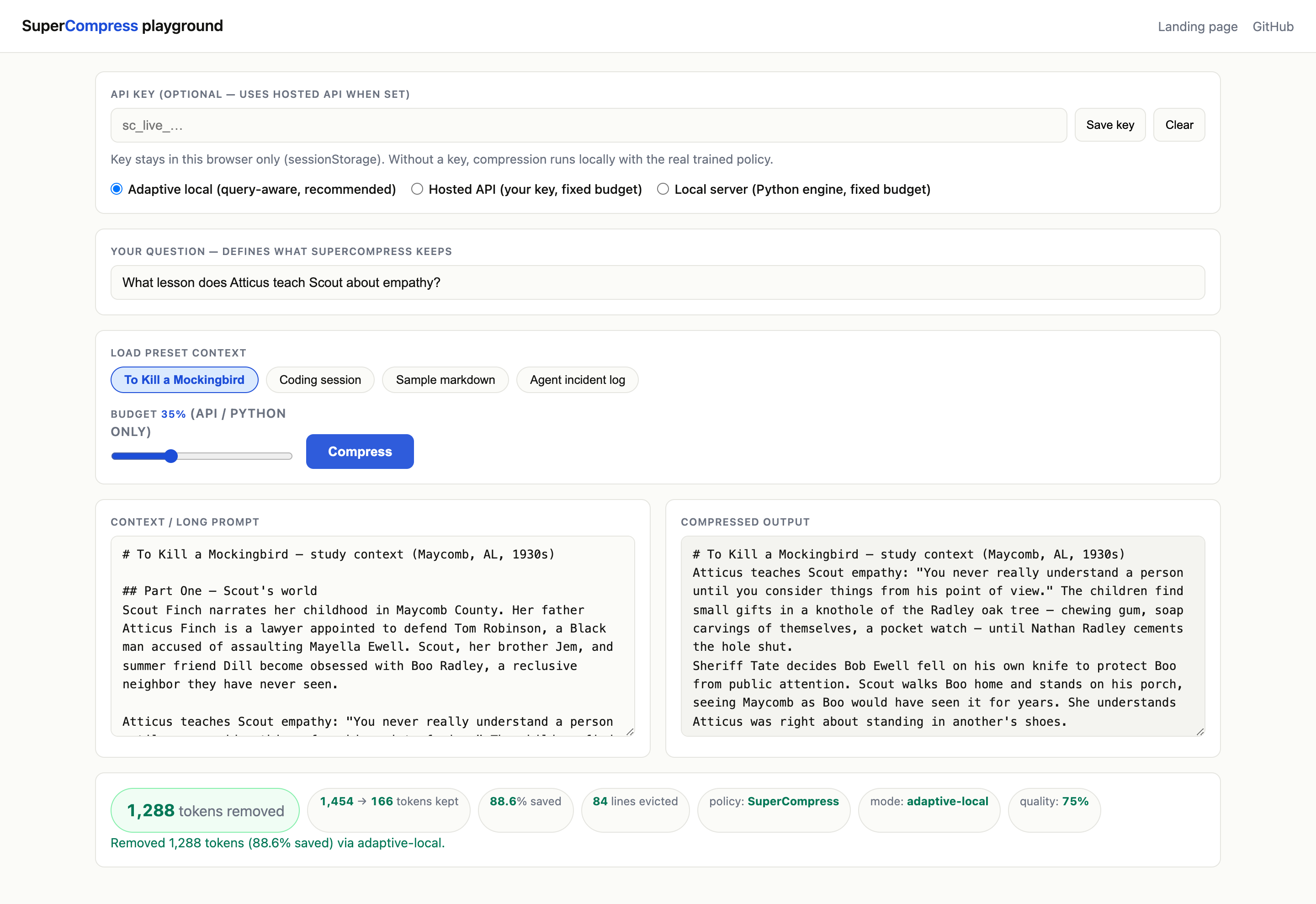
SuperCompress instead scores context against the active query and keeps what matters.
Long context + user question
↓
Tokenize context
↓
Score each token with a tiny CPU model
↓
Remove low-value lines
↓
Preserve answer-critical entities
↓
Send compressed prompt to the LLM
Environmental Impact
SuperCompress estimates avoided CO₂ using the idea that fewer tokens create fewer KV-cache slots and less GPU work.
$$ \text{CO}2 \text{ avoided} \approx \Delta tokens \cdot \alpha{\text{KV}} \cdot \frac{1}{\text{tokens/GPU-s}} \cdot \frac{W_{\text{GPU}}}{3600} \cdot \frac{\text{kg CO}_2}{\text{kWh}} $$
Where:
$$ \alpha_{\text{KV}} \approx 0.55 $$
This represents the share of prefill compute attributed to context and KV-cache work.
At scale, the impact compounds.
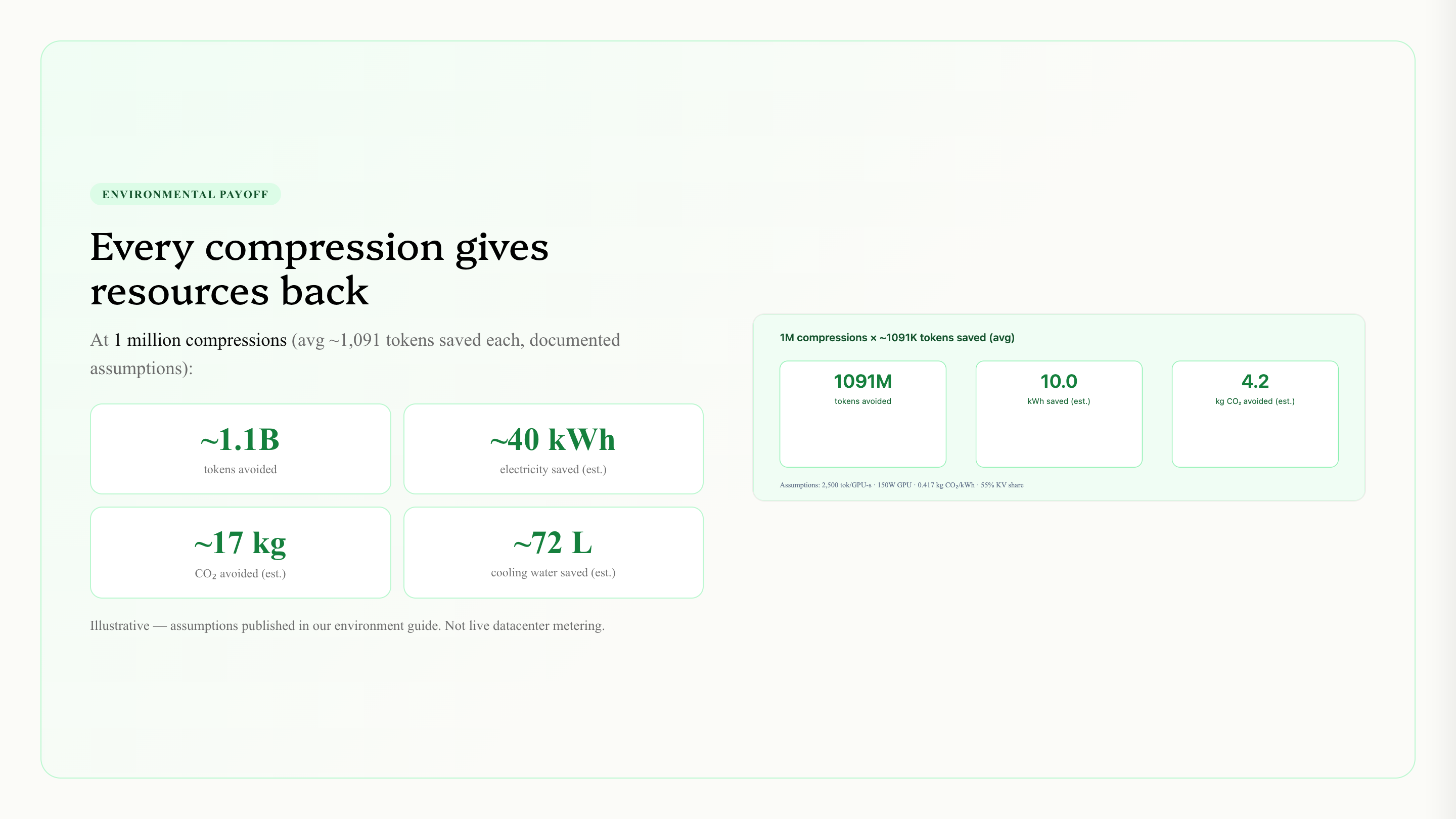
For example:
$$ \Delta tokens \approx 800\text{M} $$
$$ \Delta E \approx 29\text{ kWh} $$
$$ \Delta \text{CO}_2 \approx 12\text{ kg} $$
These are illustrative estimates, not live datacenter telemetry. The assumptions are documented in the Environment Guide.
SuperCompress also estimates water savings using:
$$ W_{\text{water,mL}} \approx E_{\text{kWh}} \times 1.8 \times 10^3 $$
The live demo labels all impact numbers clearly as estimates.
No greenwashing.
No fake precision.
Just honest math.
What We Learned
1. Compression budget is not compression intelligence
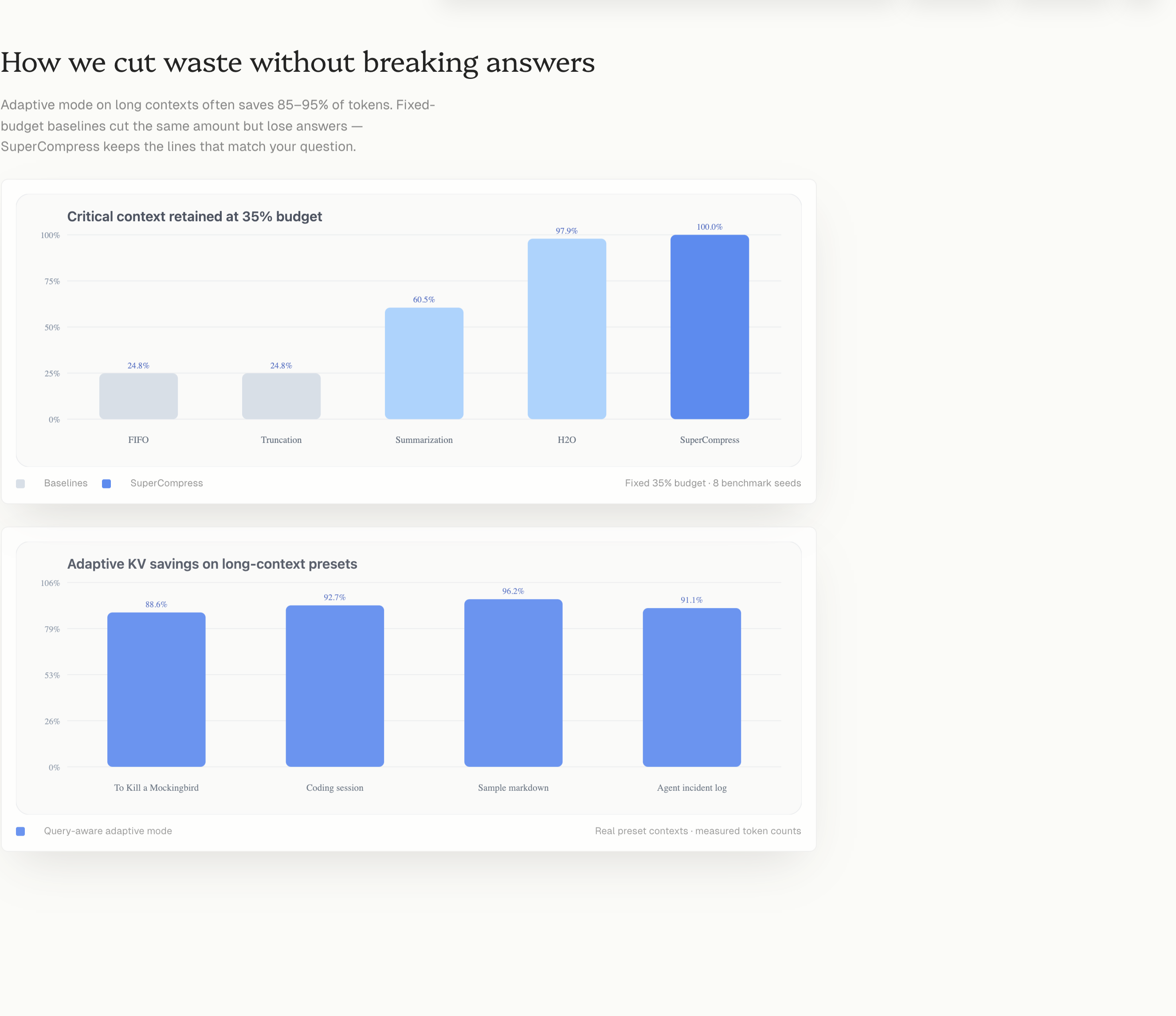
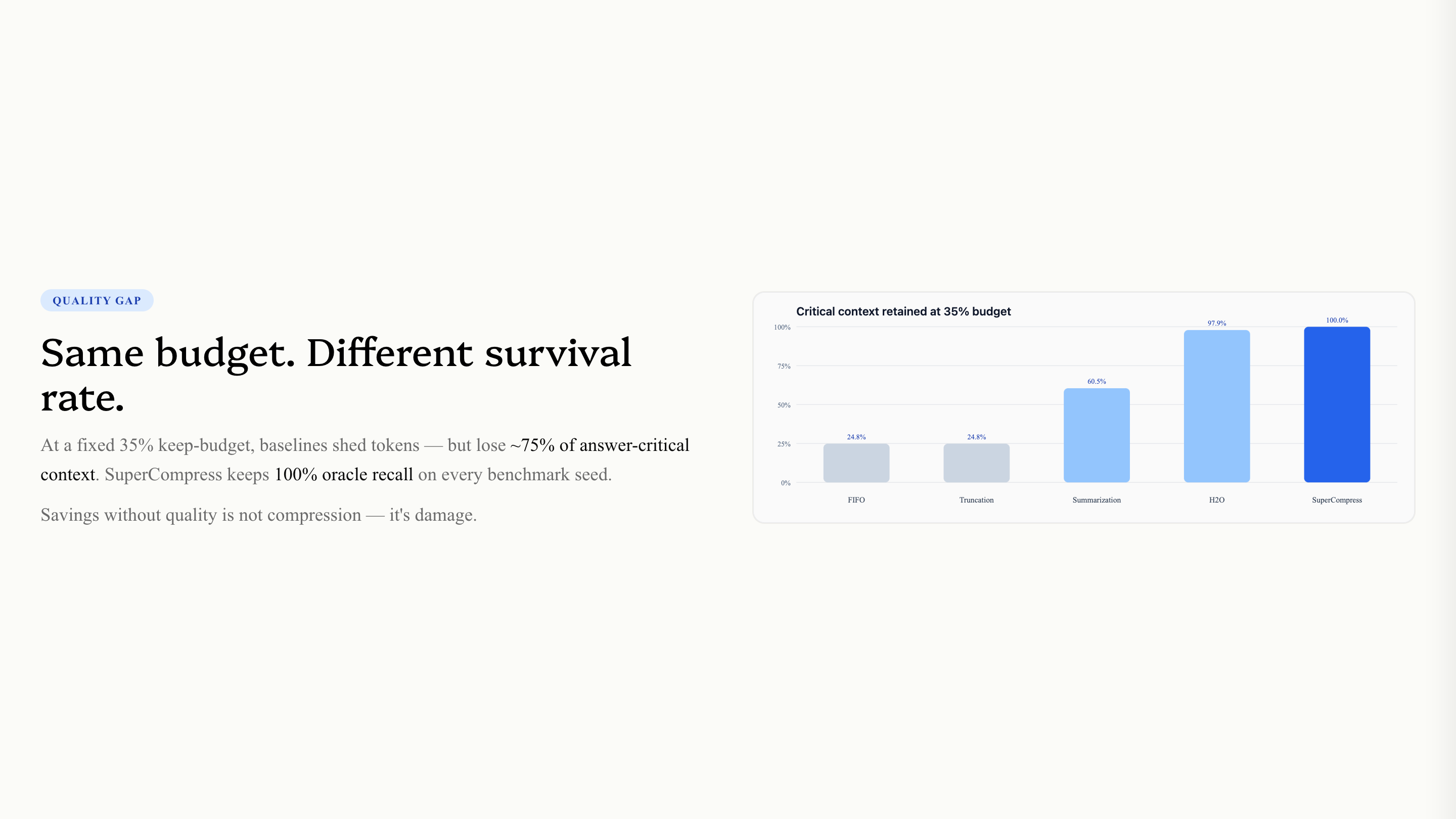
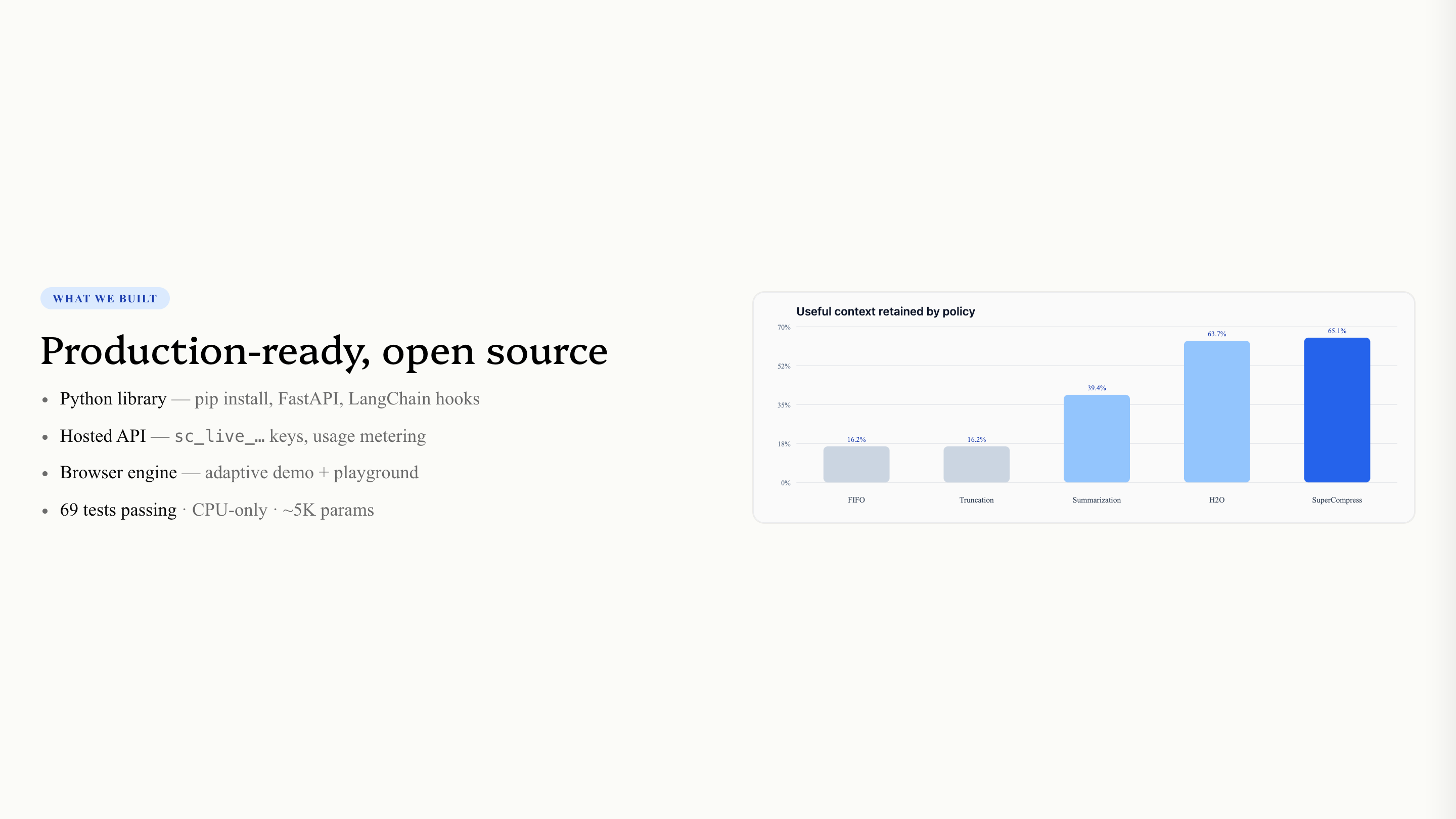
FIFO, truncation, and summarization can all hit around 65% KV savings at a 35% keep budget.
But they often delete the wrong things.
On benchmark seeds, those baselines fall to around 25% oracle recall.
SuperCompress reaches 100% oracle recall at the same budget because it scores context against the actual question.
The real metric is not:
How much did you delete?
It is:
Did you delete the right things?
2. Small models can gate big models
The EvictionPolicyNetwork is tiny: roughly 5K parameters, CPU-only, and sub-millisecond on laptop hardware.
It does not generate text.
It decides what text the big model should not have to read.
That tiny decision can save far more GPU work than it costs.
3. Honest environmental claims matter
The demo shows:
- Tokens saved
- KV savings
- Electricity saved
- Water saved
- CO₂ avoided
But every number is presented as an estimate.
The assumptions include:
| Assumption | Value |
|---|---|
| GPU power | 150 W |
| Throughput | 2,500 tokens/GPU-second |
| Grid carbon intensity | 0.417 kg CO₂/kWh |
| KV share of prefill | 55% |
| Cooling water estimate | 1.8 L/kWh |
The point is not to pretend we have live datacenter telemetry.
The point is to make the cost of wasted context visible.
How It Works
Each token becomes a compact 9-dimensional feature vector.
| Index | Signal |
|---|---|
| 0–1 | Attention mass and layer attention mean |
| 2 | Recency |
| 3 | Question entity match |
| 4–8 | Semantic type: code, comment, chat, boilerplate, or other |
The model scores each token, groups by line, and evicts the lowest-value lines while protecting answer-critical entities.
Benchmarks
Eight seeded scenarios were tested at a budget ratio of 0.35.
| Policy | KV Savings | Oracle Recall |
|---|---|---|
| FIFO | ~65% | ~25% |
| Truncation | ~65% | ~25% |
| Summarization | ~65% | ~25% |
| H2O | ~65% | ~90% |
| SuperCompress | ~65% | 100% |
Same savings. Very different answer quality.
That is the whole story.
Product
SuperCompress ships as more than an algorithm.
It includes:
- Python library
- Hosted API
- Vercel deployment
- Firebase auth
- Blob-backed API key storage
- Live demo
- Mintlify docs
- Usage tracking
- Environmental impact estimates
- 65 automated tests
Stack
| Layer | Technology |
|---|---|
| Policy + training | Python 3.10+, PyTorch, ~5K-parameter MLP |
| Public API | Python compress_context() |
| Production API | Vercel serverless routes |
| Key storage | @vercel/blob |
| Browser engine | compress-engine.js + model.json |
| Auth | Firebase Admin |
| Site | Static web app on Vercel |
| Docs | Mintlify |
Usage
Install
pip install git+https://github.com/arjunkshah/supercompress.git
Hosted API
curl -X POST https://trysupercompress.vercel.app/api/v1/compress \
-H "X-API-Key: sc_live_..." \
-H "Content-Type: application/json" \
-d '{
"context": "...",
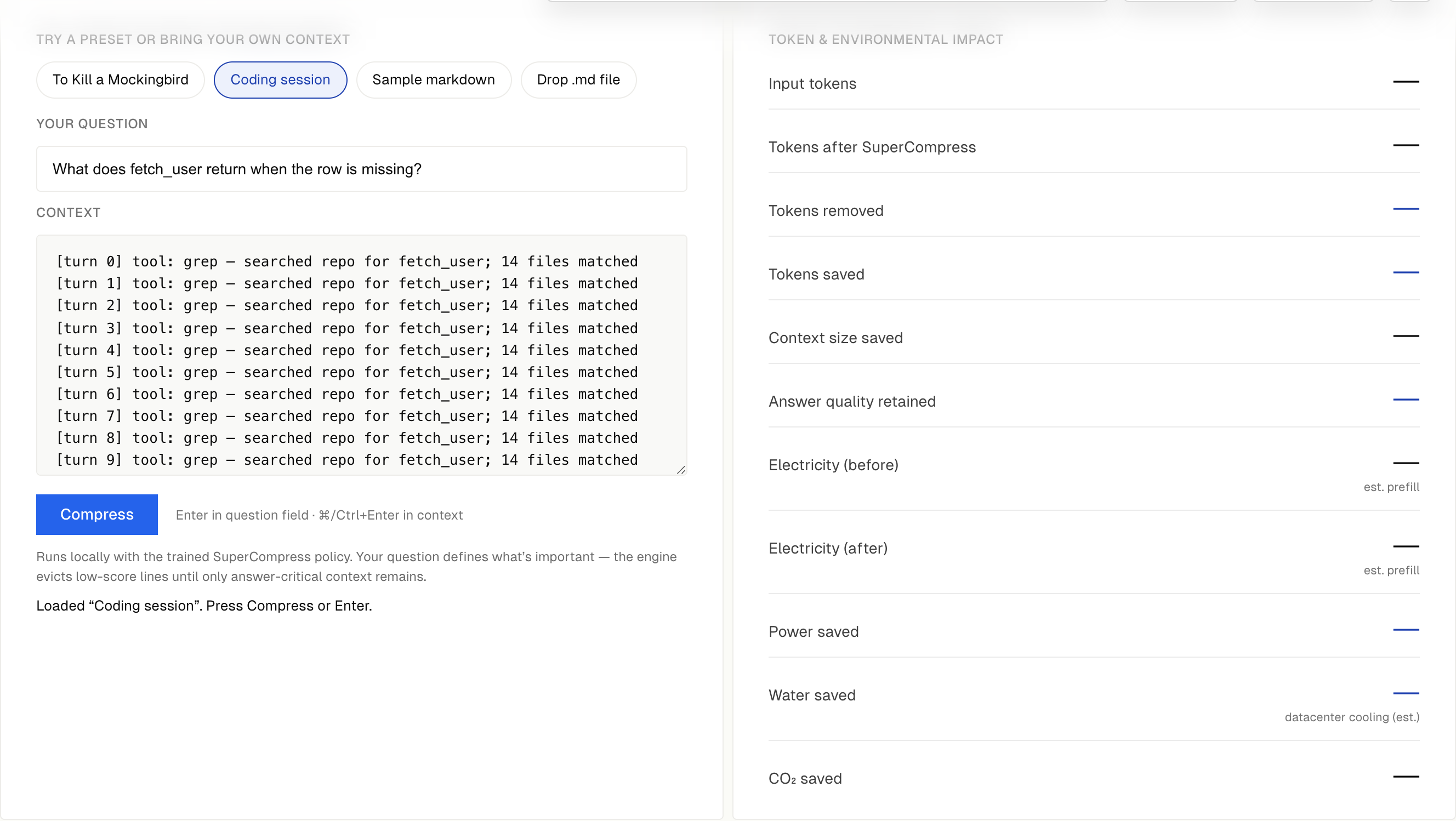
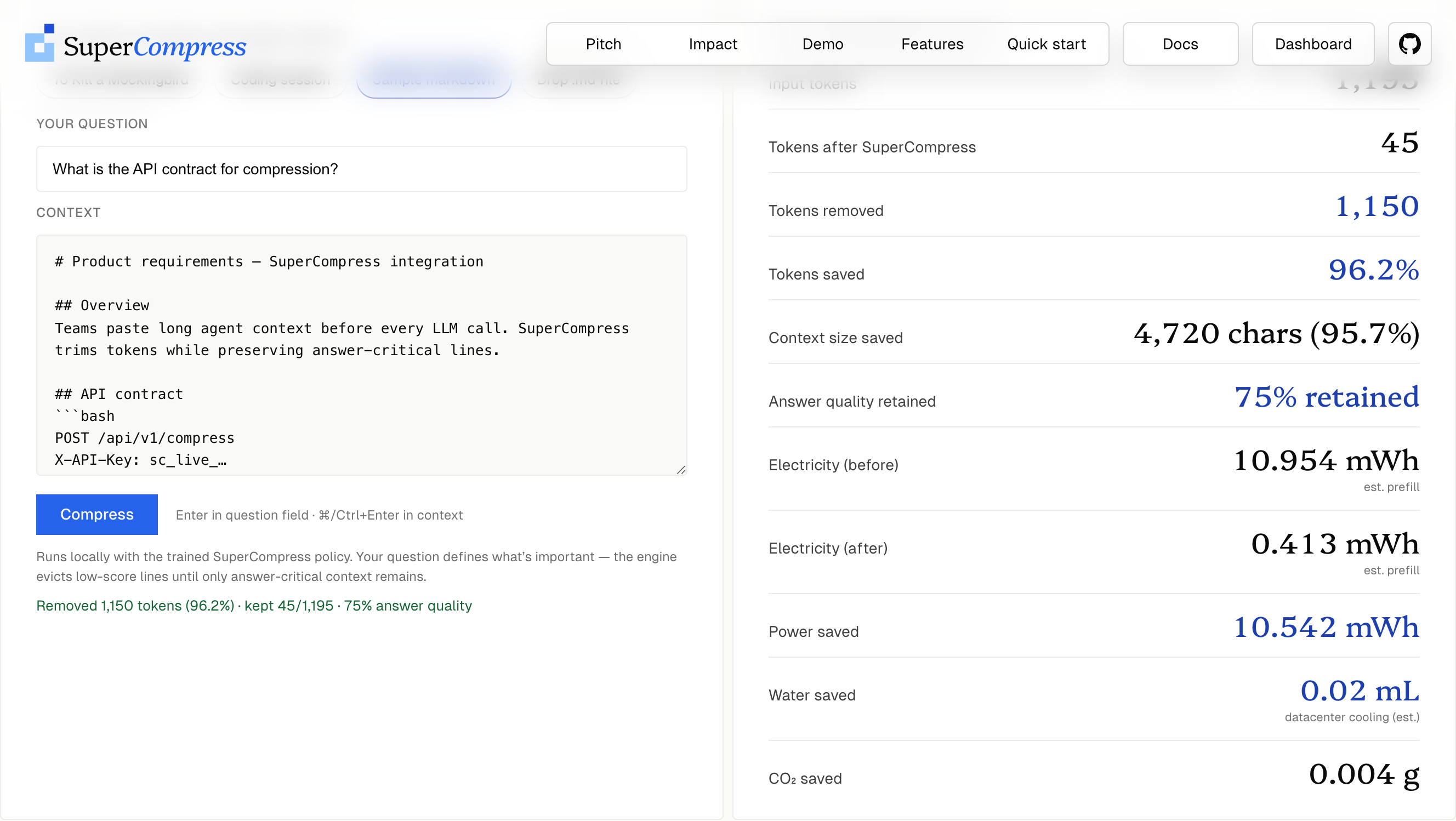
"query": "What does fetch_user return?"
}'
Challenges
1. Fixed savings looked fake
A fixed 0.35 keep budget always produced roughly 65% savings, which made the demo feel hardcoded.
We fixed this with adaptive learned eviction. Savings now vary based on the actual input and query.
Examples:
- Around 74% savings on agent logs
- Around 96% savings on long filler with a small answer core
2. Truncation failed where agents need memory most
Head-and-tail truncation often loses answers buried in the middle of context.
We built a failure-case demo showing truncation achieving high savings but near-zero answer quality.
SuperCompress keeps the critical line.
3. Production infra was part of the product
The first version had broken backend wiring, unreliable Blob overwrites, and incorrect API imports.
We moved to:
- Vercel-native serverless routes
- Same-origin
/api/* - Versioned Blob snapshots
- One deploy
- One domain
Infra was not separate from the product.
It was the product becoming real.
Why SuperCompress Exists
We are not asking models to think less.
We are asking them to read less junk.
SuperCompress gives developers a way to reduce cost, latency, and environmental impact while preserving the answer.
Cleaner prompts.
Lower GPU load.
Less wasted energy.
Same answer.
Links
- Live demo: supercompress.vercel.app
- Docs: arjunkshah-supercompress-55.mintlify.app
- Open source: github.com/arjunkshah/supercompress

Log in or sign up for Devpost to join the conversation.