-
-
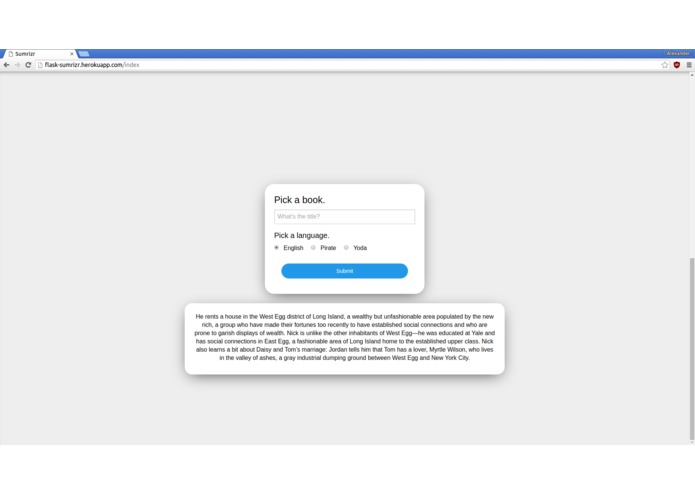
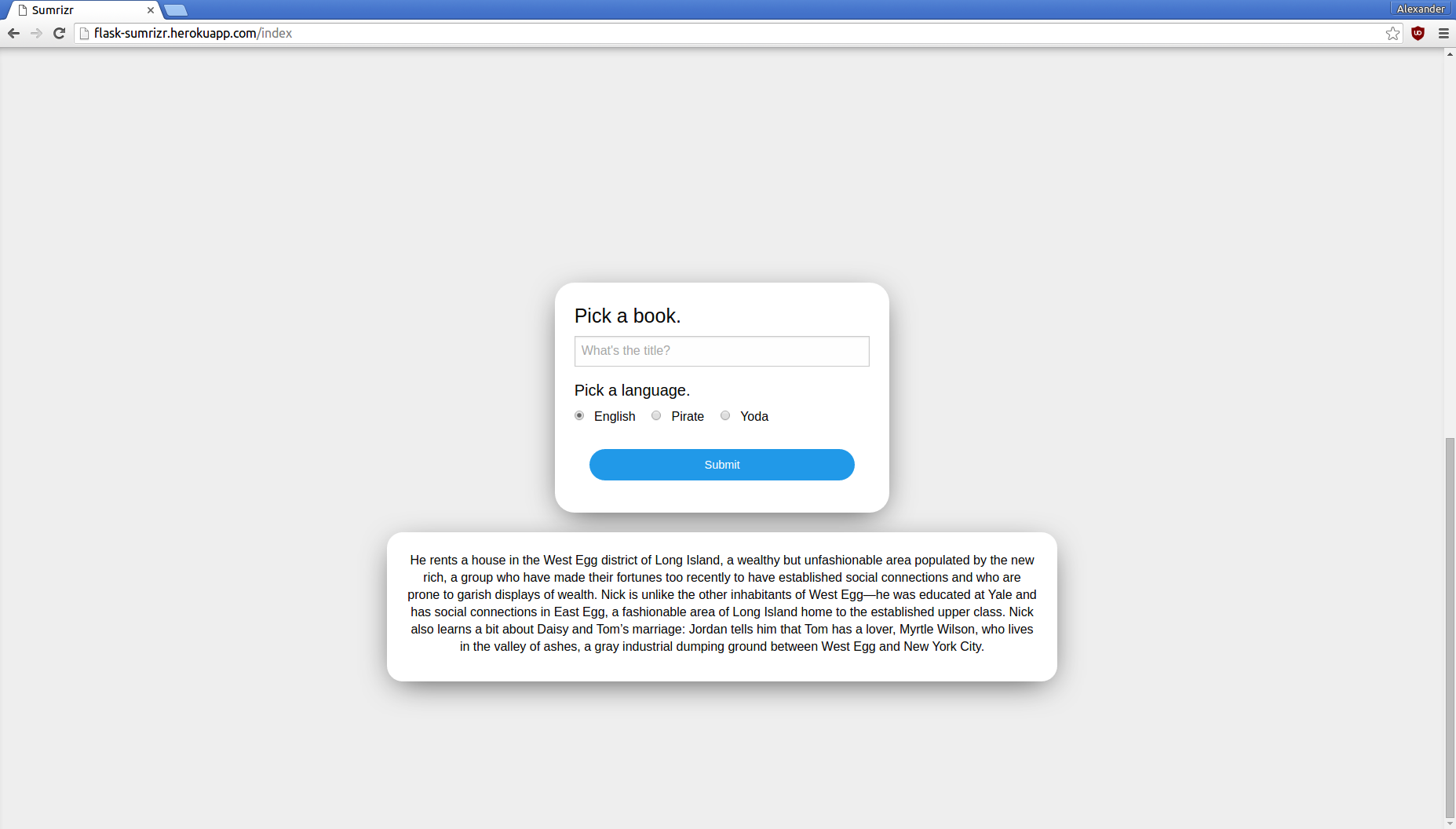
Summarizing The Great Gatsby
Inspiration
We took our inspiration from such cultural phenomena as Thug Notes and Drunk History, making assigned reading even easier for students than Sparknotes.
What it does
Sumrizr take a book title, scrapes summary data from the internet, summarizes that with natural language processing, and returns that concise description in English or pirateSpeak
How we built it
Sumrizr uses BeautifulSoup4 web scraping to get summary data, first from Sparknotes, and then from Wikipedia. Then it uses the sumy module to perform natural language processing on the summaries and return an even more concise version. All of this is running in a Heroku app, which we implemented using the Flask framework, and our own front end design, all running inside of gunicorn.
Challenges we ran into
Stripping HTML tags out of web scraping data proved to be difficult. In addition, getting the proper python packages to run in a virtual environment was a grueling endeavor, requiring some git wizardry and a whole lot of sudo pip installs. After that, we ran into a lot of trouble getting Heroku to accept and build our app.
Accomplishments that we're proud of
We're proud of successfully merging a web scraping algorigthm, a natural language processing module, and an organic web app in one coherent product.
What we learned
We learned the ins and outs of web scraping with BeautifulSoup, NLP with sumy, building with Flask, and deploying to Heroku!
What's next for Sumrizr
- Learning how to implement a SQL database so that users can rate their reviews
- Making a more generic scraping algorithm to get summaries from more sources
- OCR image to text processing and summary

Log in or sign up for Devpost to join the conversation.