-
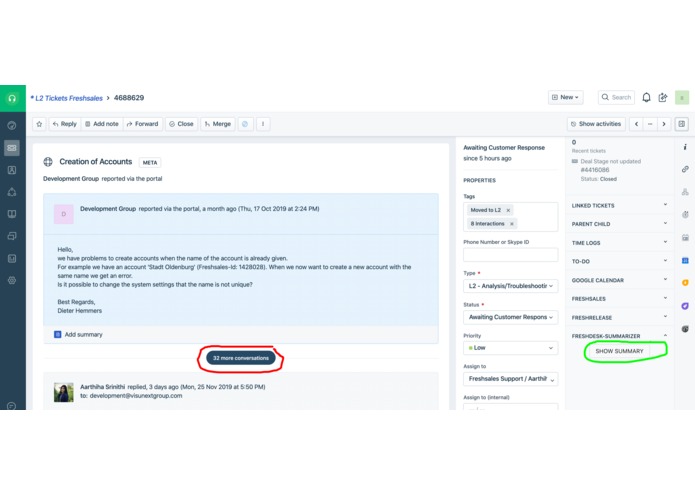
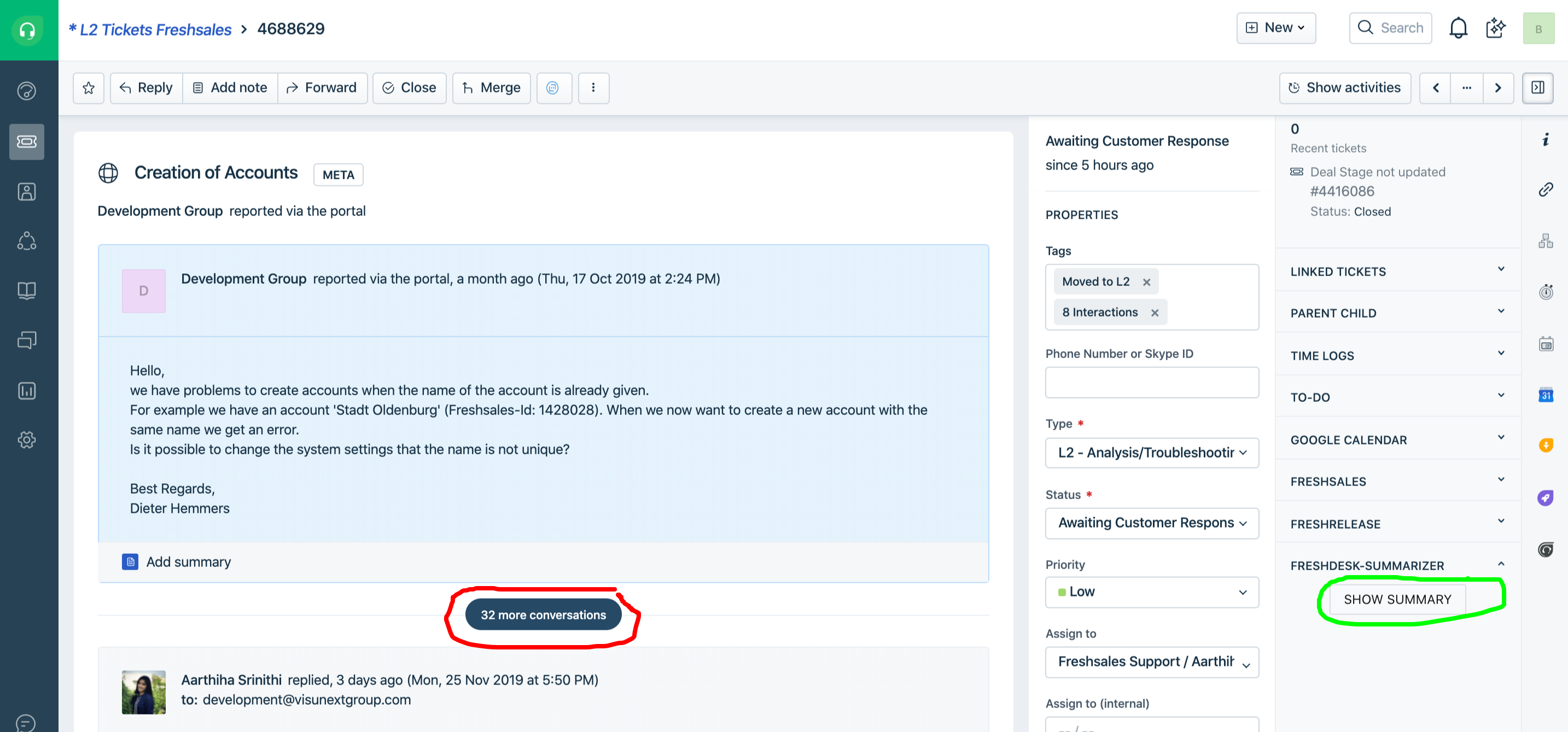
Having 32 conversations
-
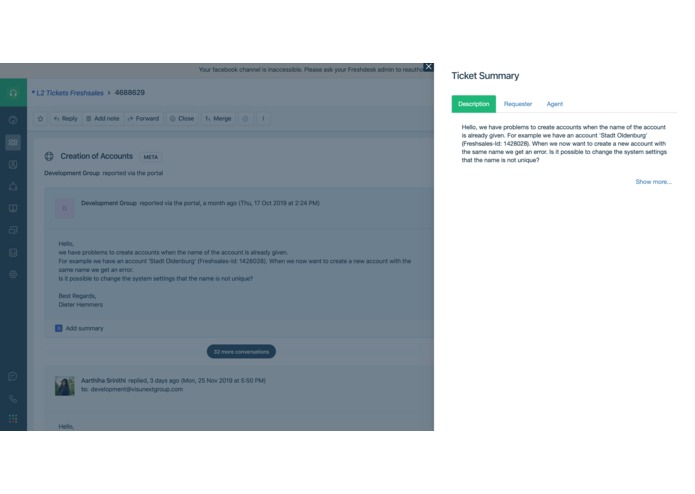
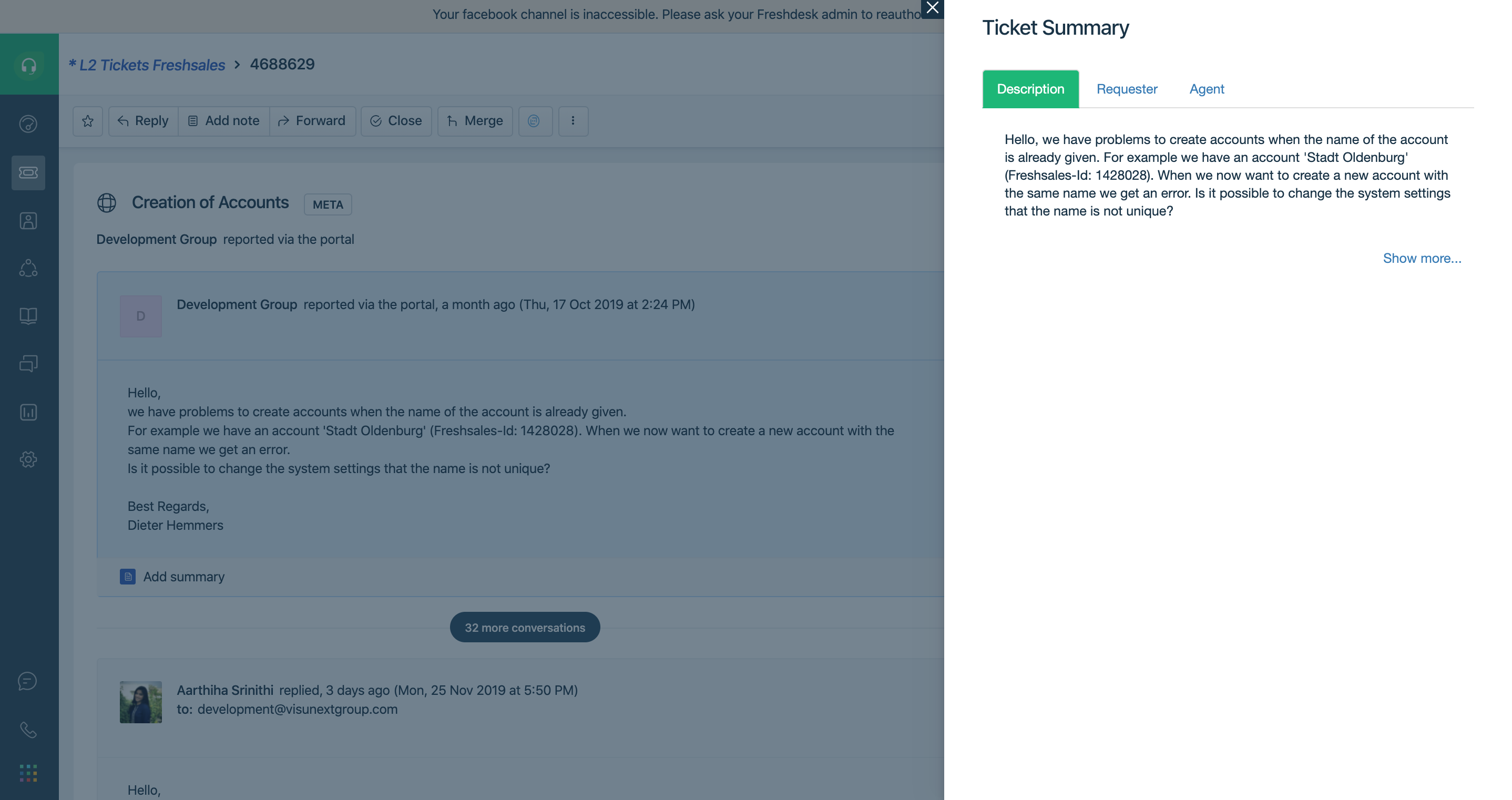
Summary of ticket description
-
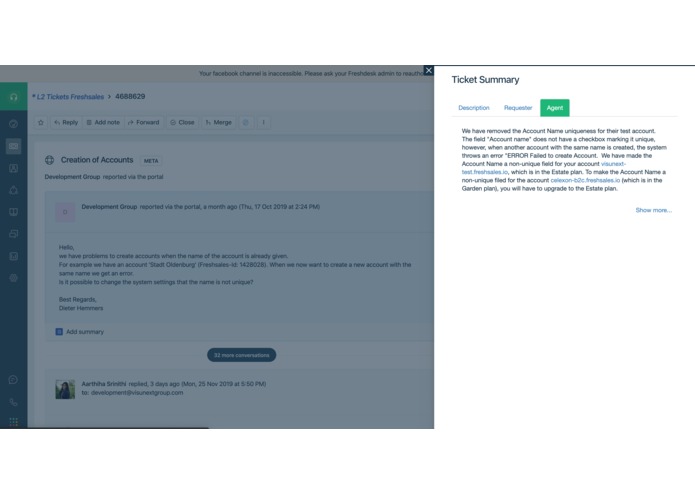
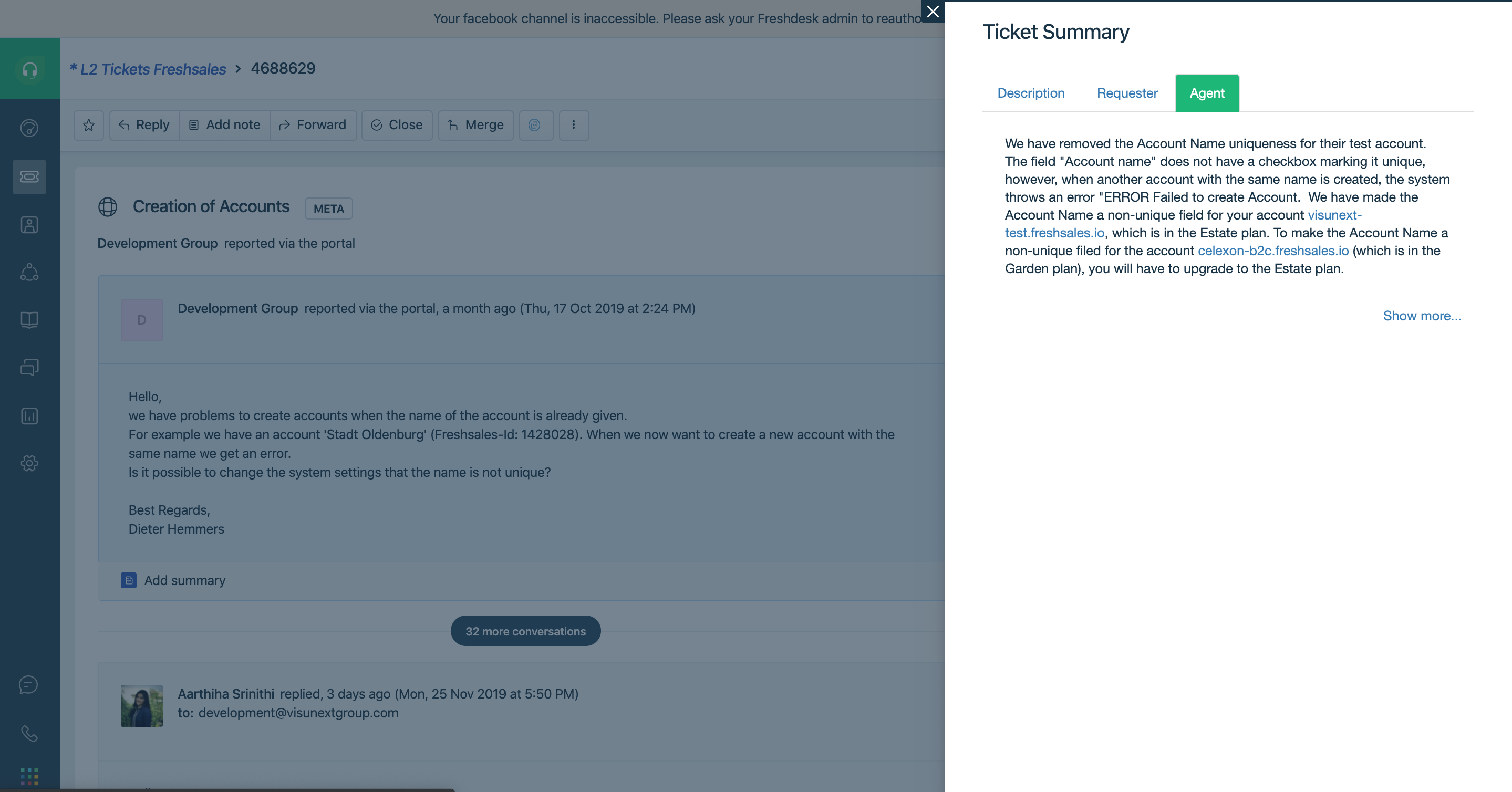
Summary of agent responses
Inspiration
Text summarization is a hard problem to solve. It will be useful in a lot of use cases like summarizing a support ticket or interviewer feedback or an email. In Freshdesk, we have to read all conversations to understand a support ticket. In Freshteam we have to read all interviewer feedback to understand a candidate. How can we reduce an agent's effort to understand a support ticket or interviewer feedback quickly?
based on the above pain point we started thinking through it and started building a text summarization engine.
What it does
Text summarizer is a small microservice which will take input as text and summarize it. Frontend-app will be sending text as input summarizer will be summarizing the given text and send as output to the frontend-app.
How we built it
We wrote a LDA(Latent Dirichlet Allocation) algorithm which will give top N words from a topic, based on this top N words we will calculate clustering score for the sentences. Sentences will be sorted based on the clustering score.
# tokenize all the data into sentences
sentences = [s for s in nltk.tokenize.sent_tokenize(data)]
# run LDA algorithm to get top N words
top_n_words = LDA(data)
# run clustering score algorithm to get top n sentences
scored_sentences = score_sentences(sentences, top_n_words)
# return only the top N ranked sentences
top_n_scored = sorted(scored_sentences, key=lambda s: s[1])
return dict(top_n_summary=[sentences[idx] for (idx, score) in top_n_scored])
Example: In the case of the Freshdesk ticket summarization, we separated the ticket summary into 3 parts.
- Ticket description
- Agent responses summary
- Customer/requester replies summary
Challenges we ran into
Bringing the accurate text summarization for a support domain(freshdesk product) with the existing algorithms. Designing a proper frontend app UI which will imply to proper UX Learning new python libraries related to NLP
Accomplishments that we're proud of
We were able to make it work for the freshdesk and the freshserivce products with almost meaningful summaries : )
What we learned
We learned topic modeling, LDA(Latent Dirichlet Allocation), writing an app on the Marketplace platform.
What's next for Summarizer
Today we are doing only extractive text summarization. We have to extend this to abstractive summarization which will give a more semantic accurate summary.
Built With
- javascript
- lda-algorithm
- nltk
- python



Log in or sign up for Devpost to join the conversation.