Project Story
Inspiration
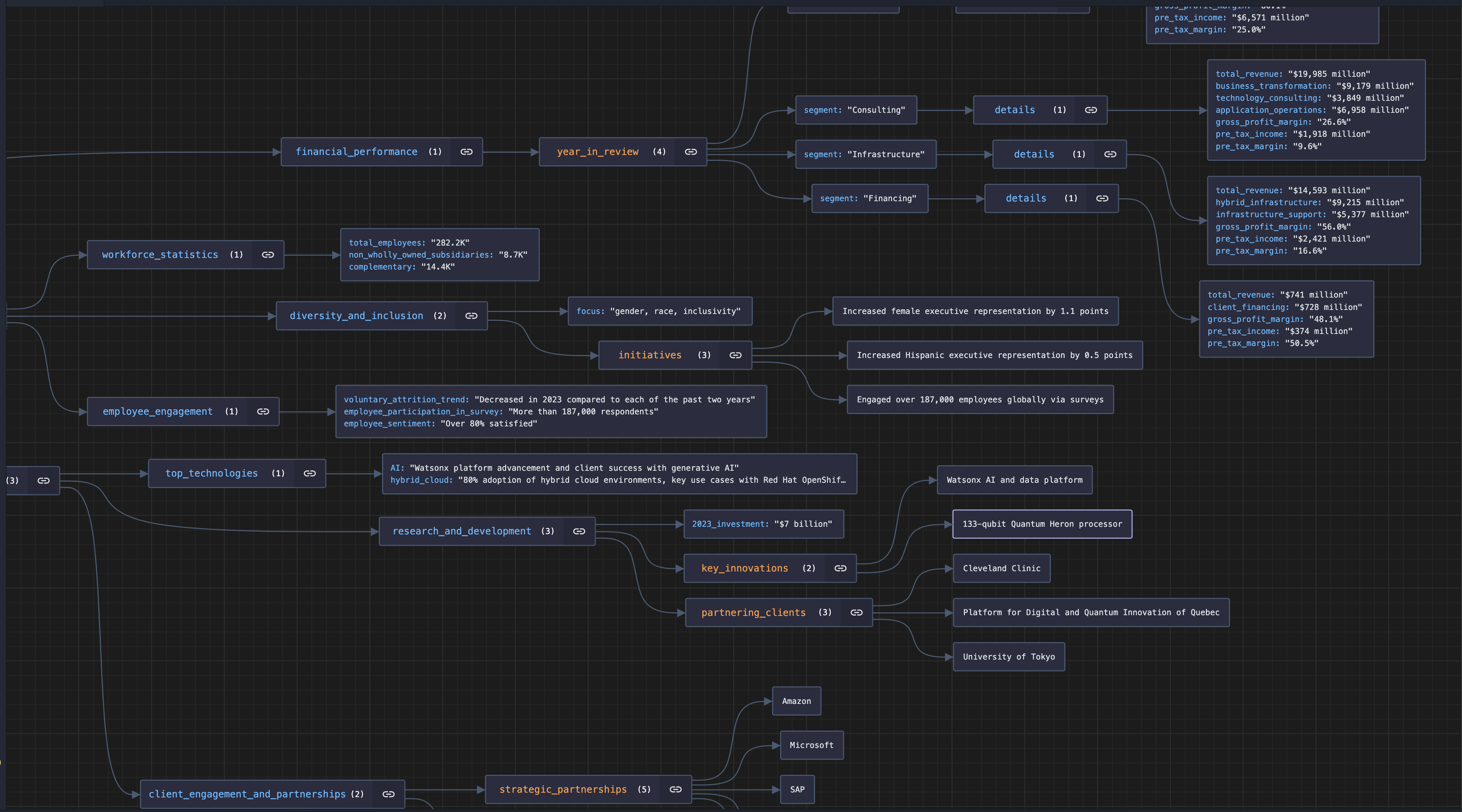
The project was inspired by the increasing complexity of corporate reports and financial documents. These reports often contain valuable insights but are challenging to digest due to their length and technicality. I wanted to create a tool that could transform these dense documents into easy-to-understand summaries and structured data, enabling anyone—from analysts to casual readers—to extract useful insights without wading through hundreds of pages. I also sought to harness the power of AI to streamline and automate this process, making analysis faster and more accessible.
What I Learned
Through building this project, I deepened my understanding of AI, particularly OpenAI's GPT-3.5 API. I gained experience in handling PDFs programmatically using the PyMuPDF library (fitz), and working with text extraction. The process also taught me the importance of optimizing AI prompts to ensure accurate and useful responses. Additionally, I learned how to manipulate large chunks of text, ensuring the AI model could handle the data efficiently and return useful insights. Finally, structuring the output in JSON allowed me to practice organizing data for easy analysis and machine readability.
How I Built It
I started by identifying the core task: extracting data from PDF reports and processing it in segments, so each part could be handled efficiently by the AI. The project is built with Python and uses several key libraries:
- PyMuPDF (fitz) for PDF processing and text extraction.
- OpenAI GPT-3.5 API for generating prompts and analyzing the extracted text.
- JSON to structure the final output into a machine-readable format.
The program works by dividing a PDF into segments (in this case, 48 pages), feeding each segment into the OpenAI model, and generating a response for each segment. Once all segments are processed, the program generates a comprehensive summary based on the individual responses. Finally, the results are saved into a JSON file.
Challenges I Faced
One of the main challenges was managing the large amounts of text extracted from PDF reports. The AI model has token limits, so I had to carefully split the PDF into manageable segments to ensure that each prompt remained within the model’s processing capabilities. Another challenge was designing prompts that would generate accurate and detailed responses from the AI. I also encountered issues with formatting the final output into JSON, especially when responses included unexpected characters that needed to be cleaned.
Additionally, dealing with varied formatting in PDFs (tables, charts, and images) presented challenges in terms of text extraction, as not all elements were easily interpreted by the AI.


Log in or sign up for Devpost to join the conversation.