
Domain.com submission: shortentext.online
Inspiration
All of us have had many experiences with dealing with webpages, articles, and terms of service agreements that are really difficult to parse and understand. Because of this, we've decided to create Sumex, short for summary extension, to make so we never have to read one of those monstrously long documents ever again and to take the time that we would have spent trying to understand them back for ourselves!
Who is this for?
-People who have visual disabilities (for example requiring screen readers or lower text density)
-Anyone who’s having trouble reading through massive Terms of Service documents
-Anyone who wants short summaries of large bills or legislation
-Lazy people who don’t want to spend ages reading articles :)
What it does
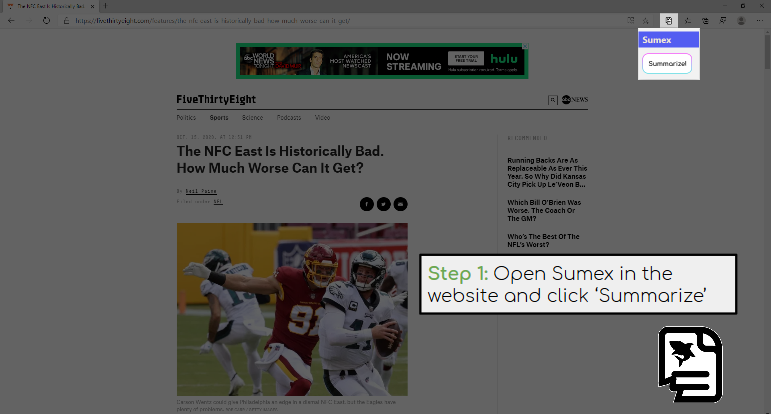
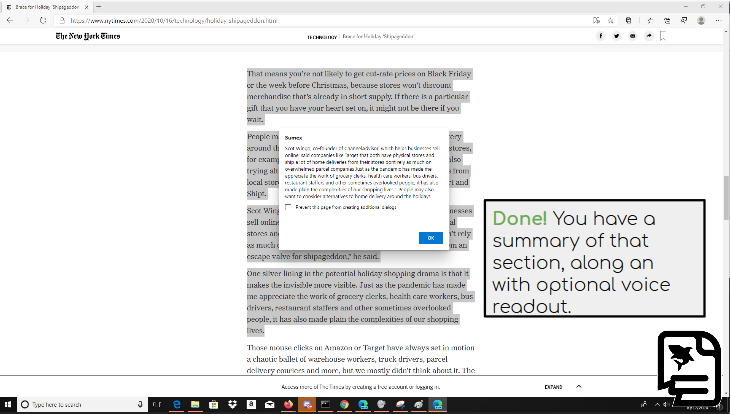
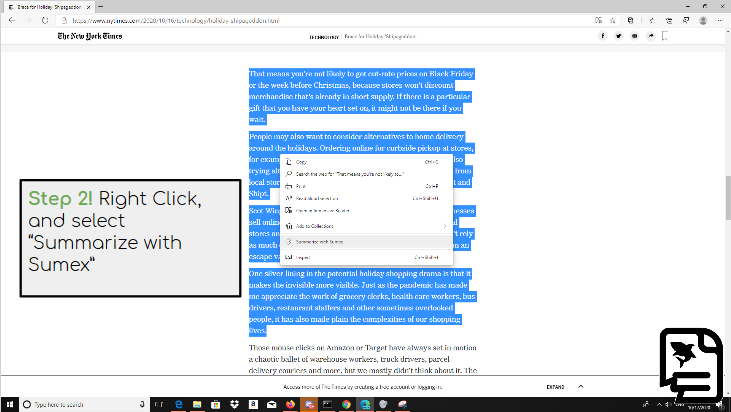
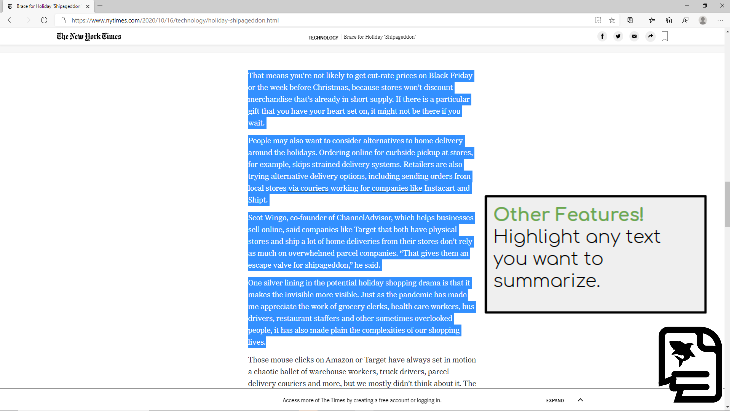
-We've created a Chrome extension that allows you to add a page summary to the top of any webpage. You can click on the icon of the extension and hit the button that appears, or summarize just a part of the text by highlighting it and right clicking it and choosing the summarize button.
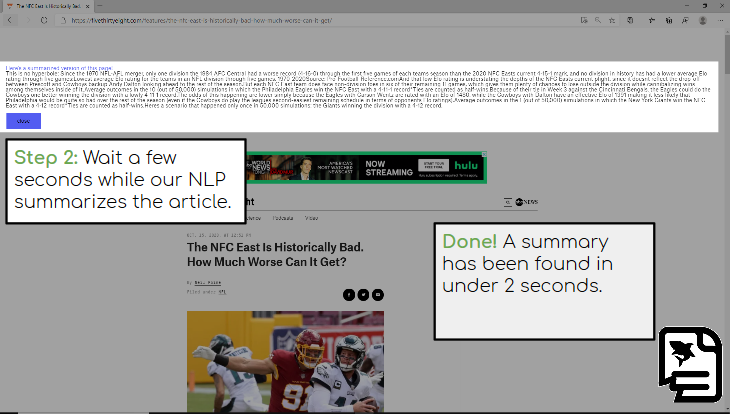
-This is done using proven Natural Language Processing (NLP) techniques and nltk to summarize text down from its original size to a maximum of log(number of sentences in original document) sentence long summary. We've added implementations of the luhn, textrank, and LSA text summarization algorithms.
-The whole backend is controlled by an Azure Cloud Function that takes in the webpage's contents whenever the extension is used and processes and returns the summary.
How we built it
-Built as an add-on for Chromium-based browsers using JavaScript
-Python-based Azure Cloud Functions to host an API for our add-on to summarize text
-We created an implementation of TextRank, which uses a similarity matrix to find similar sentences from which to create summaries, as repeated content is more likely to be important or related to the article's topic. However, our implementation ended up being noticeably slow, reducing usability.

-So, we looked into Luhn, LSA, and a more efficient implementation of TextRank. Exploring ML-adjacent technology was all new for us, but we found considerable speed increases by looking into these popular NLP approaches. We allow the selection of different models by changing the Azure Function-based API we call. By default, we use the smarter approach to TextRank.
Challenges we ran into
-Having to use vanilla Javascript was really difficult for those of us used to frameworks like Node and React
-We dealt with a lot of issues with text still having HTML tags and not being UTF-8 encoded, leading to buggy summaries
-Choosing the best NLP models for text summarization from the ones that sumy and nltk offer
-Both of Alan’s computers are broken :((((((
Accomplishments that we're proud of
-The NLP text summarization is working really well. It has a decent success rate and seems to work on the sites we tested it on
-App is fully functional and could be polished and deployed in a matter of days
-UI is clean, simple, and effective
What we learned
-Just how much filler there is in a lot of articles! And how hideously long bills and terms of service can be
-How to make a Chromium web-browser add-on
-How to use vanilla Javascript more effectively
-The power and utiltiy of Azure Cloud Functions
What's next for Sumex
-Tweak and tune NLP even further for better results. We can do this by taking into account the context/topic of the website (abstractive) rather than our current extractive approaches.
-Port to Firefox and Opera
-Further user customization
-Better custom handling for popular sites
-Better filtering of erroneous text
Built With
- azure
- azure-cloud-functions
- beautiful-soup
- chrome
- html
- javascript
- nltk
- python







Log in or sign up for Devpost to join the conversation.