-
-
tech stack summarised
sum.ly – Hack&Roll-2021
Submission for NUS Hack&Roll 2021 by Rish, Abhi, and Barnett.
![]()
Inspiration
Let's be honest -- we've all had to sit through boring online lectures and seminars at some point in our lives. We're talking about the fillers, silence, and other unwanted disturbances -- like the Professor who talks about their love for gardening during a Data Structures lecture -- in long videos that we'd obviously skip through using arrow keys.
What if we told you there's an AI-powered tool that does all this for you while ensuring you digest the important content that matters?
Say a good-old NUS Hackers "Hello" :wave: to sum.ly.
What it does
sum.ly uses Natural Language Processing and traditional Machine Learning to extract parts of long videos that matter and make the most sense in context (a semantic video summary, of sorts). The platform takes in a video URL, downloads it in the backend, performs text and audio cleaning, runs ML inference on this processed data, and delivers the important parts of the video back with a heatmap. Oooh, we also allow you to clarifiy doubts along the way.
How we built it
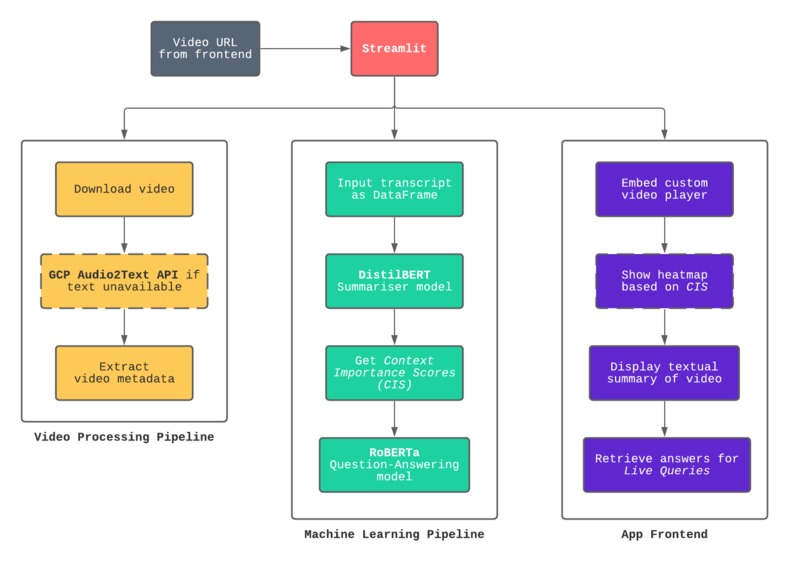
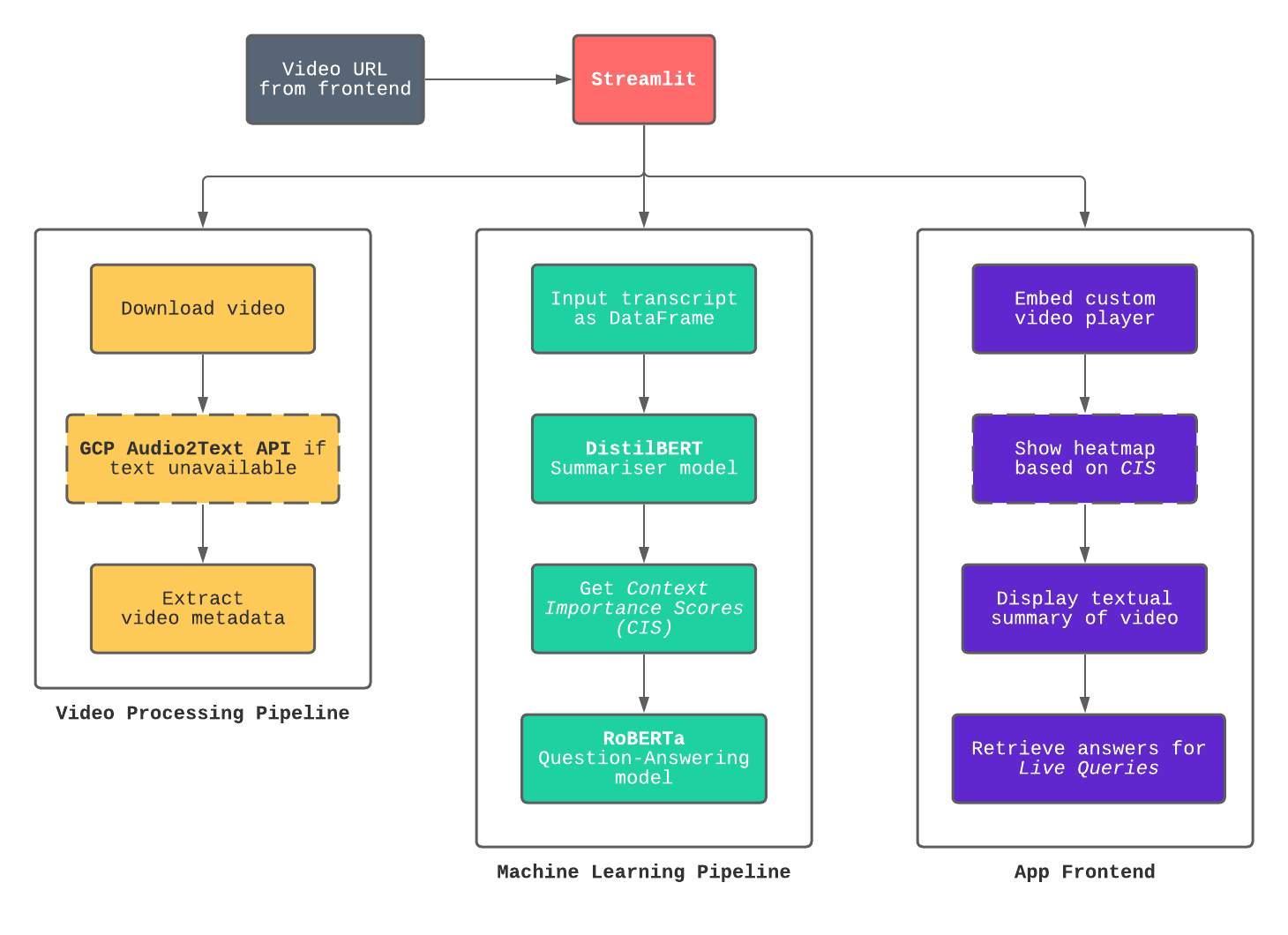
Our backend and frontend is orchestrated simultaneously using Streamlit, an open-source library for data apps.
The backend forms the bulk of the entire application – we perform video processing and Machine Learning inference on the preprocessed audio-visual data. After downloading the video, we either use a provided auto-generated transcript or use Google Cloud Platform's Web Speech API to get a transcript. We pass this through text cleaning pipelines before feeding them into the pre-trained and fine-tuned PyTorch DistilBERT Extractive Summarisation model and RoBERTa Question-Answering model.
The frontend runs custom React components for video manipulation. All this processed data and predictions are sent to the frontend for display and visualisation. We also launched a feature, Live Queries, that allows users to clarify doubts from the video's raw content immediately -- what they'd naturally do if they attended said talk live.
The following diagram presents a high-level overview of our system design and various tech stack components.
Challenges we ran into
FRONTEND Streamlit, our primary data visualisation tool, has issues when caching models, predictions, and general page activity. We had to find hacky methods to ensure low latency, near real-time inference, and smooth user experience.
BACKEND Our summarisation model is rather huge in size (1.4GB) and we faced difficulties caching it and deploying it on Google Cloud Platform's Cloud Run service. This was also the case for our question-answering model. We managed to leverage our contacts to get GCP Credits to upgrade our hardware to cutting-edge cloud GPUs.
MISC Anything that says it's "pretty" (cough, Pretty Printing, cough) will always get you into trouble. Trust us, we learned the hard way.
Accomplishments that we're proud of
- Even though we promise to work on LONNNNGGG (>1 hour) videos, we were able to chop down processing to a mere 15 seconds.
- Text processing was a mean feat that we manged to get right during the wee hours of the morning.
- Fine-tuning and hosting two very large ML models also took the bulk of our time but we were able to see it through.
- Caching the predictions, text, and models allowed us to improve performance by a large margin without compromising on speed and quality.
- We managed to run the entire app on macbooks with negative RAM :P
What we learned
As our team comprised of ML and frontend people, we walked in believing this hack would be simple. We ran into many unexpected issues -- more like annoying hiccups -- during development. We've learned to better manage expectations during a high-stakes environment like hackathons. We've also learned how to weave the frontend and backend together using a single library (ie. Streamlit).
There were many moving parts in this hack; bringing them together and integrating them to form a complete service was a fulfilling ride.
What's next for sum.ly
- Chrome Extension -- Imagine the power of AI-based semantic video summarisation in your browsers!
- Multi-platform flexibility -- Image this on LumiNUS!!! For now, we can only process videos from YouTube and MIT OpenCourseWare.
- Optimisation -- Faster, lighter ML models will improve latency and inference timings
- Distributed processing -- running inference simultaneously for extremely high performance
Built With
- gcp-web-speech-api
- google-cloud
- google-web-speech-api
- machine-learning
- natural-language-processing
- python
- react
- streamlit
")










Log in or sign up for Devpost to join the conversation.